如何正確使用 Scrapy 自帶的 FilesPipeline?

Scrapy自帶的 FilesPipeline和ImagesPipeline用來下載圖片和文件非常方便,根據它的官方文檔[1]說明,我們可以很容易地開啟這兩個 Pipeline。
如果只是要下載圖片,那么用 FilesPipeline 和 ImagesPipeline 都可以,畢竟圖片也是文件。但因為使用 ImagesPipeline 要單獨安裝第三方庫 Pillow,所以我們以 FilesPipeline 為例來進行說明。
假設爬蟲通過解析網頁的源代碼,獲取到了一張圖片,圖片的地址為:https://kingname-1257411235.cos.ap-chengdu.myqcloud.com/640.gif 當然,png 、 jpg 、甚至 rar、pdf、zip 都可以。
為了使用 Scrapy 自帶的 FilesPipeline來下載這張圖片,我們需要做幾步設置。
定義 items
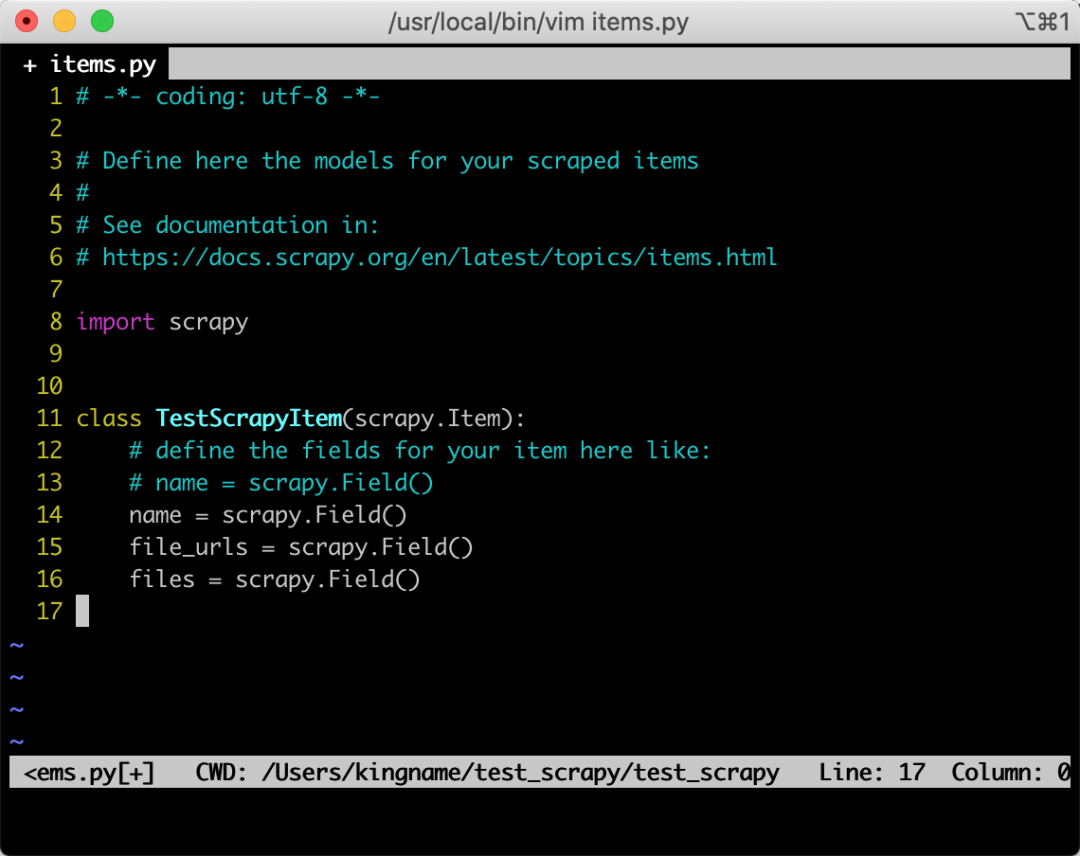
首先定義任意一個 items,需要確保這個 items 里面,必須包含file_urls字段和files字段,除了這兩個必備字段外,你還可以任意增加其他字段。
啟動FilesPipeline
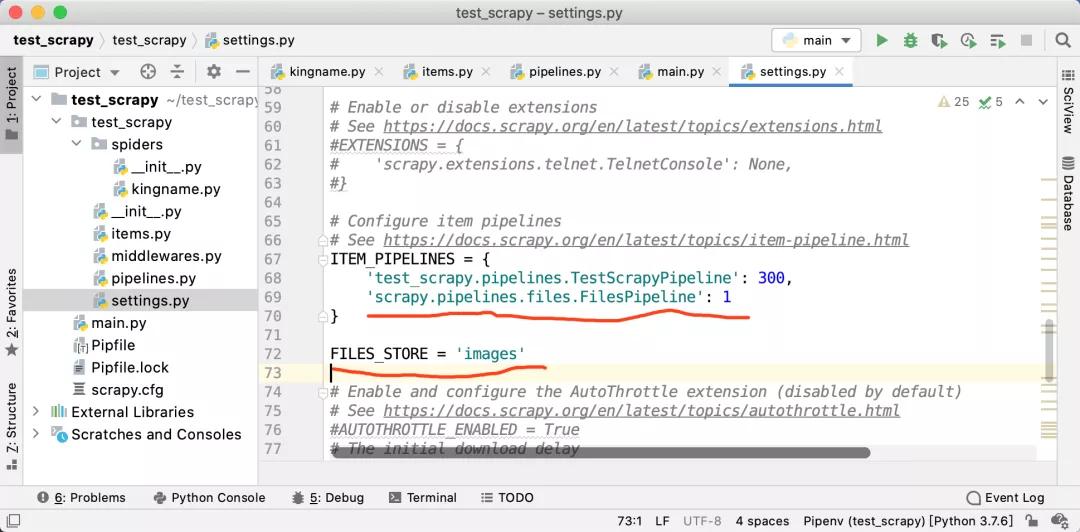
在settings.py中,找到 ITEM_PIPELINES配置,如果它被注釋了,那么就解除注釋。然后添加如下的配置:
- 'scrapy.pipelines.files.FilesPipeline': 1
再添加一個配置項FILES_STORE,它的值是你想要保存圖片的文件夾地址。
修改以后如下圖所示:
下載圖片
接下來,就進入到我們具體的爬蟲邏輯中了。在爬蟲里面,你在任意一個 parse 函數中提取到了一張或者幾張圖片的URL 后,把它(們)以列表的形式放入到 item 里面的 file_urls 字段中。如下圖所示。
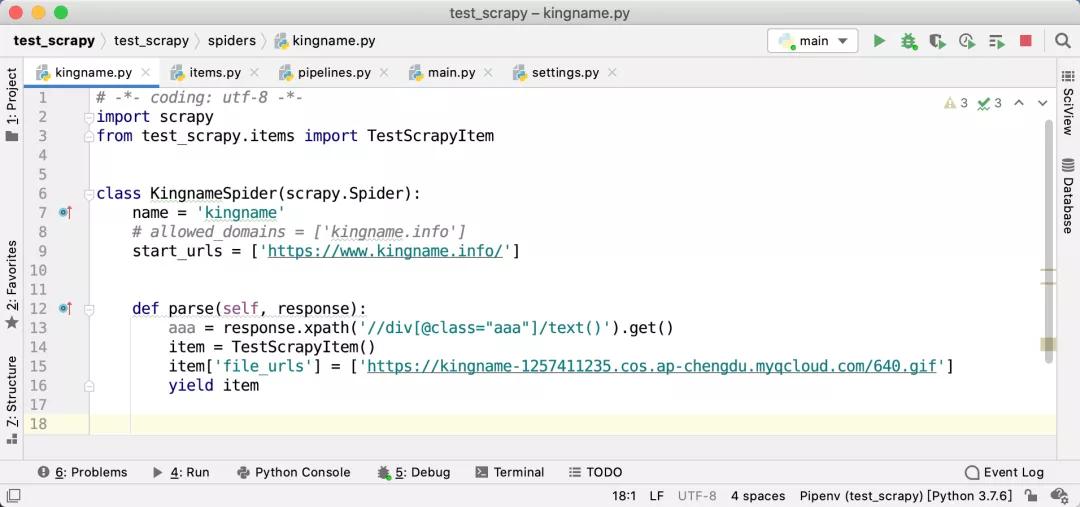
注意,此時files字段不需要設置任何的值。其他非必需字段就根據你的需求只有設置即可。
獲取結果
由于我們設置了scrapy.pipelines.images.FilesPipeline的優先級為1,是最高優先級,所以它會比所有其他的 Pipeline 更先運行。于是,我們可以在后面的其他Pipeline 中,檢查 item 的 files 字段,就會發現我們需要的圖片地址已經在里面了。如下圖所示:
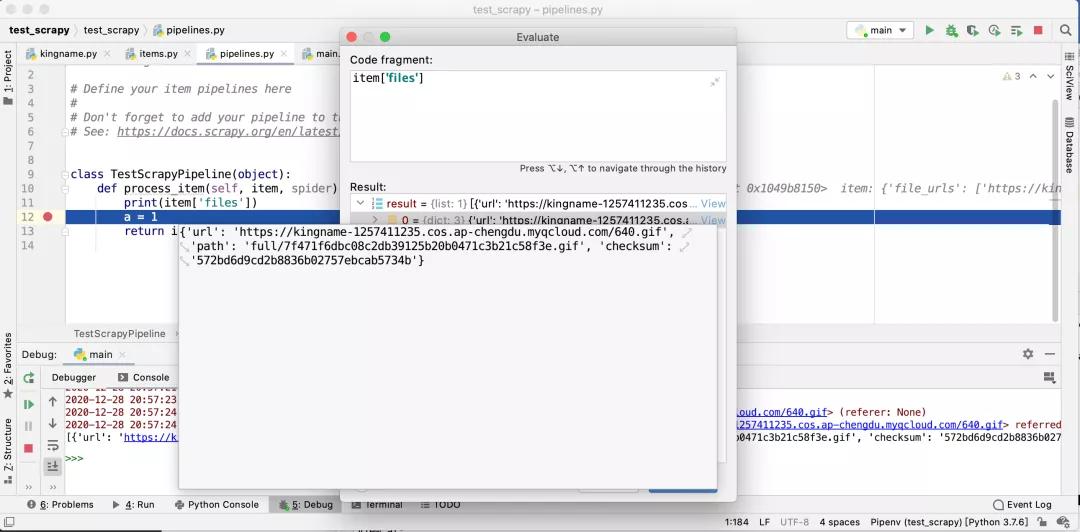
item 中的 files 字段變成了一個包含字典的列表。字典中有一項叫做path的 Key,它的值就是圖片在電腦上的路徑,例如full/7f471f6dbc08c2db39125b20b0471c3b21c58f3e.gif表示在images文件夾中的full文件夾中的7f471f6dbc08c2db39125b20b0471c3b21c58f3e.gif文件,如下圖所示:
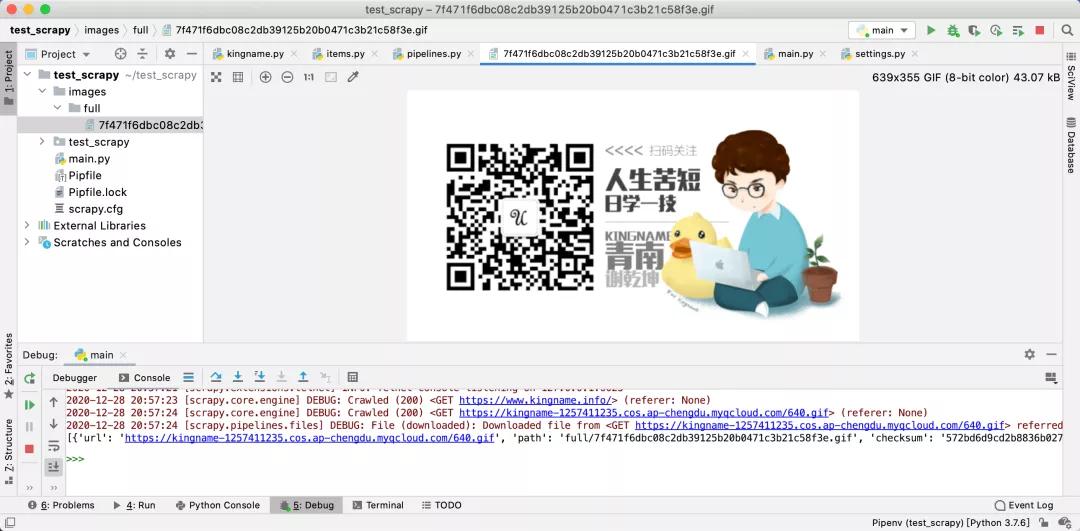
文件名是該文件的 md5值,如果你想重命名,可以在后續的 pipeline 中,根據 path 的值找到文件,然后修改名字。
修改請求頭
看到這里,大家會不會有一個疑問,在使用FilesPipeline的時候,Scrapy 會加上請求頭嗎?它會用哪一個請求頭呢?
實際上,Scrapy 在使用 FilesPipeline和ImagesPipeline時,是不會設置請求頭的。如果網站會監控請求圖片或者文件的請求的請求頭,那么就可以立刻發現這個請求是通過 Scrapy 發起的。
為了證明這一點,我們可以查看FilesPipeline的源代碼:
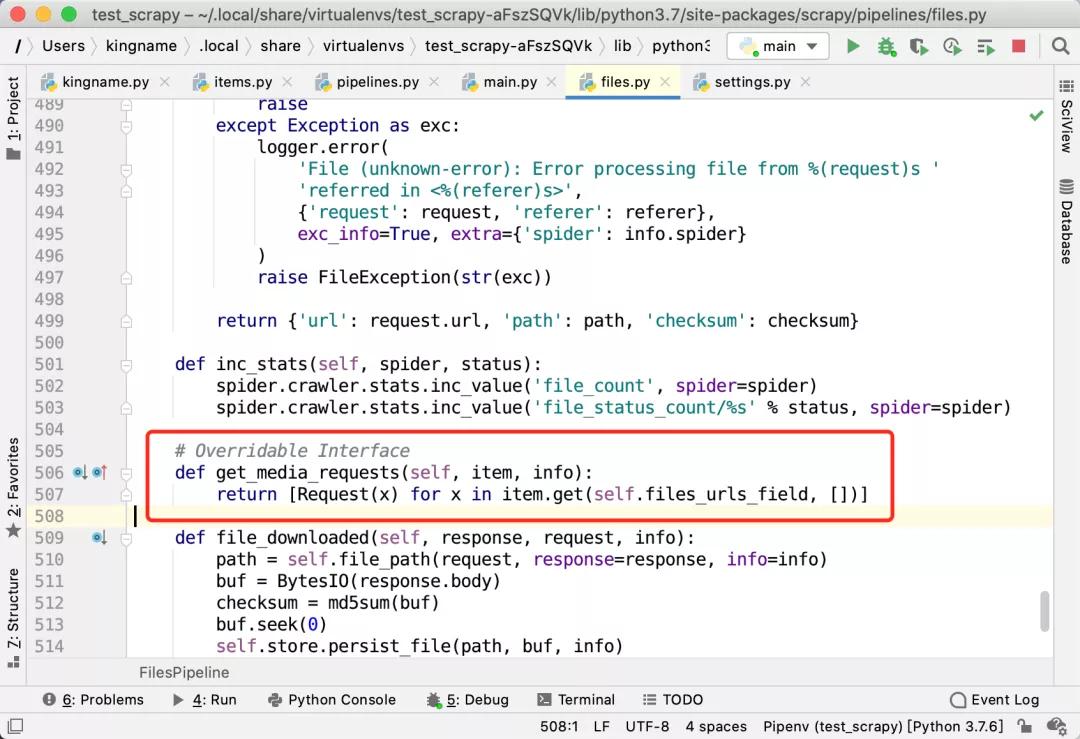
在 scrapy/pipelines/files.py文件中,可以看到,FilesPipeline是通過get_media_requests方法來構造對圖片的請求對象的。這個請求對象沒有設置任何的請求頭。
上面的截圖是老版本的 Scrapy 的源代碼。新版本的源代碼里面,get_media_requests可能是這樣的:
- def get_media_requests(self, item, info):
- urls = ItemAdapter(item).get(self.files_urls_field, [])
- return [Request(u) for u in urls]
為了手動加上請求頭,我們可以自己寫一個 pipeline,繼承FilesPipeline但覆蓋get_media_requests方法,如下圖所示:
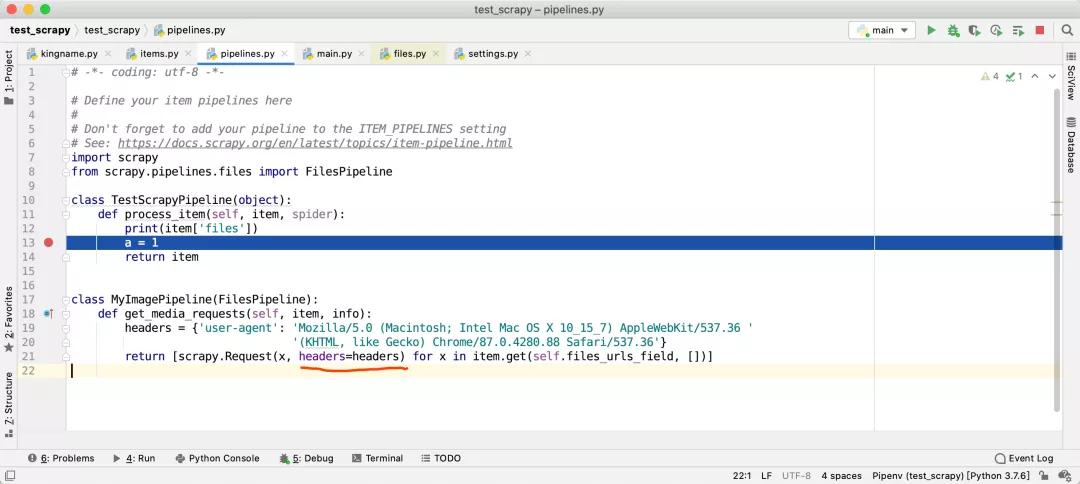
注意,在實際使用中,你可能還要加上 Host 和 Referer。
然后修改settings.py中的ITEM_PIPELINES,指向我們自定義的這個pipeline:
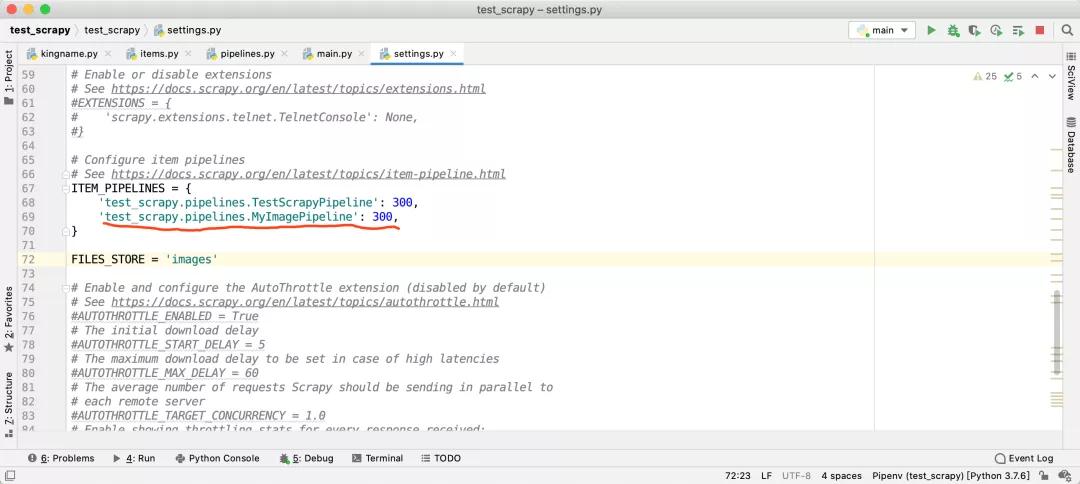
這樣一來,FilesPipeline就能夠正確加上請求頭了。
最后考大家一個問題,FilesPipeline發起的請求,會經過下載器中間件嗎?如果要添加代理 IP 應該怎么做?歡迎大家在本文下面評論回復。
參考資料
[1]官方文檔: https://docs.scrapy.org/en/latest/topics/media-pipeline.html#using-the-files-pipeline
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。