大數據下一個十年將如何演進?
當下我們生活在數據的時代里。機器學習和數據分析技術已經成為了我們當今生活密不可分的一部分。那接下來會怎樣呢?
在這篇博客中,我不打算預測數據科學面對的未來是什么,不會去猜測它的未來是光明有前途,還是毫無希望。這里我只結合自己,還有我認識的一些人的經歷,提供一些決定性因素幫忙做預測。
拋開這些,我先大致勾勒一下今后10年影響數據科學未來的關鍵因素。我希望它會在工作流程上帶給你一些有價值的見解。不用多說,這只是我的個人預測。如果你感興趣,請繼續讀下去!
數據科學的未來:我怎樣看待?
#1 更多的數據科學策略
數據科學就是通過定量的方式解決問題的一門學科。在過去,由于缺少數據或數據處理能力,我們只能依賴其它東西,比如“獨裁者的突發奇想”、“專家的直覺”和“普遍的共識”等。今天,這些根本都不管用了,而且毫無疑問,10年后它們的作用會更有限。數據科學家轉而在搭建一些系統,這些系統可以輸出語音、預測、給出期望并輸出真正的結果。
數據科學技術的泡沫不會破裂,相反,數據驅動策略的引入將繼續占據主流。更多的人會關注數據,從數據中獲得真知灼見,所以數據科學團隊成為任何成功組織機構,至少是大部分組織不可或缺的一部分,由此組織之間會競爭,渴望爭得領域前沿的位置。
#2 更多界定明確的角色
因此數據科學會更受歡迎,絕大多數顧客會更清楚數據科學家到底是做什么的。現在,數據科學家是一個寬泛的頭銜。目前領域內的人使用相關名稱和描述時有一些不嚴謹,所以外界對該領域中人的角色有很多困惑。
我們一般把數據科學領域的角色分成4類,它們角色職能不同但有重疊。
- 數據架構師——開發數據架構,以有效地捕獲、整合、組織、中心化和維護數據。
- 數據分析師——處理和解釋數據,為公司提供有執行意義的預測。
- 數據科學家——一旦數據體量和產生速率達到一定水平,需要復雜技術時,他們會對數據進行分析。
- 數據工程師——開發、測試和維護數據架構,保證隨時使用和分析數據。
我認為隨著時間推移,所有這些角色我們會更熟悉,我們也會更了解它們的不同點。因此,顧客會對什么可得什么不可得,有更切實際的期待,頭腦中會有更清晰的工作流程,還有從中獲得的收益。
#3 更多的軟技能需求
隨著時間推移,我們會更清楚地看到,大量的數據科學家會熟練運用Python或R語言。但是,向管理層推銷你的想法的能力,說服他們相信你的洞察和見解才值得追求的能力,這種能力會怎樣?可視化描述可以承擔一半工作,而另一半就是老舊的市場營銷能力。結果,我們會看到市場更青睞那些知道如何圍繞出售產品創造關鍵性對話的人。因此,那些能將硬軟技能結合的人會永遠吃香。
#4 數據會更多,處理數據的人工智能也會更多
現在我們談一些嚴肅的東西。每天我們產生的數據量多到難以想象,以我們現在的速度,每天產生數據量有2.5個10的18次方字節,而且這個速度只會加快。看一下Raconteur(https://www.raconteur.net/infographics/a-day-in-data)網站做出的每日關鍵數據信息圖:
- 5億推特信息;
- 2940億電子郵件;
- 四千萬億字節的Facebook數據;
- 四萬億字節的單位車聯網數據;
- 650億條WhatsApp信息;
- 50億條搜索信息;
到2025年,預計全球每天將產生463艾字節(463*10^18字節)數據,相當于每天212,765,957張DVD的數據量!
實際上,僅靠數據科學家,無法管理和處理這么龐大的數據。屆時,人工智能很可能成為協助數據科學家處理數據的有效工具。自動化數據分析工具和機器學習會“聰明”到取代數據科學家做例行工作,比如探索性數據分析、數據清理、統計建模和構建機器學習模型。
#5 更少的代碼,相當少的代碼
據特斯拉AI總監A. Karpathy說,不久的將來,我們可以不用寫代碼了。我們只需要找到數據,并輸入到機器學習系統即可。此種場景下,軟件工程師的角色會成為“數據監管者”。未來大多數程序員都不再需要復雜的軟件倉庫,不用寫復雜的程序。Karpathy說,程序員會從事搜集、清理、操作、標記、分析數據以及對神經網絡產生的數據進行可視化的工作。
機器學習正在引領一種新的計算范式,在該范式中訓練機器才是關鍵技能。隨著機器學習技術的普及,以及通過工具的抽象達到更高程度,我們會看到大部分編程工作會逐漸消失。最終,制造產品的大部分步驟將是屏幕上的拖拽、刷卡、指向和點擊操作。從業者會從中解放出來,在解決問題時更有策略性和創造性。你在《星際迷航》中看到過有誰寫計算機程序嗎?沒有。
諸如R語言、Python和Spark這樣的工具會變得無用武之地嗎?大多數數據科學家不再需要通過寫程序的方式做統計分析或訓練機器學習模型了嗎?沒有這么簡單。無論如何,把希望寄托于這些方面意義不大。你仍然需要理解和熟悉所有這些處理過程,機器學習只是輔助一些日常事務。
#6 盡可能多地使用API(應用程序接口)
大部分公司是先做好一件事情,攢到名氣,然后以此起步,以開源API的形式貢獻到社區。10年后,大部分軟件的制作方式會可見地接入到終端,最大程度地利用一切所需的服務生成解決方案。數據科學家能快速構建測試模型,一次建立和測試多種算法,最后和整個團隊可視化驗證結果。未來隨著適時地引入深度的技術思考,科學家將不再白費力氣做重復工作了。
#7 自我學習
傳統的學術環境將逐漸失去意義。信息經濟需要能快速改變信息的途徑。人們通過3-4年的學習畢業后,所學的技能已經過時。人們開始掌控自己的學習過程為自己賦能,未來得以生存的學院將是那些擁抱在線學習、快速更新課程授予方式的學院。未來的學習會基于你能構建什么而定義,而不是缺乏現實世界應用的基礎原理。
Q1. 數據科學家是否會被自動化算法替代
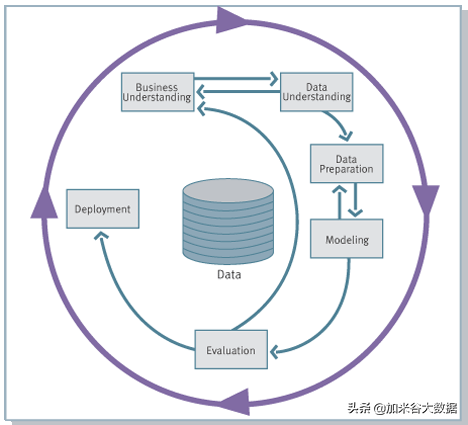
根據廣受歡迎的CRISP-DM數據分析項目的管理方法論,數據分析項目的實施分為6個階段,每個階段中,分析師或者數據科學家都是直接參與的:
- 業務理解
- 數據理解
- 數據準備
- 建模
- 評估
- 部署
步驟3和4包括大量的例行化工作。為了利用機器學習解決每個具體的實力,你必須不斷地:
- 配置模型超參;
- 嘗試新的算法;
- 向模型加入原始特征的不同表現形態(標準化、方差穩定性、單調變換、降維、分類變量編碼、從已有特征中創建新特征等等)。
在自動化的幫助下,分析師或數據科學家的例行操作,以及數據準備和清理中的部分操作可以被移除。但是,步驟3和4中的其他部分,以及CRISP-DM中的剩余步驟都會被保留,所以分析師的這種日常工作上的簡化不會對他們的職業造成任何威脅。
機器學習僅僅是數據科學家使用的工具之一,此外還有可視化、數據調研、統計和計量經濟學方法。即使在機器學習方法里,完全自動化也是不可能的。在解決新算法及其組合的開發和應用中存在的非標準化問題時,數據科學家的高級角色特性毫無疑問會繼續保持。自動化算法能夠梳理所有的標準組合,生成一個基礎解決方案,專家們可以此為基礎做進一步改進。但在很多情況下,自動化算法生成的結果已經足夠好,不用改進即可直接使用。
很難想像,離開分析師的幫助,一種業務可以直接使用自動化機器學習方法生成的結果。任何情況下,上述方案的數據準備、對生成結果的解釋以及其他階段都是必需的。同時,現在許多公司的分析師,不斷與數據打交道,擁有非常成熟的心態,在業務領域非常精通,但是掌握機器學習方法的水平還不夠。
公司通常很難吸引到特別勝任的高薪機器學習專家,市場對他們的需求不斷增長,而且超出供給很多倍。解決辦法可能是為公司的分析師提供使用自動化機器學習工具的渠道,這需要自動化技術的普及。未來,許多公司不用組建高度專業化的團隊,也不需要顧問企業的參與,就能享受到大數據帶來的好處。
Q2. 數據工程師會比數據科學家更搶手嗎?
我認為應該區分一下數據科學家和數據工程師了。
前者是接受過正規教育的應用數學家,他們研究數據科學,開發新算法,組建神經網絡等等。
后者的興趣關注點稍微不同,他們了解每種方法的理論和應用局限,能成功解決業務問題。
前者能做事情永遠不缺,而后者的部分工作可以自動化完成,但無法完全自動化。新方法、新算法和新的解決途徑總會出現。另外,對主題領域和數據本質的專業性理解,對顧客目標的理解,以及快速實現目標的能力,無法通過完全自動化的方法做到,所以這些能力仍然極其重要。
數據科學是切合實際的科學——但是世界正朝著功能性的數據科學發展,從業人員可以自己做數據分析。相比于數據科學家,你需要更多的數據工程師來啟動數據流程和整合的數據結構。
聰明的機構擁有聰明的人才,他們很懂自己的數據。數據科學家之所以存在的原因是大多數機構還不太懂數據。但他們以后會懂的。
如果一名數據科學家創造了一項突破性算法,但沒有數據工程師將該算法落地到業務生產中,那算法會產生價值嗎?
我重申一下我最喜歡的Gartner數據,只有15%的大數據項目最后投入了生產領域。雖然他們從沒有深入探尋剩下的85%為什么沒能投入生產領域,但是我提出一些未能成功落地的幾個關鍵原因:
- 他們沒有找到一個能值得落地的見解;
- 他們找到了合適的見解,也構建了模型,但沒能創建可以在服務水平協議框架下多次使用的流水線;
- 他們不需要什么見解,因為他們需要的數據分析不用依賴復雜的模型。但仍然是沒能可以在服務水平協議框架下多次使用的流水線。
這就是為什么每家數據科學公司都需要至少兩名數據工程師的原因。
總結……
數據科學家職業的未來前景如何,仍然很模糊,需要專業的判斷。但是,每天都有新的代碼庫和工具出現,我們絕不是走在簡化開發和創建業務模型這些基礎設施的道路上。許多人都很自信地說不錯,但還有不好的一面,我們創建的系統越復雜,系統就越隨機,越基于概率。
目前人工智能階段的主要問題是在預言結果的意義是缺乏直覺。我們只有定量的方法來解決某個特定的問題,基于此方法做出預測,但是預測的質量不高。目前為止,這個方法運行得很不錯的,但未來不得而知。
讓我們拭目以待吧。