清華「計圖」大更新:支持可微渲染,多任務速度超PyTorch
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
想研究可微分渲染,卻擔心找不到合適的框架?
現在,世界上首個官方支持可微分渲染的深度學習框架來了:
清華自研的「計圖」 (Jittor)深度學習框架,在更新的版本中加入了可微分渲染庫。

可微分渲染是計算機圖形學的熱門領域,CVPR 2020的最佳論文獎,就頒給了可微分渲染的相關工作(Jittor已優化開源相關代碼)。
當然,作為一個主打計算機圖形學的深度學習框架,Jittor的這次更新也“緊隨潮流”,加入了最新的Vision Transformer等模塊,性能優化上較之PyTorch等框架優秀不少。
一起來看看。
可微分渲染,圖像重建利器
渲染究竟是什么?
簡單來說,「渲染」通常是指將3D場景,轉變為2D圖像的過程。

對于人眼來說,這種事情非常容易,因為現實世界中存在大量自然光線,人眼通過光線反射,能看清物體各個方位的深度、形狀。
但計算機眼里的3D場景,并沒有現實世界中各種各樣的光線,這種情況下生成的2D圖像不僅沒有參數,形狀也容易出錯。那么,直接在計算機中模擬四面八方來的所有光線?
計算量太大。
所以,為了讓計算機生成圖像效果更好,即更快、更逼真地生成接近于人眼看到的2D圖像,「渲染」目前是圖形學重要的研究領域,通常被用于如制作動畫電影等方向:
那么,可微分渲染呢?
這有點像是「渲染」的“反向操作”,從2D圖像中,生成所需的3D場景信息,包括3D幾何、燈光、材質、視角等等。

在用深度學習生成3D場景的過程中,同樣需要進行梯度下降優化算法,這其中,就會用到可微分渲染。
目前在圖像領域中,可微分渲染仍然是非常新穎的一個方向,但相比之下,此前還沒有深度學習框架設立一個相關的庫,便于進行可微分渲染的相關工作。
清華「計圖」,自發布實例分割模型庫和3D點云模型庫后,目前正式發布可微分渲染庫,支持obj的加載和保存、三角網格模型渲染。
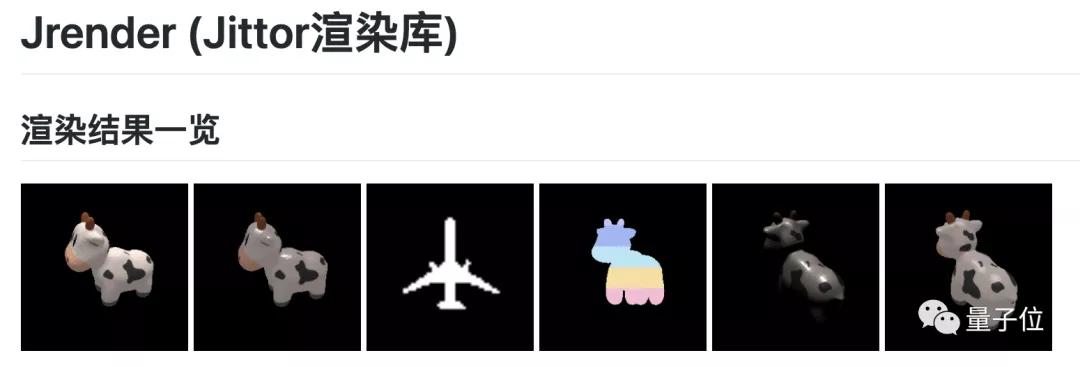
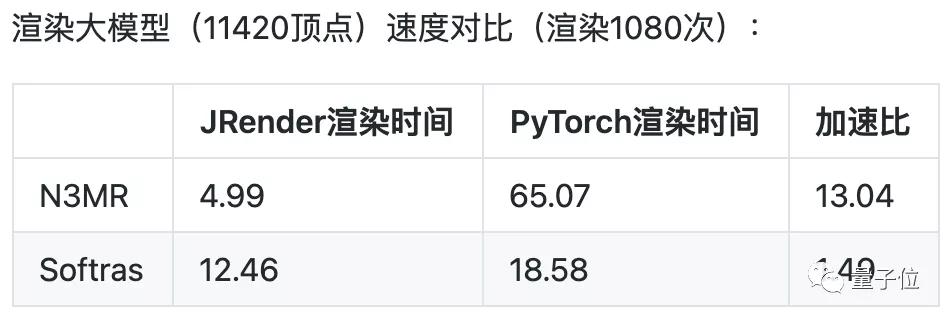
除此之外,這一可微分渲染庫內置2種主流可微渲染器,支持多種材質渲染,相比于PyTorch,速度提升了1.49~13.04倍。
當然,這次「計圖」的更新,帶來的驚喜不止這些。
視覺玩家福音:訓練速度較PyTorch更快
繼在NLP領域取得最優性能后,Transformer又進入了圖像領域,目前Vision Transformer也已經在視覺分類上取得了最佳效果。
有關Vision Transformer,目前「計圖」已經實現了復現,訓練速度相比于PyTorch還要快上20%。

同時,這次更新還帶上了YOLOv3的加速和復現,訓練速度相較于PyTorch提升11%。
原來在Jittor上可以運行的MobileNet,這次的訓練和推理速度也得到了全面提升,在不同的圖像及batchsize大小上,速度提升從10%~50%不等。
簡直是視覺分類玩家的福音。
搞圖形學,選哪個深度學習框架?
就傳統的幾大主流框架而言,相比于Caffe的速度,Tensorflow和PyTorch更側重于“容易上手”。
這里面相較于Tensorflow,PyTorch搭建在更高層,雖然上手更友好,但訓練速度也會因此更慢。
此外,這些深度學習框架并非像「計圖」一樣,完全針對于圖形學領域,因此無論是渲染、還是圖形處理等方向,并不能做到每個新領域都及時地跟進。
Caffe作者賈揚清也曾在知乎表示,「計圖」更關注計算圖優化及JIT(實時)編譯。
也就是說,在訓練速度、上手友好度方向,「計圖」都是要優于PyTorch的,而接口仿PyTorch,也是為了讓大家能更快適應新的框架。
那么,這次的可微渲染庫,與胡淵鳴的Taichi渲染工具相比怎么樣呢?
據開發者之一梁盾介紹,二者整體來說屬于不同的領域。
Taichi做的是類似下圖的可微物理模擬,而Jittor這次加入的則是可微渲染庫。
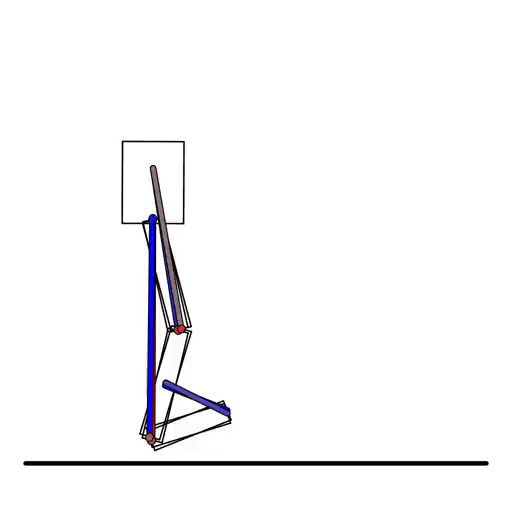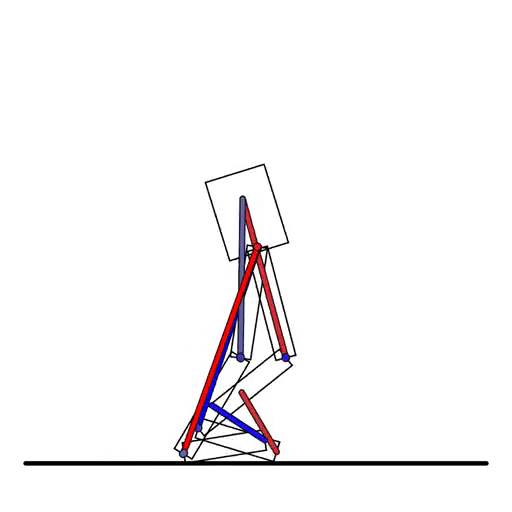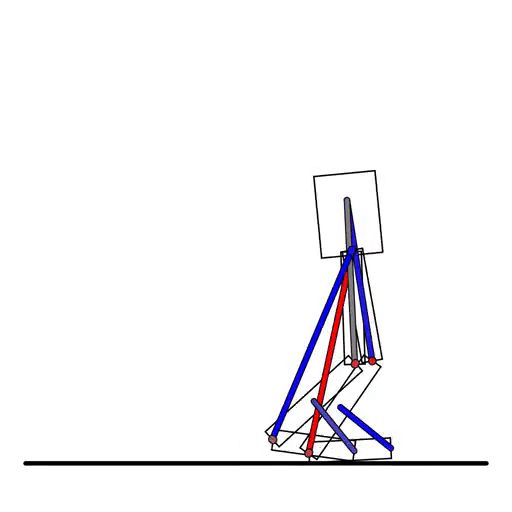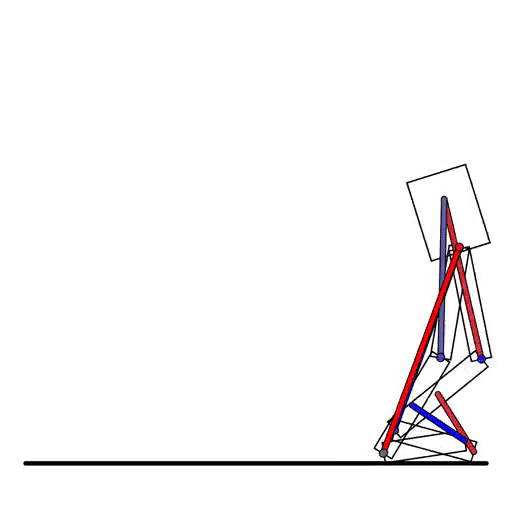
但就渲染領域來看,Taichi并沒有可微分渲染部分,主要也是通過物理模擬光線的折射,來完成簡單的渲染工作。
也就是說,渲染是完成三維模型和圖像之間的變換,而物理模擬,則是完成三維模型和作用力之間的變化。


如果想要系統地上手CV,「計圖」會是一個不錯的深度學習框架。
作者介紹
「計圖」的開發團隊,均來自清華大學計算機系圖形學實驗室,負責人是清華大學計算機系的胡事民教授。
而主要負責開發的,則是來自實驗室的博士生們:梁盾、楊國燁、楊國煒、周文洋……
梁盾認為,這次「計圖」的升級,兼具創新、前瞻性,而且可微分渲染也是逐漸火熱的研究領域。
而針對Vision transformer的訓練,速度也比許多國際主流平臺要快。
心動的同學,可以更新/安裝起「計圖」來了~
Jittor項目地址:
https://github.com/Jittor/jittor