自然界也有源代碼:一位程序員逆向工程了輝瑞新冠疫苗
前幾天,一位程序員的作品在推特火了。

我們都知道,計算機程序是用代碼編寫而成的。最底層會有機器代碼和匯編語言,諸如 C、Python 之類的高級語言讓人們更容易理解。其實,自然界也有源代碼,它的形式是「DNA 和 RNA 字符串」,其中就包含著構成生命元素的代碼。
在這篇文章中,作者 Bert Hubert 介紹了計算機和生物學之間的有趣聯系。對于一般讀者來說,這是一篇簡單但不失科普意義的分析文章,站在生物學的角度解釋了一些高度復雜的概念。讀完這篇博客內容,一些人也許能夠受到啟發,從而走進遺傳學和生物學的世界。
言歸正傳,大眾印象中的疫苗是一種由手臂注射的液體,為什么要討論它的源代碼?
這個問題很好。如果想要解答它,就先從 BioNTech / 輝瑞的新冠疫苗「 BNT162b2」源代碼的一小部分開始,該疫苗又被稱為 Tozinameran、Comirnaty。

BNT162b2 mRNA 的前 500 個字符。資料來源:世界衛生組織。
BNT162b mRNA 疫苗內部就有這樣的數字代碼,它的長度為 4284 個字符。在疫苗生產期間,就有人將此代碼上傳到了 DNA 打印機,然后將磁盤上的字節轉換為實際的 DNA 分子。
BioXpTM 3200 DNA 打印機
這臺機器產生的 DNA 很少,經過大量的生物和化學處理后,DNA 最終變成了疫苗瓶中的 RNA。30 微克劑量的疫苗實際上包含 30 微克的 RNA,此外還包含一個脂質包裝系統,可將 mRNA 導入人體細胞。
RNA 算是 DNA 的 volatile「工作內存」版本。DNA 就像生物領域的閃存存儲,非常耐用、可存儲冗余且非常可靠。但是,就像計算機不能直接從閃存驅動器運行代碼一樣,在某些事情發生前,代碼會被復制到更快、功能更廣泛但更脆弱的系統中。
在計算機領域,RAM 如此,在生物學領域,RNA 亦如此。很多事情就是這樣驚人地相似,RAM 降低地很快,RNA 也是「易碎的花朵」,因此輝瑞 / BioNTech mRNA 疫苗必須存放于最深的冷凍柜中。
每個 RNA 字符的重量約為 0.53·10^⁻²¹ 克,意味著一劑 30 微克的疫苗中就有 6·10^¹⁶個字符,以字節表示的話約為 25 PB,也就是說由 2 萬億段重復的 4284 個字符組成。疫苗包含的實際信息量剛剛超過 1KB,新型冠狀病毒( SARS-CoV-2)本身的重量是 7.5KB 左右。
基本背景介紹
DNA 是數字代碼,與使用 0 和 1 的計算機不同,生物學領域使用 A、C、G 和 U / T(「核苷酸」、「核苷」或「堿基」)。
A、C、G 和 U/ T 是分子,以鏈狀存儲在 DNA 或 RNA 中。
在計算機中,8 比特為一字節,字節是計算機數據處理的最小存儲單元。而自然界將 3 個核苷酸編為一個密碼子,密碼子是遺傳信息中的基本內容,包含 6 個比特的信息。
疫苗的宗旨是教會人體免疫系統如何抵抗病原體,卻不會生病。所以代碼的作用是什么呢?
源代碼
我們先來看世衛組織(WHO)披露的圖:

我們先從「cap」開始。就像你不能在計算機文件中輸入操作碼并運行一樣,生物操作系統也需要頭文件(header)、鏈接器(linker)和調用約定(calling convention)等。
輝瑞疫苗的代碼從以下兩個核苷酸開始:
- GA
這相當于以 MZ 開頭的 DOS 和 Windows 可執行文件,或以 #! 開始的 UNIX 腳本。在生命系統和操作系統中,這兩個字母都不會以任何方式執行,但它們必須存在,否則其他操作將不會發生。
mRNA cap 具備很多功能,例如它可以將編碼標記為來自細胞核。而在本文討論的疫苗范疇內,編碼來自疫苗。cap 使編碼看起來合規,從而避免受到破壞。
GA 核苷酸的化學成分與 RNA 的其他部分略有不同,此處 GA 有某種帶外(out-of-band)信號。
5′ 非翻譯區(5′ UTR)
蛋白質是生命的物質基礎。當 RNA 轉化為蛋白質時,這就叫做「翻譯」。
RNA 分子只能從一個方向讀取,讀取在 5′ 非翻譯區開始,在 3' 非翻譯區停止。
5′ 非翻譯區(5′ UTR)是指成熟 mRNA 位于編碼區(CDS)上游、5′端帽下游不被翻譯為蛋白質的區域:
- GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACC
這里我們遇到了第一個驚喜。RNA 的堿基主要有四種:A(腺嘌呤)、G(鳥嘌呤)、C(胞嘧啶)和 U(尿嘧啶),U 在 DNA 中被稱為「T」。但這里出現了 Ψ。
Ψ 是輝瑞疫苗極聰明的地方。人體運行著一個強大的防病毒系統。因此,細胞對外來 RNA 極其冷漠,并試圖在它做出什么之前摧毀它。這就是疫苗面臨的一個問題,它需要逃過人體免疫系統。過去數年的實驗發現,如果 RNA 中的 U 被一個經過略微修改的分子替代,則免疫系統會對它失去興趣。
因此,輝瑞疫苗中的每一個 U 都被 Ψ(1-methyl-3’-pseudouridylyl)替代。其中的聰明之處在于,盡管 Ψ 安撫了人體免疫系統,但它仍被細胞相關部分以正常的 U 接受。
計算機安全領域也有類似的事情。有時一條信息的輕微受損版本可以騙過防火墻和安全解決方案進行傳播,而它仍被后端服務器所接受。
很多人問,疫苗可以利用 Ψ 技術擊敗人體免疫系統嗎?答案是否定的。生命本身不具備構建 1-methyl-3’-pseudouridylyl 核苷酸的機制。病毒依賴該生命機制來復制自己,但該機制不存在。mRNA 疫苗在人體中快速降解,因此不可能存在Ψ修正后的 RNA 不可能進行復制。
現在回到 5′ 非翻譯區。這 51 個字母在做什么?和自然界中的每個事物一樣,幾乎沒有什么事物具備一種清晰功能。當細胞需要將 RNA 翻譯為蛋白質時,這需要通過一種稱作核糖體的機器完成。核糖體就像一個蛋白質 3D 打印機,它吸收 RNA,并輸出氨基酸,然后生成蛋白質。
圖源:維基百科用戶 @Bensaccount。
如動圖中所示,底部的黑色帶狀物是 RNA,帶狀物出現在綠色區域的部分是合成的蛋白質,飛來飛去的東西是氨基酸和適配器,使得它們適合 RNA。
該核糖體需要在物理上位于 RNA 鏈才能起作用,一旦固定,它就可以基于攝入的其他 RNA 開始形成蛋白質。由此可以想象出它不能讀取其最先著陸的部分。這只是 UTR 的功能之一:核糖體著陸區。UTR 提供了「導入」的功能。
除此之外,UTR 還包含元數據:翻譯何時發生?發生多少?對于疫苗來說,他們采取了從 α 珠蛋白基因中獲得的「即刻」UTR 。眾所周知,該基因能產生大量蛋白質。在過去的幾年中,科學家們已經找到了進一步優化該 UTR 的方法,并不是 α 珠蛋白 UTR,總體更好一些。
S 糖蛋白信號肽
如前所述,疫苗的目的是使細胞產生大量的 SARS-CoV-2 刺突蛋白。到目前為止,我們在疫苗源代碼中遇到的都是元數據和「調用約定」。現在進入真正的病毒蛋白領域。
然而,我們還有一層元數據需要處理。一旦核糖體制造出一個蛋白質,則該蛋白質依然需要去到某處。這就是在「S 糖蛋白信號肽(擴展的導肽序列)」中進行編碼。
如何了解這種情況呢?在蛋白質的開頭有一種地址標簽,它們被編碼為蛋白質的一部分。在這一案例中,信號肽表明這一蛋白質應通過「內質網」從細胞中分離出來。
此外,「信號肽」并不長,但當我們查看代碼時會發現,病毒和疫苗 RNA 之間是有區別的。具體如下代碼所示,為方便對比,這里使用規則的 RNA U 替代了修正后的Ψ:
- 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
- Virus: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU
- Vaccine: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUU
- ! ! ! ! ! ! ! ! ! ! ! ! !
發生了什么?RNA 并不是偶然地以 3 個字母一組的形式列出。我們知道,3 個 RNA 字符組成一個密碼子,并且每個密碼子對特定的氨基酸進行編碼。疫苗信號肽中包含的氨基酸與病毒本身中的氨基酸完全相同。
那么 RNA 為何不同呢?
由于有 4 個 RNA 字符,其中 3 個在密碼子中,所以共有 4^³=64 個不同的密碼子。但是只有 20 種不同的氨基酸,所以多個密碼子需要對同一種氨基酸進行編碼。
下圖為 RNA 密碼子與氨基酸之間的映射關系:
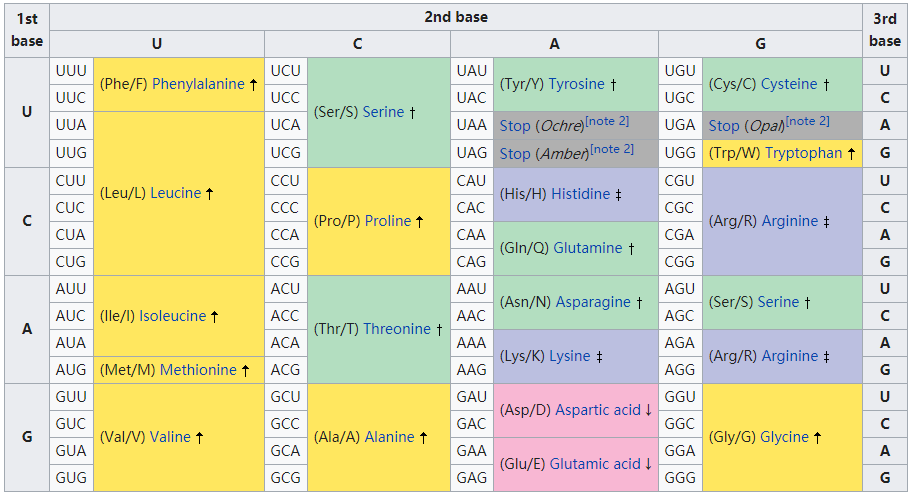
RNA 密碼子。圖源:Wikipedia
如上表所列,疫苗的修改(UUU → UUC)都是同義(synonymous)的。疫苗 RNA 編碼不同,但產生了相同的氨基酸和蛋白質。
如果仔細觀察,我們可以看到大多數的變化出現在密碼子的第 3 個位置,上面標有「3」。如果檢查通用密碼子圖表的話,則會發現第 3 個位置與氨基酸的產生無關。
所以,變化是同義的。但為何會出現這些變化呢?仔細觀察就會發現,除了其中一個變化之外,其余所有變化都會導致更多的 C 和 Gs。
所以為何要這么做呢?如上文所述,我們的免疫系統對「外源性」RNA(即來自細胞外的 RNA 代碼)持悲觀態度。為了逃避檢測,RNA 中的「U」已經被Ψ所替代。
但結果表明,擁有更多 Gs 和 Cs 的 RNA 也可以更高效地轉換成蛋白質。通過將更多的字符替代成 Gs 和 Cs,疫苗 RNA 中已經實現了這一點。
真正的刺突蛋白
疫苗 RNA 接下來的 3777 個字符進行類似的「密碼子優化」,以添加更多的 C 和 G。基于空間考慮,這里沒有列出所有的代碼,但列出了非常特殊的部分。這部分代碼能夠真正起到作用,并有助于人們生活恢復常態:
- * *
- L D K V E A E V Q I D R L I T G
- Virus: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC
- Vaccine: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC
- L D P P E A E V Q I D R L I T G
- ! !!! !! ! ! ! ! ! ! !
如上代碼所示,我們可以看到同義的 RNA 變化。例如,在第一個密碼子中,CUU 變成了 CUG。這表示在疫苗中增加了另一個「G」,它有助于增強蛋白質生產。由于 CUU 和 CUG 都對氨基酸「L」(亮氨酸)進行編碼,所以蛋白質中沒有變化。
當我們比較疫苗中整個刺突蛋白時發現,所有的變化都是同義的,但以下兩個除外。
上面的第 3 和第 4 個密碼子代表了實際變化。K 和 V 氨基酸都被「P」( 脯氨酸)所替代。對于「K」氨基酸,需要 3 次變化 (「!!!」);對于「V」氨基酸,則只需要 2 次變化 (「!!」)。
這表明,這兩種變化極大地提升了疫苗效率。
如果觀察真正的 SARS-CoV-2 粒子,則會看到一簇簇的刺突蛋白,如下圖所示:
SARS 病毒粒子。圖源:Wikipedia SARS virus particles
這些刺突被植入到病毒體(核衣殼蛋白)上。但問題是,我們的疫苗只產生刺突,不會把它們植入到任何病毒體內。
結果是,未經修飾的、獨立的刺突蛋白坍縮成不同的結構。如果作為疫苗注射,這確實會使我們的身體產生免疫力,但只針對坍縮的刺突蛋白。
真正的 SARS-CoV-2 是帶著刺突的。在這種情況下,疫苗不會很有效。
那該怎么辦呢?2017 年,有人描述了如何在正確位置放置一個雙脯氨酸替代將使 SARS-CoV-1 和 MERS S 蛋白形成「預融合」結構,即使不是整個病毒的一部分。這是因為脯氨酸是一種非常堅硬的氨基酸。它就像一種夾板,在我們需要向免疫系統展示的狀態下穩定蛋白質。
蛋白質的末端,下一步
如果我們瀏覽源代碼的剩余部分,則會在刺突蛋白的末端遇到一些小的修飾:
- V L K G V K L H Y T s
- Virus: GUG CUC AAA GGA GUC AAA UUA CAU UAC ACA UAA
- Vaccine: GUG CUG AAG GGC GUG AAA CUG CAC UAC ACA UGA UGA
- V L K G V K L H Y T s s
- ! ! ! ! ! ! ! !
在蛋白質末端,我們會發現一個「終止」密碼子,用小寫「s」表示。這是一種禮貌說法,表示蛋白質應該到此為止。最初的病毒使用 UAA 終止密碼子,疫苗使用兩個 UGA 終止密碼子,這也許會為了更好的措施。
3′ 非翻譯區(3’ UTR)
就像核糖體在 5 '端需要一些導入,我們發現了' 5UTR。在蛋白質的末端我們發現了一個類似的結構,稱之為 3 ' UTR。
關于 3'UTR 有很多說法,這里我們引用維基百科的說法:「3' UTR 在基因表達中起著關鍵作用,它影響著 mRNA 的定位、穩定性、輸出以及翻譯效率。目前盡管我們對 3' UTR 有所了解,但它們仍然相對神秘。」
我們所知道的是,某些 3'-UTR 在促進蛋白質表達方面非常成功。根據 WHO 文件,輝瑞疫苗 3'-UTR「從 split (AES) mRNA 的氨基末端增強子和編碼 12S 核糖體 RNA 的線粒體提取,以保證 RNA 的穩定性和高總蛋白表達。」
The AAAAAAAAAAAAAAAAAAAAAA end of it all
mRNA 最末端是聚腺苷化的。這是一種很奇特的說法,它以「AAAAAAAAAAAAAAAAAAA」結尾。
mRNA 可以重復使用多次,但當這種情況發生時,它也會在末端失去一些 A。一旦 A 耗盡,mRNA 不再起作用而被丟棄。這樣,「poly-A」尾巴就可以防止其退化。
有研究發現了,對于 mRNA 疫苗,末端 A 的最佳數目是多少。公開文獻中的數據表明,該數字在 120 上下時達到峰值。
BNT162b2 疫苗的結尾是:
- ****** ****
- UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA
- AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAA
這是 30 個 A,然后是 10 個核苷酸連接體 (GCAUAUGACU),然后又是 70 個 A。
總結
我們現在知道了 BNT162b2 疫苗確切的 mRNA 含量,并且在很大程度上理解了它們存在的原因。可以概括如下幾點
- CAP 來確保 RNA 看起來像普通的 mRNA;
- 已知的成功和優化的 5'UTR;
- 密碼子優化信號肽,可以將刺突蛋白發送到正確的位置(100% 復制自原始病毒);
- 原始刺突密碼子優化版本,有兩個「脯氨酸」替代,以確保蛋白質以正確的形式出現;
- 已知成功和優化的 3'UTR;
- 有點神秘的多聚腺苷酸尾(Poly-A Tail),里面有一個無法解釋的連接器。
最后,密碼子優化在 mRNA 上增加了大量的 G 和 C。與此同時,使用Ψ(1 - 甲基 - 3'- 偽尿苷酰基)替代 U,有助于逃避自身免疫系統,因此 mRNA 會停留足夠長的時間,所以我們實際上可以幫助訓練免疫系統。