













如何為數據科學家提供無需復雜ETL的數據分析
數據科學家和數據分析師經常需要回答業務問題。這可能會導致更臨時的分析或某種形式的模型將被應用到公司的工作流程中。
但是要執行數據科學和分析,團隊首先需要訪問來自多個應用程序和業務流程的高質量數據。這意味著將數據從點a移動到點b。執行此操作的一般方法是使用自動化過程,簡稱為提取,轉換和加載或ETL。這些ETL通常會將數據加載到某種形式的數據倉庫中,以便于訪問。但是,ETL和數據倉庫存在一個主要問題。
盡管有必要,但ETL需要大量的編碼,專門知識和維護。除了這項工作對于數據科學家來說是耗時的之外,并不是所有的數據科學家都具有開發ETL的經驗。很多時候,這項工作將落在數據工程團隊上,這些團隊忙于更大的圖片項目以引入基礎數據層。
這并不總是與數據科學家的需求保持一致,數據科學家的需求可能會讓擁有業務所有者的企業希望快速地進行信息和分析。等到數據工程團隊有時間提取新的數據源可能不是一個好選擇。
這就是為什么在過去的幾年中開發了幾種解決方案來減少數據科學家為獲取所需數據而需要進行的工作量的原因。尤其是以數據虛擬化,自動ETL和無代碼/低代碼解決方案的形式。
自動化的ETL和數據倉庫
盡管ETL本身是一個自動化過程。他們需要大量的手動開發和維護。
這導致了Panoply之類的工具的普及,該工具提供了易于集成的自動ETL和云數據倉庫,可以與許多第三方工具(如Salesforce,Google Analytics和數據庫)同步。使用這些自動集成,數據科學家可以快速分析數據,而無需部署復雜的基礎架構。
無需Python或EC2實例。只需單擊幾下。然后,在大致了解您打算引入團隊中的數據類型之后,便可以擁有一個填充的數據倉庫。
這些自動化的ETL系統非常易于使用,通常只需要最終用戶設置數據源和目標即可。從那里可以將ETL設置為在特定時間運行。全部沒有任何代碼。
產品實例:
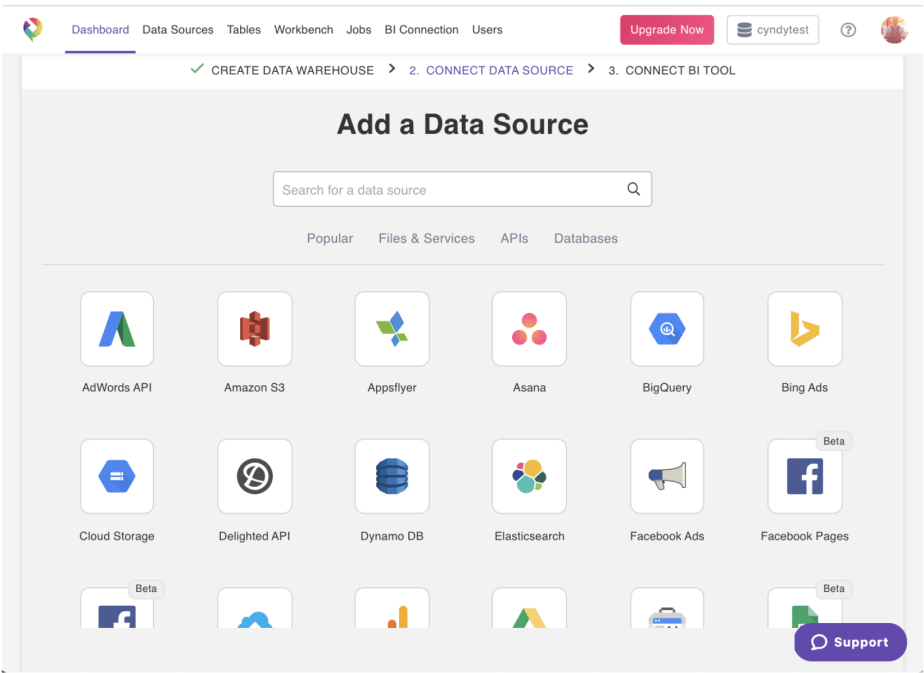
> Image provided by the author.
如前所述,Panoply是自動ETL和數據倉庫的一個示例。
可以在Panoply GUI中設置整個攝取,您可以在其中選擇源和目的地并自動攝取數據。因為Panoply帶有內置的數據倉庫,所以它會自動存儲數據的副本,可以使用任何所需的BI或分析工具來查詢數據的副本,而不必擔心會危害操作或生產。以這種方式訪問數據基礎結構對于希望使事情簡單但仍可以訪問整個組織中幾乎實時數據的用戶來說是有意義的。
反過來,這使數據科學家能夠回答臨時問題,而無需等待BI團隊將其帶入數據倉庫的四個星期。
優點:
- 易于學習和實施
- 專注于云
- 易于擴展
缺點:
- 自動化的數據倉庫和ETL本身無法管理復雜的邏輯
- 更復雜的轉換可能需要添加無代碼/低代碼ETL工具
無代碼/低代碼
無代碼/低代碼距離自動ETL幾步之遙。這些類型的ETL工具具有更多的拖放方法。這意味著可以拖放一些設置轉換和數據操作功能。其他類似的解決方案可能更多是基于GUI的,它允許用戶指定源,目的地和轉換。此外,這些無代碼/低代碼解決方案中的許多解決方案都允許最終用戶查看是否需要編碼并對其進行編輯。
對于沒有代碼經驗的用戶,這是一個很好的解決方案。無代碼/低代碼數據,科學家就可以開發語法有限的ETL,從而創建一些相當復雜的數據管道。無需建立大量復雜的基礎架構來管理數據管道何時運行以及它們所依賴的內容。用戶只需要從高層次上了解他們的數據在哪里,他們想去哪里以及什么時候要去那里。
缺點:
- 代碼中的可定制性有限
- 每個工具都不相同,因此開發人員必須在下一份工作中重新學習ETL
- 無代碼/低代碼可能太容易了,并導致糟糕的高級設計
優點:
- 技術上沒有編碼經驗
- 易于集成到許多受歡迎的第三方
- 許多是基于云的解決方案
產品實例:
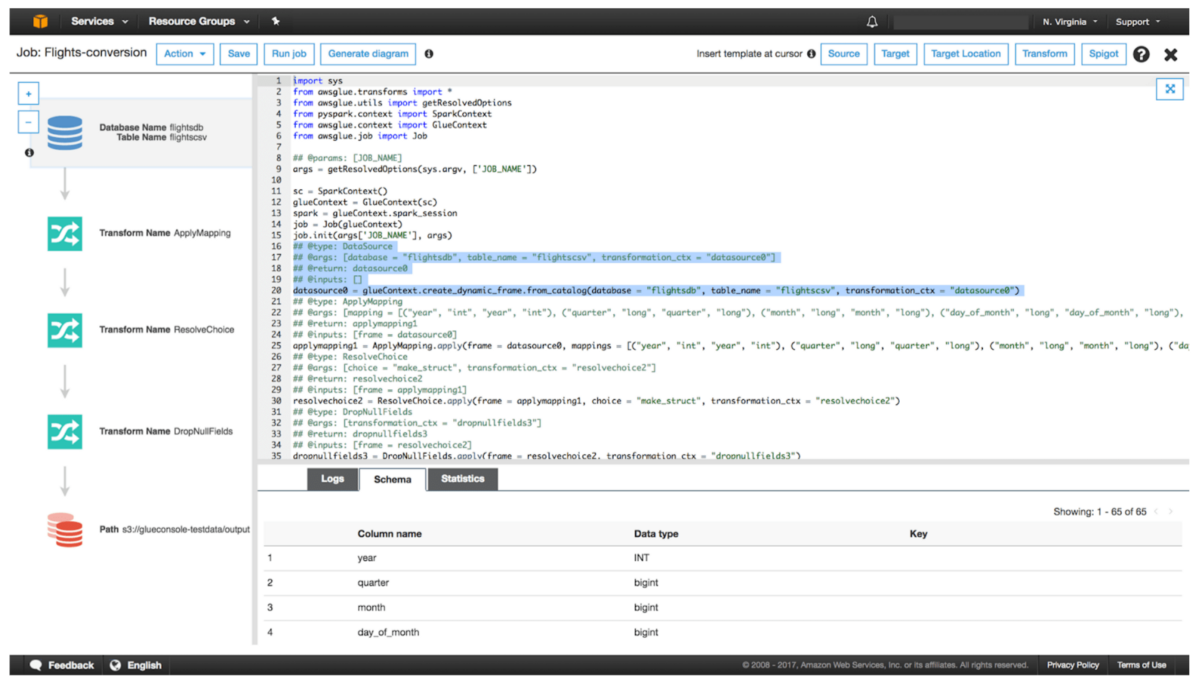
> Image source: aws.amazon.com
此類別中有很多產品。有類似AWS Glue,Stitch和FiveTran的產品。
AWS Glue是基于云的現代ETL解決方案的一個很好的例子。這使開發人員只需單擊幾下即可設置作業,并設置參數。這可以使數據科學家無需太多代碼即可移動和轉換數據。
作為AWS一部分的Glue可以輕松地與其他服務集成,例如S3,RDS和Redshift。這使得在AWS上開發數據管道變得非常容易和直觀。但是,AWS Glue有一個主要警告。與許多其他無代碼/低代碼選項不同,它是為在AWS上運行而開發的。這意味著,如果您突然決定切換到其他云提供商,則可能僅從Glue切換到其他解決方案就不得不花費大量時間和金錢。
最后,這是您的團隊在開發ETL之前應考慮的重要考慮因素。
數據虛擬化
數據虛擬化是一種允許用戶訪問來自多個數據源,數據結構和第三方提供程序的數據的方法。它實質上創建了一個單層,無論使用哪種技術存儲底層數據,最終用戶都將可以通過單點訪問它。
總體而言,當您的團隊需要快速訪問數據時,數據虛擬化具有許多優勢。以下是一些數據虛擬化如何使您的團隊受益的示例。
優點:
- 允許數據科學家混合來自多個數據庫的數據
- 管理安全性和訪問管理
- 實時或近實時數據
缺點:
- 高學習曲線
- 需要管理員來管理
- 仍然需要用戶考慮設計和數據流
產品實例:
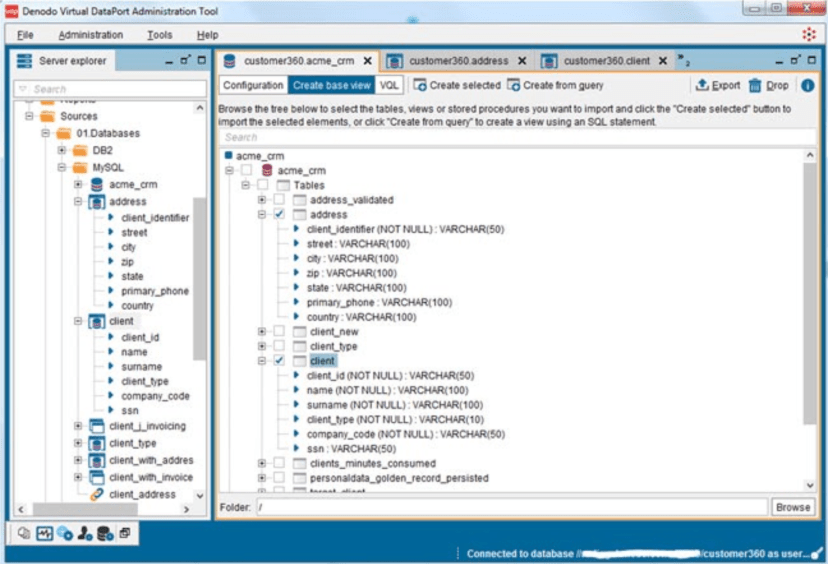
> Image provided by the author.
Denodo是最著名的數據虛擬化提供商之一。總體而言,該產品可以說是最成熟,功能最豐富的產品。
Denodo致力于幫助用戶從本質上通過一項服務訪問其數據,這使得它受到眾多客戶的歡迎。從醫療保健提供者到金融行業,都依賴Denodo來減輕BI開發人員和數據科學家的壓力,因為它減少了創建盡可能多的數據倉庫的必要性。
總體而言,這三個選項可以幫助您的團隊分析數據,而無需花費很多精力來開發復雜的ETL。
結論
對于數據科學家和機器學習工程師而言,管理,混合和移動數據將繼續是一項必不可少的任務。但是,開發這些管道及其相應的數據倉庫的過程無需像過去那樣花費很長時間。
通過自動集成系統或通過其他方法(例如無代碼/低代碼和數據虛擬化)來開發ETL,有很多不錯的選擇。如果您的團隊希望減少數據工程師的工作量,則有很多選擇。您的團隊可能還需要組建一支新的數據科學團隊,該團隊需要立即將數據反饋給他們,然后使用Panoply之類的解決方案可能是個不錯的選擇。













