不懂代碼也能爬取數(shù)據(jù)?試試這幾個(gè)工具
題圖:by watercolor.illustrations from instagram
前天,有個(gè)同學(xué)加我微信來(lái)咨詢我:
“猴哥,我想抓取近期 5000 條新聞數(shù)據(jù),但我是文科生,不會(huì)寫代碼,請(qǐng)問該怎么辦?”
猴哥有問必答,對(duì)于這位同學(xué)的問題,我給安排上。
先說(shuō)說(shuō)獲取數(shù)據(jù)的方式:一是利用現(xiàn)成的工具,我們只需懂得如何使用工具就能獲取數(shù)據(jù),不需要關(guān)心工具是怎么實(shí)現(xiàn)。打個(gè)比方,假如我們?cè)诎渡希ズI夏硞€(gè)小島,岸邊有一艘船,我們第一想法是選擇坐船過去,而不會(huì)想著自己來(lái)造一艘船再過去。
第二種是自己針對(duì)場(chǎng)景需求做些定制化工具,這就需要有點(diǎn)編程基礎(chǔ)。舉個(gè)例子,我們還是要到海上某個(gè)小島,同時(shí)還要求在 30 分鐘內(nèi)將 1 頓貨物送到島上。
因此,前期只是單純想獲取數(shù)據(jù),沒有什么其他要求的話,優(yōu)先選擇現(xiàn)有工具。
可能是 Python 近來(lái)年很火,加上我們會(huì)經(jīng)常看到別人用 Python 來(lái)制作網(wǎng)絡(luò)爬蟲抓取數(shù)據(jù)。從而有一些同學(xué)有這樣的誤區(qū),想從網(wǎng)絡(luò)上抓取數(shù)據(jù)就一定要學(xué) Python,一定要去寫代碼。
其實(shí)不然,猴哥介紹幾個(gè)能快速獲取網(wǎng)上數(shù)據(jù)的工具。
1.Microsoft Excel
你沒有看錯(cuò),就是 Office 三劍客之一的 Excel。Excel 是一個(gè)強(qiáng)大的工具,能抓取數(shù)據(jù)就是它的功能之一。我以耳機(jī)作為關(guān)鍵字,抓取京東的商品列表。
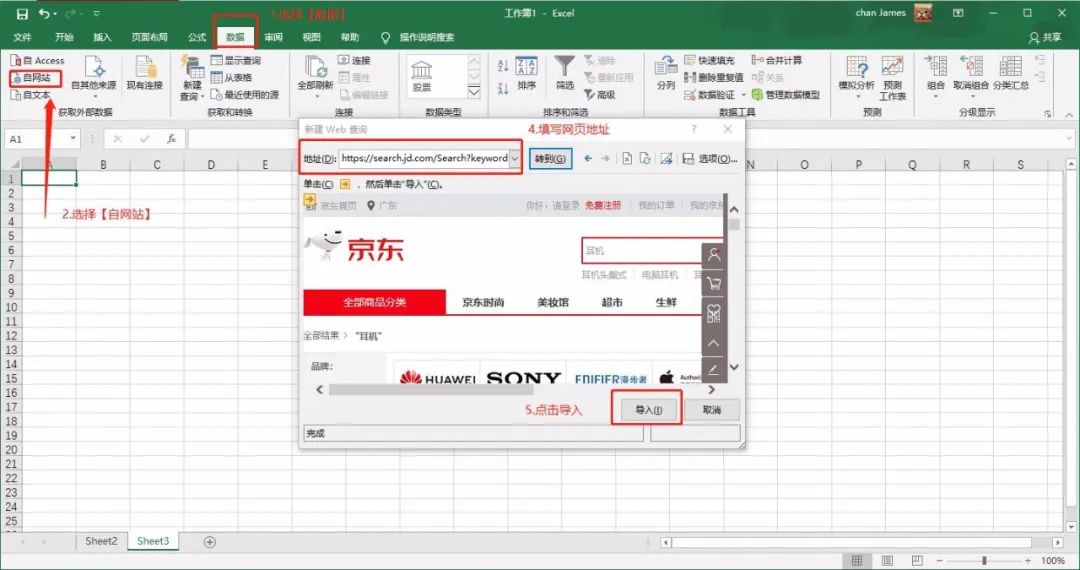
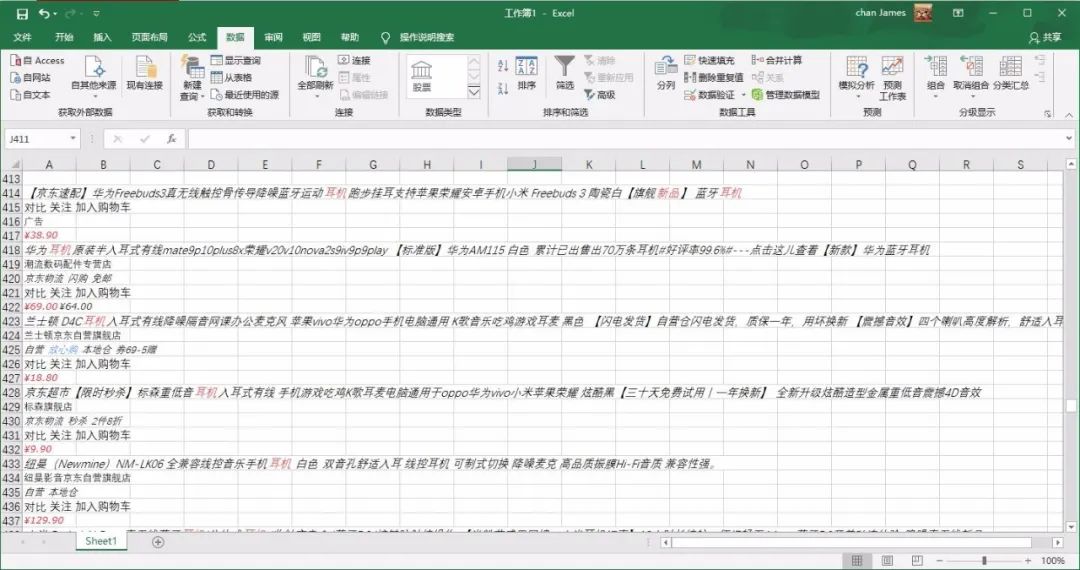
等待幾秒后,Excel 會(huì)將頁(yè)面上所有的文字信息抓取到表格中。這種方式確實(shí)能抓取到數(shù)據(jù),但也會(huì)引入一些我們不需要的數(shù)據(jù)。如果你有更高的需求,可以選擇后面幾個(gè)工具。
2.火車頭采集器

火車頭是爬蟲界的老品牌了,是目前使用人數(shù)最多的互聯(lián)網(wǎng)數(shù)據(jù)抓取、處理、分析,挖掘軟件。它的優(yōu)勢(shì)是采集不限網(wǎng)頁(yè),不限內(nèi)容,同時(shí)還是分布式采集,效率會(huì)高一些。缺點(diǎn)是對(duì)小白用戶不是很友好,有一定的知識(shí)門檻(了解如網(wǎng)頁(yè)知識(shí)、HTTP 協(xié)議等方面知識(shí)),還需要花些時(shí)間熟悉工具操作。
因?yàn)橛袑W(xué)習(xí)門檻,掌握該工具之后,采集數(shù)據(jù)上限會(huì)很高。有時(shí)間和精力的同學(xué)可以去折騰折騰。
官網(wǎng)地址:http://www.locoy.com/
3.八爪魚采集器

八爪魚采集器是一款非常適合新手的采集器。它具有簡(jiǎn)單易用的特點(diǎn),讓你能幾分鐘中就快手上手。八爪魚提供一些常見抓取網(wǎng)站的模板,使用模板就能快速抓取數(shù)據(jù)。如果想抓取沒有模板的網(wǎng)站,官網(wǎng)也提供非常詳細(xì)的圖文教程和視頻教程。
八爪魚是基于瀏覽器內(nèi)核實(shí)現(xiàn)可視化抓取數(shù)據(jù),所以存在卡頓、采集數(shù)據(jù)慢的特點(diǎn)。但這瑕不掩瑜,能基本滿足新手在短時(shí)間抓取數(shù)據(jù)的場(chǎng)景,比如翻頁(yè)查詢,Ajax 動(dòng)態(tài)加載數(shù)據(jù)等。
網(wǎng)站:https://www.bazhuayu.com/
4.GooSeeker 集搜客

集搜客也是一款容易上手的可視化采集數(shù)據(jù)工具。同樣能抓取動(dòng)態(tài)網(wǎng)頁(yè),也支持可以抓取手機(jī)網(wǎng)站上的數(shù)據(jù),還支持抓取在指數(shù)圖表上懸浮顯示的數(shù)據(jù)。集搜客是以瀏覽器插件形式抓取數(shù)據(jù)。雖然具有前面所述的有點(diǎn),但缺點(diǎn)也有,無(wú)法多線程采集數(shù)據(jù),出現(xiàn)瀏覽器卡頓也在所難免。
網(wǎng)站:https://www.gooseeker.com/
5.Scrapinghub

如果你想抓取國(guó)外的網(wǎng)站數(shù)據(jù),可以考慮 Scrapinghub。Scrapinghub 是一個(gè)基于Python 的 Scrapy 框架的云爬蟲平臺(tái)。Scrapehub 算是市場(chǎng)上非常復(fù)雜和強(qiáng)大的網(wǎng)絡(luò)抓取平臺(tái),提供數(shù)據(jù)抓取的解決方案商。
地址:https://scrapinghub.com/
6.WebScraper

WebScraper 是一款優(yōu)秀國(guó)外的瀏覽器插件。同樣也是一款適合新手抓取數(shù)據(jù)的可視化工具。我們通過簡(jiǎn)單設(shè)置一些抓取規(guī)則,剩下的就交給瀏覽器去工作。
地址:https://webscraper.io/