你不好奇Linux是如何收發(fā)網絡包的?
前言
這次,就圍繞一個問題來說。
Linux 系統(tǒng)是如何收發(fā)網絡包的?
正文
網絡模型
為了使得多種設備能通過網絡相互通信,和為了解決各種不同設備在網絡互聯(lián)中的兼容性問題,國際標標準化組織制定了開放式系統(tǒng)互聯(lián)通信參考模型(open System Interconnection Reference Model),也就是 OSI 網絡模型,該模型主要有 7 層,分別是應用層、表示層、會話層、傳輸層、網絡層、數(shù)據(jù)鏈路層以及物理層。
每一層負責的職能都不同,如下:
- 應用層,負責給應用程序提供統(tǒng)一的接口;
- 表示層,負責把數(shù)據(jù)轉換成兼容另一個系統(tǒng)能識別的格式;
- 會話層,負責建立、管理和終止表示層實體之間的通信會話;
- 傳輸層,負責端到端的數(shù)據(jù)傳輸;
- 網絡層,負責數(shù)據(jù)的路由、轉發(fā)、分片;
- 數(shù)據(jù)鏈路層,負責數(shù)據(jù)的封幀和差錯檢測,以及 MAC 尋址;
- 物理層,負責在物理網絡中傳輸數(shù)據(jù)幀;
由于 OSI 模型實在太復雜,提出的也只是概念理論上的分層,并沒有提供具體的實現(xiàn)方案。事實上,我們比較常見,也比較實用的是四層模型,即 TCP/IP 網絡模型,Linux 系統(tǒng)正是按照這套網絡模型來實現(xiàn)網絡協(xié)議棧的。
TCP/IP 網絡模型共有 4 層,分別是應用層、傳輸層、網絡層和網絡接口層,每一層負責的職能如下:
- 應用層,負責向用戶提供一組應用程序,比如 HTTP、DNS、FTP 等;
- 傳輸層,負責端到端的通信,比如 TCP、UDP 等;
- 網絡層,負責網絡包的封裝、分片、路由、轉發(fā),比如 IP、ICMP 等;
- 網絡接口層,負責網絡包在物理網絡中的傳輸,比如網絡包的封幀、 MAC 尋址、差錯檢測,以及通過網卡傳輸網絡幀等;
TCP/IP 網絡模型相比 OSI 網絡模型簡化了不少,也更加易記,它們之間的關系如下圖:
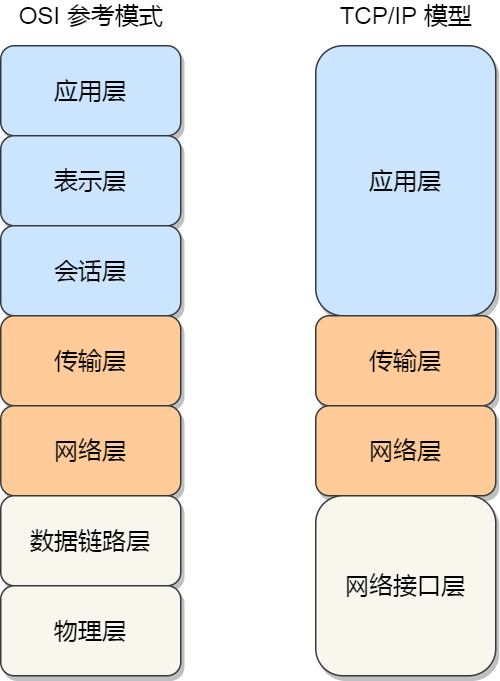
不過,我們常說的七層和四層負載均衡,是用 OSI 網絡模型來描述的,七層對應的是應用層,四層對應的是傳輸層。
Linux 網絡協(xié)議棧
我們可以把自己的身體比作應用層中的數(shù)據(jù),打底衣服比作傳輸層中的 TCP 頭,外套比作網絡層中 IP 頭,帽子和鞋子分別比作網絡接口層的幀頭和幀尾。
在冬天這個季節(jié),當我們要從家里出去玩的時候,自然要先穿個打底衣服,再套上保暖外套,最后穿上帽子和鞋子才出門,這個過程就好像我們把 TCP 協(xié)議通信的網絡包發(fā)出去的時候,會把應用層的數(shù)據(jù)按照網絡協(xié)議棧層層封裝和處理。
你從下面這張圖可以看到,應用層數(shù)據(jù)在每一層的封裝格式。
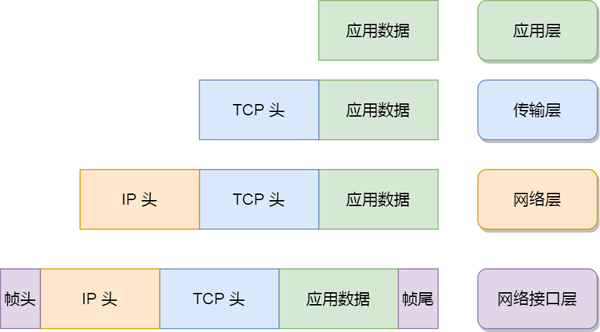
其中:
- 傳輸層,給應用數(shù)據(jù)前面增加了 TCP 頭;
- 網絡層,給 TCP 數(shù)據(jù)包前面增加了 IP 頭;
- 網絡接口層,給 IP 數(shù)據(jù)包前后分別增加了幀頭和幀尾;
這些新增和頭部和尾部,都有各自的作用,也都是按照特定的協(xié)議格式填充,這每一層都增加了各自的協(xié)議頭,那自然網絡包的大小就增大了,但物理鏈路并不能傳輸任意大小的數(shù)據(jù)包,所以在以太網中,規(guī)定了最大傳輸單元(MTU)是 1500 字節(jié),也就是規(guī)定了單次傳輸?shù)淖畲?IP 包大小。
當網絡包超過 MTU 的大小,就會在網絡層分片,以確保分片后的 IP 包不會超過 MTU 大小,如果 MTU 越小,需要的分包就越多,那么網絡吞吐能力就越差,相反的,如果 MTU 越大,需要的分包就越小,那么網絡吞吐能力就越好。
知道了 TCP/IP 網絡模型,以及網絡包的封裝原理后,那么 Linux 網絡協(xié)議棧的樣子,你想必猜到了大概,它其實就類似于 TCP/IP 的四層結構:
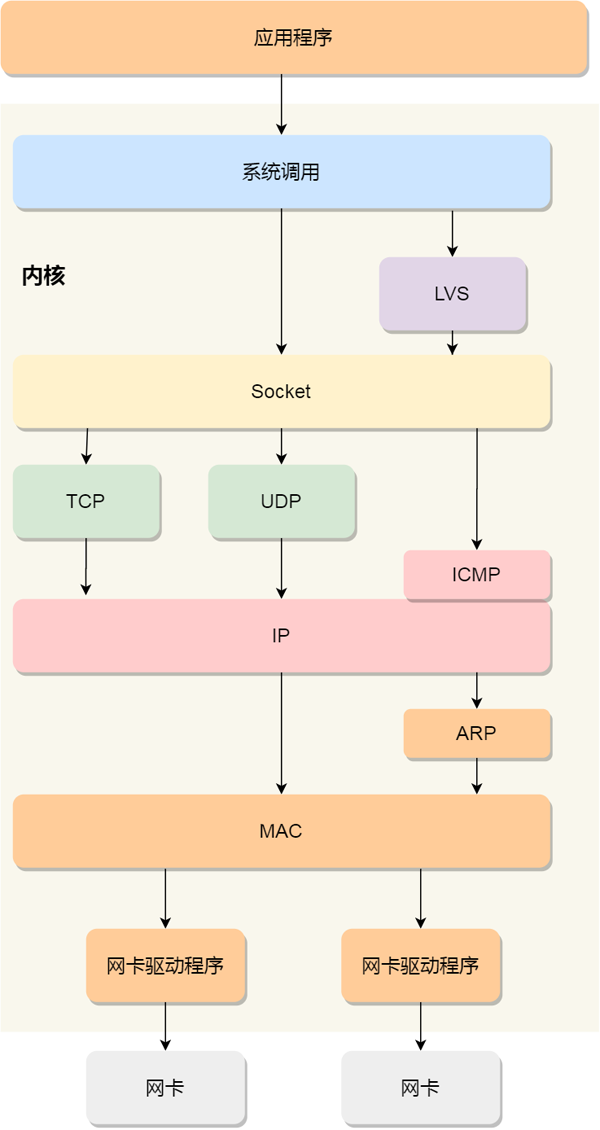
從上圖的的網絡協(xié)議棧,你可以看到:
- 應用程序需要通過系統(tǒng)調用,來跟 Socket 層進行數(shù)據(jù)交互;
- Socket 層的下面就是傳輸層、網絡層和網絡接口層;
- 最下面的一層,則是網卡驅動程序和硬件網卡設備;
Linux 接收網絡包的流程
網卡是計算機里的一個硬件,專門負責接收和發(fā)送網絡包,當網卡接收到一個網絡包后,會通過 DMA 技術,將網絡包放入到 Ring Buffer,這個是一個環(huán)形緩沖區(qū),該緩沖區(qū)在內核內存中的網卡驅動里。
那接收到網絡包后,應該怎么告訴操作系統(tǒng)這個網絡包已經到達了呢?
最簡單的一種方式就是觸發(fā)中斷,也就是每當網卡收到一個網絡包,就觸發(fā)一個中斷告訴操作系統(tǒng)。
但是,這存在一個問題,在高性能網絡場景下,網絡包的數(shù)量會非常多,那么就會觸發(fā)非常多的中斷,要知道當 CPU 收到了中斷,就會停下手里的事情,而去處理這些網絡包,處理完畢后,才會回去繼續(xù)其他事情,那么頻繁地觸發(fā)中斷,則會導致 CPU 一直沒玩沒了的處理中斷,而導致其他任務可能無法繼續(xù)前進,從而影響系統(tǒng)的整體效率。
所以為了解決頻繁中斷帶來的性能開銷,Linux 內核在 2.6 版本中引入了 NAPI 機制,它是混合「中斷和輪詢」的方式來接收網絡包,它的核心概念就是不采用中斷的方式讀取數(shù)據(jù),而是首先采用中斷喚醒數(shù)據(jù)接收的服務程序,然后 poll 的方法來輪詢數(shù)據(jù)。
比如,當有網絡包到達時,網卡發(fā)起硬件中斷,于是會執(zhí)行網卡硬件中斷處理函數(shù),中斷處理函數(shù)處理完需要「暫時屏蔽中斷」,然后喚醒「軟中斷」來輪詢處理數(shù)據(jù),直到沒有新數(shù)據(jù)時才恢復中斷,這樣一次中斷處理多個網絡包,于是就可以降低網卡中斷帶來的性能開銷。
那軟中斷是怎么處理網絡包的呢?它會從 Ring Buffer 中拷貝數(shù)據(jù)到內核 struct sk_buff 緩沖區(qū)中,從而可以作為一個網絡包交給網絡協(xié)議棧進行逐層處理。
首先,會先進入到網絡接口層,在這一層會檢查報文的合法性,如果不合法則丟棄,合法則會找出該網絡包的上層協(xié)議的類型,比如是 IPv4,還是 IPv6,接著再去掉幀頭和幀尾,然后交給網絡層。
到了網絡層,則取出 IP 包,判斷網絡包下一步的走向,比如是交給上層處理還是轉發(fā)出去。當確認這個網絡包要發(fā)送給本機后,就會從 IP 頭里看看上一層協(xié)議的類型是 TCP 還是 UDP,接著去掉 IP 頭,然后交給傳輸層。
傳輸層取出 TCP 頭或 UDP 頭,根據(jù)四元組「源 IP、源端口、目的 IP、目的端口」 作為標識,找出對應的 Socket,并把數(shù)據(jù)拷貝到 Socket 的接收緩沖區(qū)。
最后,應用層程序調用 Socket 接口,從內核的 Socket 接收緩沖區(qū)讀取新到來的數(shù)據(jù)到應用層。
至此,一個網絡包的接收過程就已經結束了,你也可以從下圖左邊部分看到網絡包接收的流程,右邊部分剛好反過來,它是網絡包發(fā)送的流程。
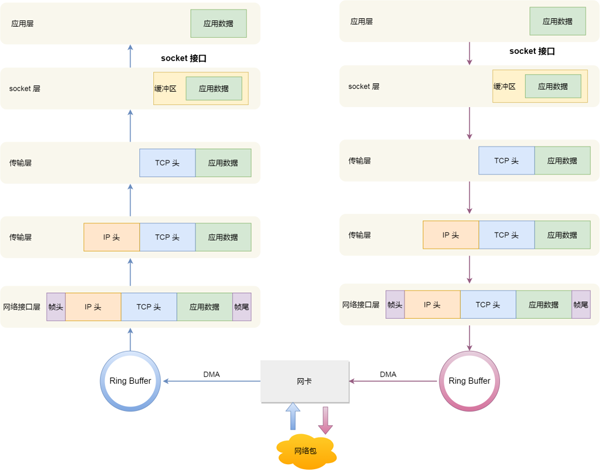
Linux 發(fā)送網絡包的流程
如上圖的有半部分,發(fā)送網絡包的流程正好和接收流程相反。
首先,應用程序會調用 Socket 發(fā)送數(shù)據(jù)包的接口,由于這個是系統(tǒng)調用,所以會從用戶態(tài)陷入到內核態(tài)中的 Socket 層,Socket 層會將應用層數(shù)據(jù)拷貝到 Socket 發(fā)送緩沖區(qū)中。
接下來,網絡協(xié)議棧從 Socket 發(fā)送緩沖區(qū)中取出數(shù)據(jù)包,并按照 TCP/IP 協(xié)議棧從上到下逐層處理。
如果使用的是 TCP 傳輸協(xié)議發(fā)送數(shù)據(jù),那么會在傳輸層增加 TCP 包頭,然后交給網絡層,網絡層會給數(shù)據(jù)包增加 IP 包,然后通過查詢路由表確認下一跳的 IP,并按照 MTU 大小進行分片。
分片后的網絡包,就會被送到網絡接口層,在這里會通過 ARP 協(xié)議獲得下一跳的 MAC 地址,然后增加幀頭和幀尾,放到發(fā)包隊列中。
這一些準備好后,會觸發(fā)軟中斷告訴網卡驅動程序,這里有新的網絡包需要發(fā)送,最后驅動程序通過 DMA,從發(fā)包隊列中讀取網絡包,將其放入到硬件網卡的隊列中,隨后物理網卡再將它發(fā)送出去。
總結
電腦與電腦之間通常都是通話網卡、交換機、路由器等網絡設備連接到一起,那由于網絡設備的異構性,國際標準化組織定義了一個七層的 OSI 網絡模型,但是這個模型由于比較復雜,實際應用中并沒有采用,而是采用了更為簡化的 TCP/IP 模型,Linux 網絡協(xié)議棧就是按照了該模型來實現(xiàn)的。
TCP/IP 模型主要分為應用層、傳輸層、網絡層、網絡接口層四層,每一層負責的職責都不同,這也是 Linux 網絡協(xié)議棧主要構成部分。
當應用程序通過 Socket 接口發(fā)送數(shù)據(jù)包,數(shù)據(jù)包會被網絡協(xié)議棧從上到下進行逐層處理后,才會被送到網卡隊列中,隨后由網卡將網絡包發(fā)送出去。
而在接收網絡包時,同樣也要先經過網絡協(xié)議棧從下到上的逐層處理,最后才會被送到應用程序。