還在用ELK?是時候了解一下輕量化日志服務Loki了
圖片來自 Pexels
本文基于我們對 Loki 的使用和理解,從它產生的背景、解決的問題、采用的方案、系統架構、實現邏輯等做一些剖析,希望對關注 Loki 的小伙伴們提供一些幫助。
在日常的系統可視化監控過程中,當監控探知到指標異常時,我們往往需要對問題的根因做出定位。
但監控數據所暴露的信息是提前預設、高度提煉的,在信息量上存在著很大的不足,它需要結合能夠承載豐富信息的日志系統一起使用。
當監控系統探知到異常告警,我們通常在 Dashboard 上根據異常指標所屬的集群、主機、實例、應用、時間等信息圈定問題的大致方向,然后跳轉到日志系統做更精細的查詢,獲取更豐富的信息來最終判斷問題根因。
在如上流程中,監控系統和日志系統往往是獨立的,使用方式具有很大差異。比如監控系統 Prometheus 比較受歡迎,日志系統多采用 ES+Kibana 。
他們具有完全不同的概念、不同的搜索語法和界面,這不僅給使用者增加了學習成本,也使得在使用時需在兩套系統中頻繁做上下文切換,對問題的定位遲滯。
此外,日志系統多采用全文索引來支撐搜索服務,它需要為日志的原文建立反向索引,這會導致最終存儲數據相較原始內容成倍增長,產生不可小覷的存儲成本。
并且,不管數據將來是否會被搜索,都會在寫入時因為索引操作而占用大量的計算資源,這對于日志這種寫多讀少的服務無疑也是一種計算資源的浪費。
Loki 則是為了應對上述問題而產生的解決方案,它的目標是打造能夠與監控深度集成、成本極度低廉的日志系統。
Loki 日志方案
低使用成本
①數據模型
在數據模型上,Loki 參考了 Prometheus ,數據由標簽、時間戳、內容組成,所有標簽相同的數據屬于同一日志流:
- 標簽,描述日志所屬集群、服務、主機、應用、類型等元信息, 用于后期搜索服務。
- 時間戳,日志的產生時間。
- 內容,日志的原始內容。
具有如下結構:
- {
- "stream": {
- "label1": "value1",
- "label1": "value2"
- }, # 標簽
- "values": [
- ["<timestamp nanoseconds>","log content"], # 時間戳,內容
- ["<timestamp nanoseconds>","log content"]
- ]
- }
Loki 還支持多租戶,同一租戶下具有完全相同標簽的日志所組成的集合稱為一個日志流。
在日志的采集端使用和監控時序數據一致的標簽,這樣在可以后續與監控系統結合時使用相同的標簽,也為在 UI 界面中與監控結合使用做快速上下文切換提供數據基礎。
LogQL:Loki 使用類似 Prometheus 的 PromQL 的查詢語句 logQL ,語法簡單并貼近社區使用習慣,降低用戶學習和使用成本。
語法例子如下:
- {file="debug.log""} |= "err"
流選擇器:{label1="value1", label2="value2"}, 通過標簽選擇日志流, 支持等、不等、匹配、不匹配等選擇方式。過濾器:|= "err",過濾日志內容,支持包含、不包含、匹配、不匹配等過濾方式。
這種工作方式類似于 find+grep,find 找出文件,grep 從文件中逐行匹配:
- find . -name "debug.log" | grep err
logQL 除支持日志內容查詢外,還支持對日志總量、頻率等聚合計算。
Grafana:在 Grafana 中原生支持 Loki 插件,將監控和日志查詢集成在一起,在同一 UI 界面中可以對監控數據和日志進行 side-by-side 的下鉆查詢探索,比使用不同系統反復進行切換更直觀、更便捷。
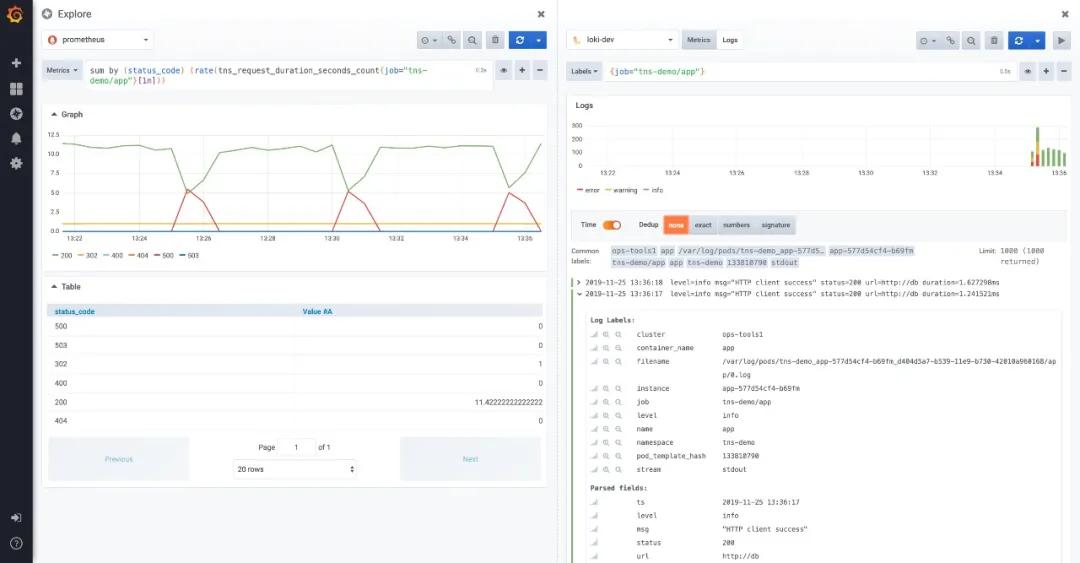
此外,在 Dashboard 中可以將監控和日志查詢配置在一起,這樣可同時查看監控數據走勢和日志內容,為捕捉可能存在的問題提供更直觀的途徑。
低存儲成本
只索引與日志相關的元數據標簽,而日志內容則以壓縮方式存儲于對象存儲中, 不做任何索引。
相較于 ES 這種全文索引的系統,數據可在十倍量級上降低,加上使用對象存儲,最終存儲成本可降低數十倍甚至更低。
方案不解決復雜的存儲系統問題,而是直接應用現有成熟的分布式存儲系統,比如 S3、GCS、Cassandra、BigTable 。
Loki 架構
整體上 Loki 采用了讀寫分離的架構,由多個模塊組成:
- Promtail、Fluent-bit、Fluentd、Rsyslog 等開源客戶端負責采集并上報日志。
- Distributor:日志寫入入口,將數據轉發到 Ingester。
- Ingester:日志的寫入服務,緩存并寫入日志內容和索引到底層存儲。
- Querier:日志讀取服務,執行搜索請求。
- QueryFrontend:日志讀取入口,分發讀取請求到 Querier 并返回結果。
- Cassandra/BigTable/DnyamoDB/S3/GCS:索引、日志內容底層存儲。
- Cache:緩存,支持 Redis/Memcache/本地 Cache。
其主體結構如下圖所示:
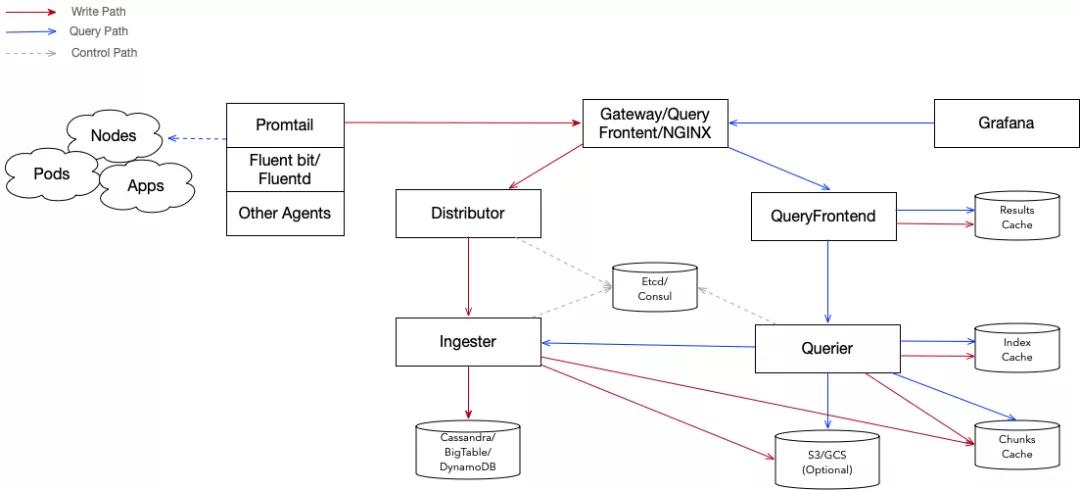
Distributor:作為日志寫入的入口服務,其負責對上報數據進行解析、校驗與轉發。
它將接收到的上報數解析完成后會進行大小、條目、頻率、標簽、租戶等參數校驗,然后將合法數據轉發到 Ingester 服務,其在轉發之前最重要的任務是確保同一日志流的數據必須轉發到相同 Ingester 上,以確保數據的順序性。
Hash 環:Distributor 采用一致性哈希與副本因子相結合的辦法來決定數據轉發到哪些 Ingester 上。
Ingester 在啟動后,會生成一系列的 32 位隨機數作為自己的 Token ,然后與這一組 Token 一起將自己注冊到 Hash 環中。
在選擇數據轉發目的地時,Distributor 根據日志的標簽和租戶 ID 生成 Hash,然后在 Hash 環中按 Token 的升序查找第一個大于這個 Hash 的 Token ,這個 Token 所對應的 Ingester 即為這條日志需要轉發的目的地。
如果設置了副本因子,順序的在之后的 Token 中查找不同的 Ingester 做為副本的目的地。
Hash 環可存儲于 etcd、consul 中。另外 Loki 使用 Memberlist 實現了集群內部的 KV 存儲,如不想依賴 etcd 或 consul ,可采用此方案。
輸入輸出:Distributor 的輸入主要是以 HTTP 協議批量的方式接受上報日志,日志封裝格式支持 JSON 和 PB ,數據封裝結構:
- [
- {
- "stream": {
- "label1": "value1",
- "label1": "value2"
- },
- "values": [
- ["<timestamp nanoseconds>","log content"],
- ["<timestamp nanoseconds>","log content"]
- ]
- },
- ......
- ]
Distributor 以 grpc 方式向 ingester 發送數據,數據封裝結構:
- {
- "streams": [
- {
- "labels": "{label1=value1, label2=value2}",
- "entries": [
- {"ts": <unix epoch in nanoseconds>, "line:":"<log line>" },
- {"ts": <unix epoch in nanoseconds>, "line:":"<log line>" },
- ]
- }
- ....
- ]
- }
①Ingester
作為 Loki 的寫入模塊,Ingester 主要任務是緩存并寫入數據到底層存儲。根據寫入數據在模塊中的生命周期,ingester 大體上分為校驗、緩存、存儲適配三層結構。
②校驗
Loki 有個重要的特性是它不整理數據亂序,要求同一日志流的數據必須嚴格遵守時間戳單調遞增順序寫入。
所以除對數據的長度、頻率等做校驗外,至關重要的是日志順序檢查。
Ingester 對每個日志流里每一條日志都會和上一條進行時間戳和內容的對比,策略如下:
- 與上一條日志相比,本條日志時間戳更新,接收本條日志。
- 與上一條日志相比,時間戳相同內容不同,接收本條日志。
- 與上一條日志相比,時間戳和內容都相同,忽略本條日志。
- 與上一條日志相比,本條日志時間戳更老,返回亂序錯誤。
③緩存
日志在內存中的緩存采用多層樹形結構對不同租戶、日志流做出隔離。同一日志流采用順序追加方式寫入分塊:
- Instances:以租戶的 userID 為鍵 Instance 為值的 Map 結構。
- Instance:一個租戶下所有日志流(stream)的容器。
- Streams:以日志流的指紋(streamFP)為鍵,Stream 為值的 Map 結構。
- Stream:一個日志流所有 Chunk 的容器。
- Chunks:Chunk 的列表。
- Chunk:持久存儲讀寫最小單元在內存態的結構。
- Block:Chunk 的分塊,為已壓縮歸檔的數據。
- HeadBlock:尚在開放寫入的分塊。
- Entry:單條日志單元,包含時間戳(timestamp)和日志內容(line)
整體結構如下:
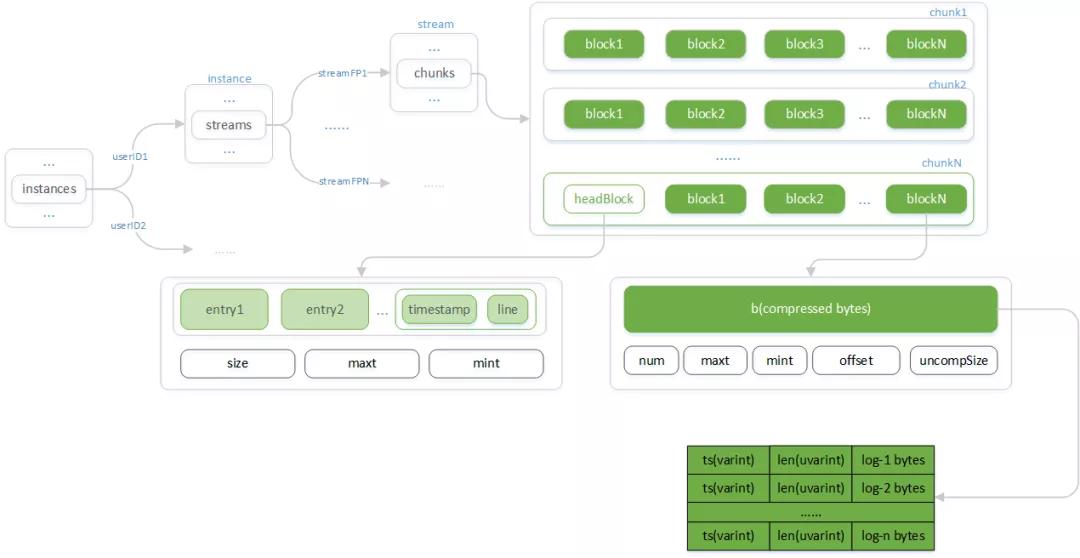
Chunks:在向內存寫入數據前,ingester 首先會根據租戶ID(userID)和由標簽計算的指紋(streamPF)定位到日志流(stream)及 Chunks。
Chunks 由按時間升序排列的 chunk 組成,最后一個 chunk 接收最新寫入的數據,其他則等刷寫到底層存儲。
當最后一個 chunk 的存活時間或數據大小超過指定閾值時,Chunks 尾部追加新的 chunk 。
Chunk:Chunk 為 Loki 在底層存儲上讀寫的最小單元在內存態下的結構。其由若干 block 組成,其中 headBlock 為正在開放寫入的 block ,而其他 Block 則已經歸檔壓縮的數據。
Block:Block 為數據的壓縮單元,目的是為了在讀取操作那里避免因為每次解壓整個 Chunk 而浪費計算資源,因為很多情況下是讀取一個 chunk 的部分數據就滿足所需數據量而返回結果了。
Block 存儲的是日志的壓縮數據,其結構為按時間順序的日志時間戳和原始內容,壓縮可采用 gzip、snappy 、lz4 等方式。
HeadBlock:正在接收寫入的特殊 block ,它在滿足一定大小后會被壓縮歸檔為 Block ,然后新 headBlock 會被創建。
存儲適配:由于底層存儲要支持 S3、Cassandra、BigTable、DnyamoDB 等系統,適配層將各種系統的讀寫操作抽象成統一接口,負責與他們進行數據交互。
④輸出
Loki 以 Chunk 為單位在存儲系統中讀寫數據。在持久存儲態下的 Chunk 具有如下結構:
- meta:封裝 chunk 所屬 stream 的指紋、租戶 ID,開始截止時間等元信息。
- data:封裝日志內容,其中一些重要字段。
- encode 保存數據的壓縮方式。
- block-N bytes 保存一個 block 的日志數據。
- #blocks section byte offset 單元記錄 #block 單元的偏移量。
- #block 單元記錄一共有多少個 block。
- #entries 和 block-N bytes 一一對應,記錄每個 block 里有日式行數、時間起始點,blokc-N bytes 的開始位置和長度等元信息。
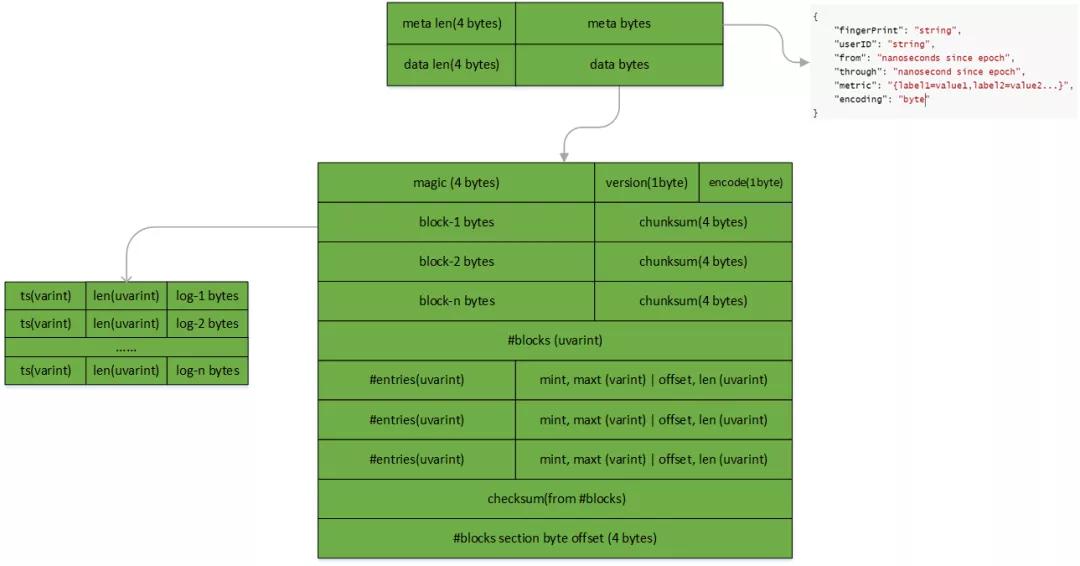
Chunk 數據的解析順序:
- 根據尾部的 #blocks section byte offset 單元得到 #block 單元的位置。
- 根據 #block 單元記錄得出 chunk 里 block 數量。
- 從 #block 單元所在位置開始讀取所有 block 的 entries、mint、maxt、offset、len 等元信息。
- 順序的根據每個 block 元信息解析出 block 的數據。
⑤索引
Loki 只索引了標簽數據,用于實現標簽→日志流→Chunk 的索引映射, 以分表形式在存儲層存儲。
表結構如下:
- CREATE TABLE IF NOT EXISTS Table_N (
- hash text,
- range blob,
- value blob,
- PRIMARY KEY (hash, range)
- )
Table_N,根據時間周期分表名;hash, 不同查詢類型時使用的索引;range,范圍查詢字段;value,日志標簽的值。
數據類型:Loki 保存了不同類型的索引數據用以實現不同映射場景,對于每種類型的映射數據,Hash/Range/Value 三個字段的數據組成如下圖所示:
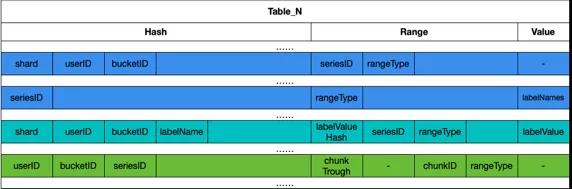
seriesID 為日志流 ID,shard 為分片,userID 為租戶 ID,labelName 為標簽名,labelValueHash 為標簽值 hash,chunkID 為 chunk 的 ID,chunkThrough 為 chunk 里最后一條數據的時間這些數據元素在映射過程中的作用在 Querier 環節的[查詢流程]((null))做詳細介紹。
上圖中三種顏色標識的索引類型從上到下分別為:
- 數據類型 1:用于根據用戶 ID 搜索查詢所有日志流的 ID。
- 數據類型 2:用于根據用戶 ID 和標簽查詢日志流的 ID。
- 數據類型 3:用于根據日志流 ID 查詢底層存儲 Chunk 的 ID。
除了采用分表外,Loki 還采用分桶、分片的方式優化索引查詢速度。
分桶:
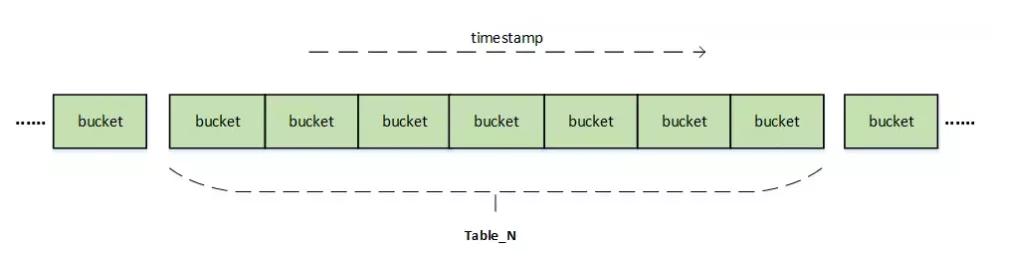
以天分割:bucketID = timestamp / secondsInDay。
以小時分割:bucketID = timestamp / secondsInHour。
分片:將不同日志流的索引分散到不同分片,shard = seriesID% 分片數。
Chunk 狀態:Chunk 作為在 Ingester 中重要的數據單元,其在內存中的生命周期內分如下四種狀態:
- Writing:正在寫入新數據。
- Waiting flush:停止寫入新數據,等待寫入到存儲。
- Retain:已經寫入存儲,等待銷毀。
- Destroy:已經銷毀。
四種狀態之間的轉換以 writing→waiting flush→retain→destroy 順序進行。
狀態轉換時機:
- 協作觸發:有新的數據寫入請求。
- 定時觸發:刷寫周期觸發將 chunk 寫入存儲,回收周期觸發將 chunk 銷毀。
writing 轉為 waiting flush:chunk 初始狀態為 writing,標識正在接受數據的寫入,滿足如下條件則進入到等待刷寫狀態:
- chunk 空間滿(協作觸發)。
- chunk 的存活時間(首末兩條數據時間差)超過閾值 (定時觸發)。
- chunk 的空閑時間(連續未寫入數據時長)超過設置 (定時觸發)。
waiting flush 轉為 etain:Ingester 會定時的將等待刷寫的 chunk 寫到底層存儲,之后這些 chunk 會處于”retain“狀態,這是因為 ingester 提供了對最新數據的搜索服務,需要在內存里保留一段時間,retain 狀態則解耦了數據的刷寫時間以及在內存中的保留時間,方便視不同選項優化內存配置。
destroy,被回收等待 GC 銷毀:總體上,Loki 由于針對日志的使用場景,采用了順序追加方式寫入,只索引元信息,極大程度上簡化了它的數據結構和處理邏輯,這也為 Ingester 能夠應對高速寫入提供了基礎。
Querier:查詢服務的執行組件,其負責從底層存儲拉取數據并按照 LogQL 語言所描述的篩選條件過濾。它可以直接通過 API 提供查詢服務,也可以與 queryFrontend 結合使用實現分布式并發查詢。
⑥查詢類型
查詢類型如下:
- 范圍日志查詢
- 單日志查詢
- 統計查詢
- 元信息查詢
在這些查詢類型中,范圍日志查詢應用最為廣泛,所以下文只對范圍日志查詢做詳細介紹。
并發查詢:對于單個查詢請求,雖然可以直接調用 Querier 的 API 進行查詢,但很容易會由于大查詢導致 OOM,為應對此種問題 querier 與 queryFrontend 結合一起實現查詢分解與多 querier 并發執行。
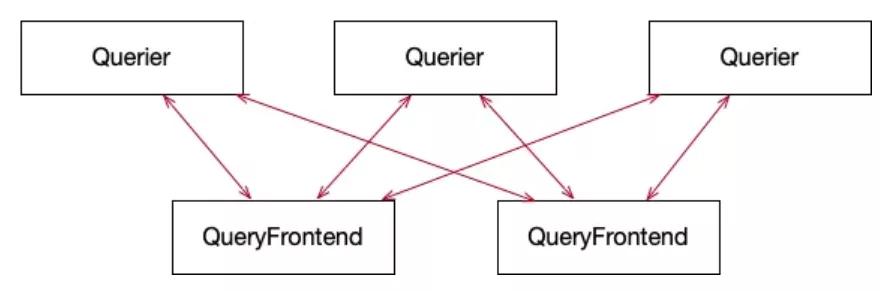
每個 querier 都與所有 queryFrontend 建立 grpc 雙向流式連接,實時從 queryFrontend 中獲取已經分割的子查詢求,執行后將結果發送回 queryFrontend。
具體如何分割查詢及在 querier 間調度子查詢將在 queryFrontend 環節介紹。
⑧查詢流程
先解析 logQL 指令,然后查詢日志流 ID 列表。
Loki 根據不同的標簽選擇器語法使用了不同的索引查詢邏輯,大體分為兩種:
=,或多值的正則匹配=~,工作過程如下:
以類似下 SQL 所描述的語義查詢出標簽選擇器里引用的每個標簽鍵值對所對應的日志流 ID(seriesID)的集合。
- SELECT * FROM Table_N WHERE hash=? AND range>=? AND value=labelValue
hash 為租戶 ID(userID)、分桶(bucketID)、標簽名(labelName)組合計算的哈希值;range 為標簽值(labelValue)計算的哈希值。
將根據標簽鍵值對所查詢的多個 seriesID 集合取并集或交集求最終集合。
比如,標簽選擇器{file="app.log", level=~"debug|error"}的工作過程如下:
- 查詢出 file="app.log",level="debug", level="error" 三個標簽鍵值所對應的 seriesID 集合,S1 、S2、S3。
- 根據三個集合計算最終 seriesID 集合 S = S1∩cap (S2∪S3)。
!=,=~,!~,工作過程如下:
以如下 SQL 所描述的語義查詢出標簽選擇器里引用的每個標簽所對應 seriesID 集合。
- SELECT * FROM Table_N WHERE hash = ?
hash 為租戶 ID(userID)、分桶(bucketID)、標簽名(labelName)。
根據標簽選擇語法對每個 seriesID 集合進行過濾。
將過濾后的集合進行并集、交集等操作求最終集合。
比如,{file~="mysql*", level!="error"} 的工作過程如下:
- 查詢出標簽“file”和標簽"level"對應的 seriesID 的集合,S1、S2。
- 求出 S1 中 file 的值匹配 mysql*的子集 SS1,S2 中 level 的值!="error"的子集 SS2。
- 計算最終 seriesID 集合 S = SS1∩SS2。
以如下 SQL 所描述的語義查詢出所有日志流所包含的 chunk 的 ID:
- SELECT * FROM Table_N Where hash = ?
hash 為分桶(bucketID)和日志流(seriesID)計算的哈希值。
根據 chunkID 列表生成遍歷器來順序讀取日志行:遍歷器作為數據讀取的組件,其主要功能為從存儲系統中拉取 chunk 并從中讀取日志行。其采用多層樹形結構,自頂向下逐層遞歸觸發方式彈出數據。
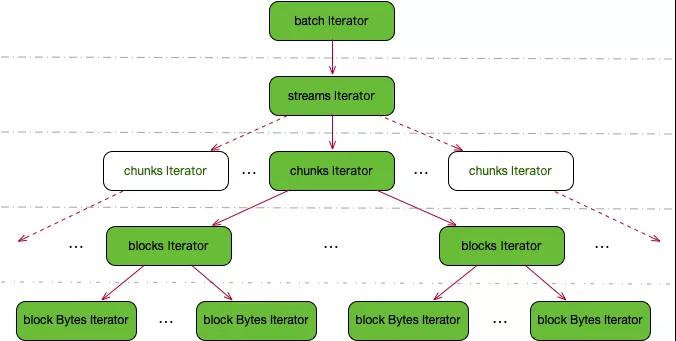
具體結構如上圖所示:
- batch Iterator:以批量的方式從存儲中下載 chunk 原始數據,并生成 iterator 樹。
- stream Iterator:多個 stream 數據的遍歷器,其采用堆排序確保多個 stream 之間數據的保序;
- chunks Iterator:多個 chunk 數據的遍歷器,同樣采用堆排序確保多個 chunk 之間保序及多副本之間的去重。
- blocks Iterator:多個 block 數據的遍歷器。
- block bytes Iterator:block 里日志行的遍歷器。
從 Ingester 查詢在內存中尚未寫入到存儲中的數據:由于 Ingester 是定時的將緩存數據寫入到存儲中,所以 Querier 在查詢時間范圍較新的數據時,還會通過 grpc 協議從每個 ingester 中查詢出內存數據。
需要在 ingester 中查詢的時間范圍是可配置的,視 ingester 緩存數據時長而定。
上面是日志內容查詢的主要流程。至于指標查詢的流程與其大同小異,只是增加了指標計算的遍歷器層用于從查詢出的日志計算指標數據。其他兩種則更為簡單,這里不再詳細展開。
QueryFrontend:Loki 對查詢采用了計算后置的方式,類似于在大量原始數據上做 grep,所以查詢勢必會消耗比較多的計算和內存資源。
如果以單節點執行一個查詢請求的話很容易因為大查詢造成 OOM、速度慢等性能瓶頸。
為解決此問題,Loki 采用了將單個查詢分解在多個 querier 上并發執行方式,其中查詢請求的分解和調度則由 queryFrontend 完成。
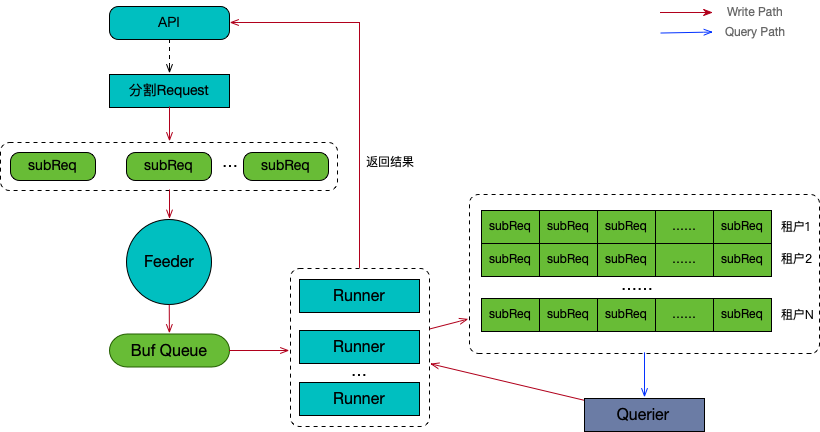
queryFrontend 在 Loki 的整體架構上處于 querier 的前端,它作為數據讀取操作的入口服務,其主要的組件及工作流程如上圖所示:
- 分割 Request:將單個查詢分割成子查詢 subReq 的列表。
- Feeder:將子查詢順序注入到緩存隊列 Buf Queue。
- Runner:多個并發的運行器將 Buf Queue 中的查詢并注入到子查詢隊列,并等待返回查詢結果。
- Querier 通過 grpc 協議實時從子查詢隊列彈出子查詢,執行后將結果返回給相應的 Runner。
- 所有子請求在 Runner 執行完畢后匯總結果返回 API 響應。
⑨查詢分割
queryFrontend 按照固定時間跨度將查詢請求分割成多個子查詢。比如,一個查詢的時間范圍是 6 小時,分割跨度為 15 分鐘,則查詢會被分為 6*60/15=24 個子查詢。
⑩查詢調度
Feeder:Feeder 負責將分割好的子查詢逐一的寫入到緩存隊列 Buf Queue,以生產者/消費者模式與下游的 Runner 實現可控的子查詢并發。
Runner:從 Buf Queue 中競爭方式讀取子查詢并寫入到下游的請求隊列中,并處理來自 Querier 的返回結果。
Runner 的并發個數通過全局配置控制,避免因為一次分解過多子查詢而對 Querier 造成巨大的徒流量,影響其穩定性。
子查詢隊列:隊列是一個二維結構,第一維存儲的是不同租戶的隊列,第二維存儲同一租戶子查詢列表,它們都是以 FIFO 的順序組織里面的元素的入隊出隊。
分配請求:queryFrontend 是以被動方式分配查詢請求,后端 Querier 與 queryFrontend 實時的通過 grpc 監聽子查詢隊列,當有新請求時以如下順序在隊列中彈出下一個請求:
- 以循環的方式遍歷隊列中的租戶列表,尋找下一個有數據的租戶隊列。
- 彈出該租戶隊列中的最老的請求。
總結
Loki 作為一個正在快速發展的項目,最新版本已到 2.0,相較 1.6 增強了諸如日志解析、Ruler、Boltdb-shipper 等新功能,不過基本的模塊、架構、數據模型、工作原理上已處于穩定狀態。
希望本文的這些嘗試性的剖析能夠能夠為大家提供一些幫助,如文中有理解錯誤之處,歡迎批評指正。
作者:張海軍
編輯:陶家龍
出處:轉載自公眾號京東智聯云開發者(ID:JDC_Developers)