AI如何超越人類修圖師?萬字長文看懂美圖云修AI修圖解決方案
近日,美圖推出了全新的人工智能修圖解決方案——美圖云修,本文將從技術(shù)角度深入解讀該方案,目前用戶也可通過美圖 AI 開放平臺進(jìn)行體驗。
商業(yè)攝影的工作流程中非常重要的一項是「后期修圖」,它工作量大、周期長,同時,培養(yǎng)一名「下筆如有神」的修圖師往往需要付出高昂的人力和物力成本,即便是熟練的修圖師也需要 1-3 個月的時間熟悉和適應(yīng)不同影樓的修圖風(fēng)格和手法。除此之外,修圖師的專業(yè)水平不同,審美差異、工作狀態(tài)好壞等因素都會造成修圖質(zhì)量波動。
針對以上痛點,基于美圖成立 12 年來在人物影像領(lǐng)域積累的技術(shù)優(yōu)勢,美圖技術(shù)中樞——美圖影像實驗室(MTlab)推出美圖云修人工智能修圖解決方案。修圖過程中,AI 技術(shù)在實現(xiàn)多場景的自適應(yīng)識別調(diào)參,呈現(xiàn)完美光影效果的同時,還能夠快速定位人像,修復(fù)人像瑕疵,實現(xiàn)人像的個性化修圖。

圖 1. 美圖云修人像精修對比
接下來,本文將重點分析美圖云修人工智能修圖解決方案的技術(shù)細(xì)節(jié)。
智能中性灰技術(shù)
在修圖中經(jīng)常提到中性灰修圖,也稱 “加深減淡” 操作,通過畫筆來改變局部的深淺,在 PS 中需要手動建立一個觀察圖層,用以凸顯臉部瑕疵,如斑點、毛孔、痘印等,然后在觀察圖層中逐一選取瑕疵區(qū)域?qū)υ四槍?yīng)瑕疵區(qū)域進(jìn)行祛除,在此之后對膚色不均勻的地方抹勻,最大限度地保留皮膚質(zhì)感,但不少情況下仍需借助磨皮方法讓膚色均勻,但磨皮會丟失皮膚質(zhì)感。對每張人像圖的皮膚區(qū)域重復(fù)該過程,可謂耗時耗力。傳統(tǒng) PS 中性灰的修圖過程如圖 2 所示。

圖 2. PS 中性灰修圖圖層(左:原圖,中:觀察組,右:圖層)
美圖云修的智能中性灰人像精修功能結(jié)合了自注意力模塊和多尺度特征聚合訓(xùn)練神經(jīng)網(wǎng)絡(luò),進(jìn)行極致特征細(xì)節(jié)提取,智能中性灰精修方案使沒有專業(yè)修圖技術(shù)的人也可以對人像進(jìn)行快速精修,在速度方面遠(yuǎn)超人工修圖方式,并且保持了資深人工修圖在效果上自然、精細(xì)的優(yōu)點,在各種復(fù)雜場景都有較強的魯棒性,極大地提升了人像后期處理的工作效率。如圖 3 所示,為智能中性灰修圖效果,無需手動操作,相比于目前各個 app 上的修圖效果,如圖 4 所示,有著更好的祛除瑕疵效果,并保留皮膚質(zhì)感,不會有假面磨皮感。

圖 3. 美圖云修 AI 中性灰精修效果對比

圖 4. 友商祛斑祛痘及磨皮效果(左:祛斑祛痘,右:磨皮)
AI 中性灰精修功能采用創(chuàng)新的深度學(xué)習(xí)結(jié)構(gòu),如圖 5 所示,在網(wǎng)絡(luò)編碼器到解碼器的連接部分加入雙重自注意力特征篩選模塊和多尺度特征聚合模塊,讓網(wǎng)絡(luò)可以學(xué)習(xí)豐富的多尺度上下文特征信息,并對重要信息附加權(quán)重,讓圖像在高分辨率的細(xì)節(jié)得以保留,同時更好地修復(fù)問題膚質(zhì)。
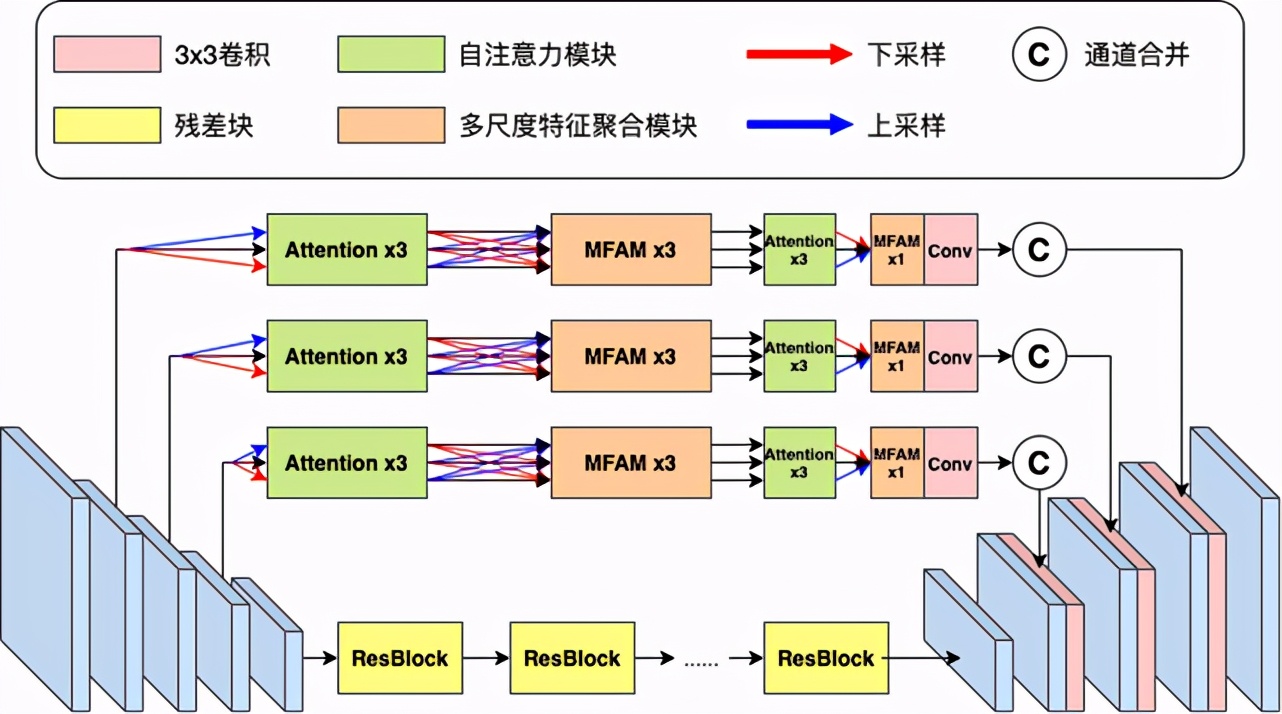
圖 5. 智能中性灰精修網(wǎng)絡(luò)結(jié)構(gòu)
雙重自注意力特征篩選模塊
雙重自注意力特征篩選模塊 [1] 是對特征圖的空間映射和通道映射進(jìn)行學(xué)習(xí),分為基于位置的自注意力模塊和基于通道的自注意力模塊,最后通過整合兩個模塊的輸出來得到更好的特征表達(dá),如圖 6 所示。
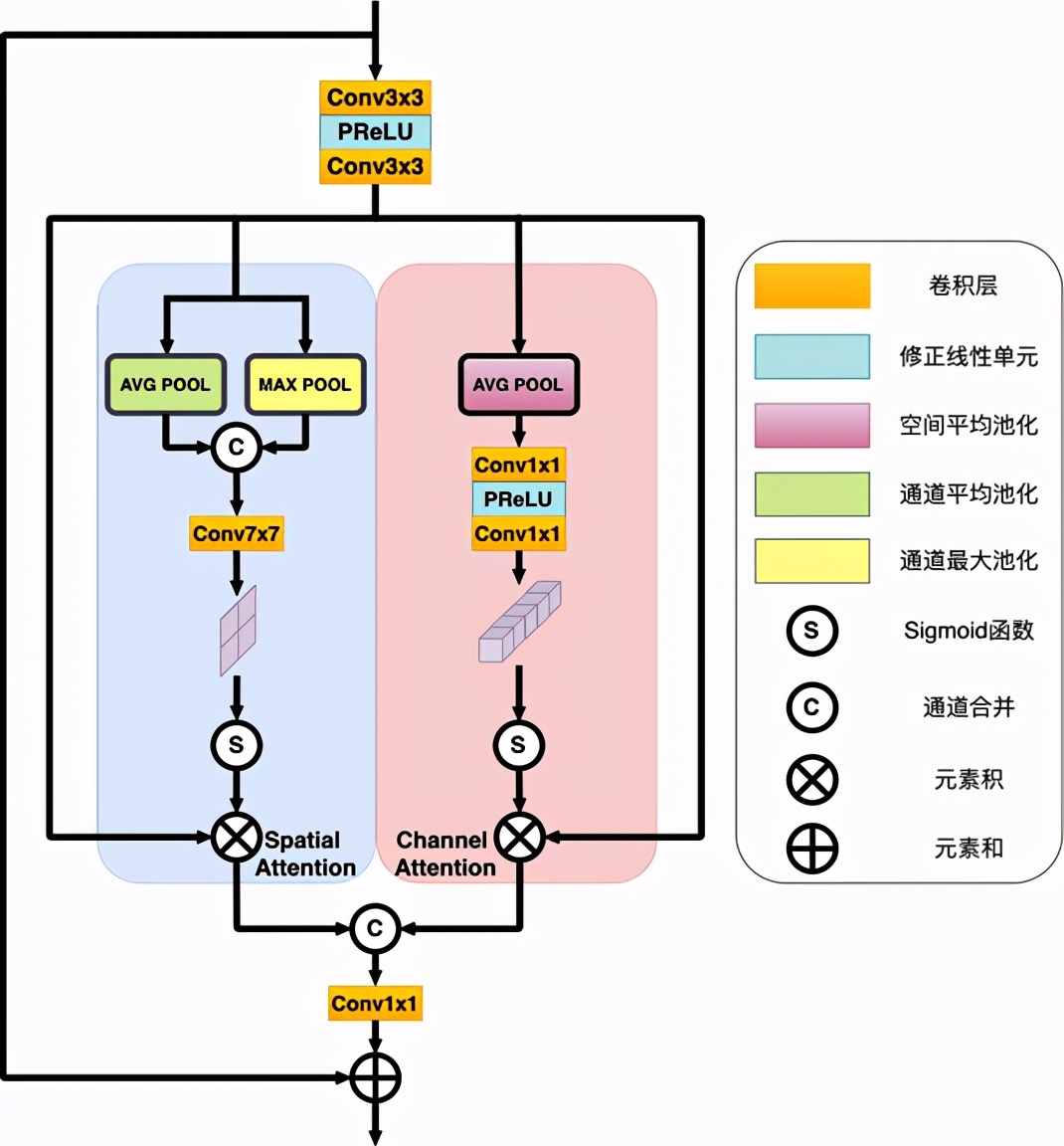
圖 6. 雙重自注意力模塊結(jié)構(gòu)
基于位置的自注意力模塊用于獲悉特征圖中的任意兩個像素的空間依賴,對于某個特殊的膚質(zhì)特征,會被所有位置上的特征加權(quán),并隨著網(wǎng)絡(luò)訓(xùn)練而更新權(quán)重。任意兩個具有相似膚質(zhì)特征的位置可以相互貢獻(xiàn)權(quán)重,由此模塊通過學(xué)習(xí)能夠篩選出膚質(zhì)細(xì)節(jié)變化的位置特征。如圖 6 左邊藍(lán)色區(qū)域所示,輸入一個特征圖 F∈ R^(H×W×C),首先對該特征圖分別沿通道維度進(jìn)行全局平均池化和全局最大池化,得到兩個基于通道的描述并合并得到特征圖 F_Channel ∈ R^(H×W×2)。再經(jīng)過一個 7x7 的卷積層和 Sigmoid 激活函數(shù),得到空間權(quán)重系數(shù) M_S ∈ R^(H×W),可以由以下公式表示:
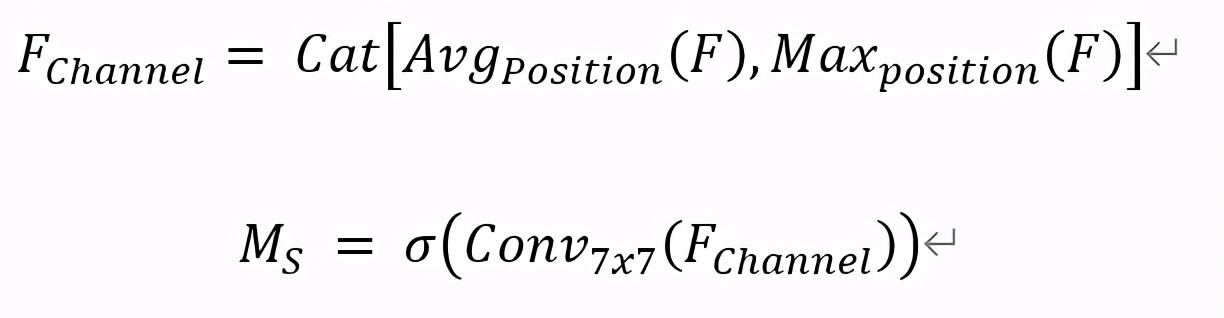
其中 σ 表示 Sigmoid 激活函數(shù), Conv_7x7 表示 7x7 卷積, Cat[]表示通道合并。
最后,將空間權(quán)重系數(shù) M_S 對特征圖 F 進(jìn)行重新校準(zhǔn),即兩者相乘,就可以得到空間加權(quán)后的新膚質(zhì)特征圖。
基于通道的自注意力模塊主要關(guān)注什么樣的通道特征是有意義的,并把那些比較有意義的特征圖通道通過加權(quán)進(jìn)行突出體現(xiàn)。高層特征的通道都可以看作是特定于膚質(zhì)細(xì)節(jié)信息的響應(yīng),通過學(xué)習(xí)通道之間的相互依賴關(guān)系,可以強調(diào)相互依賴的特征映射,從而豐富特定語義的特征表示。如圖 6 右邊紅色區(qū)域所示,輸入與基于位置的膚質(zhì)細(xì)節(jié)篩選模塊相同的特征圖 F∈ R^(H×W×C),對該特征圖沿空間維度進(jìn)行全局平均池化,得到給予空間的描述特征圖 F_Spatial ∈ R^(1×1×C),再把 F_Spatial 輸入由兩個 1x1 卷積層組成表示的多層感知機。為了減少參數(shù)開銷,感知機隱層激活的尺寸設(shè)置為 R^(C/r×1×1),其中 r 是通道降比。這樣第一層卷積層輸出通道為 C/r,激活函數(shù)為 PReLU,第二層卷積層輸出通道恢復(fù)為 C。
再經(jīng)過 Sigmoid 激活函數(shù),得到通道權(quán)重系數(shù) M_C ∈ R^(C×1×1),由以下公式表示:
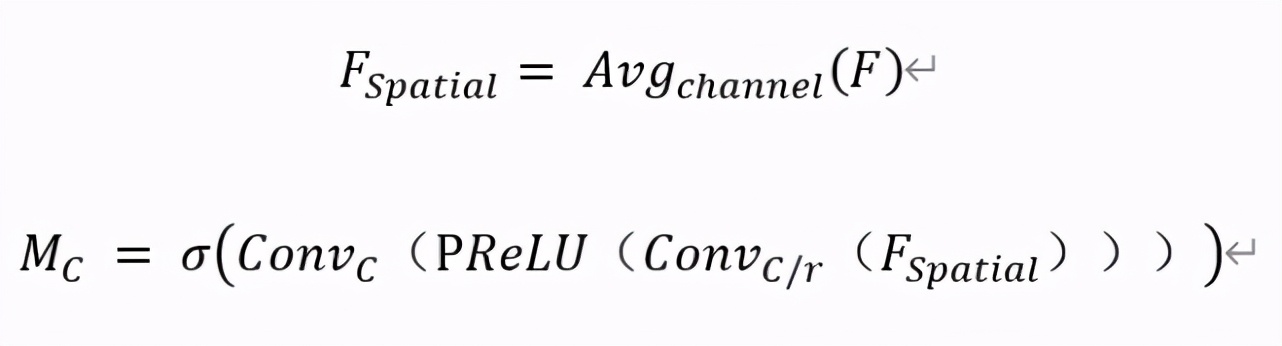
其中 σ 表示 Sigmoid 激活函數(shù), Conv_C ∈ R^(C×C/r) 和 Conv_(C/r) ∈ R^(C/r×C) 表示感知機對應(yīng)的兩層, PReLU 表示感知機中間的線性修正單元激活函數(shù)。
相同地,將通道權(quán)重系數(shù) M_S 和特征圖 F 相乘,就可以得到通道加權(quán)后的新特征圖。將空間加權(quán)特征圖和通道加權(quán)特征圖進(jìn)行通道合并,經(jīng)過一個 1x1 卷積后與輸入自注意力模塊前的特征圖相加,就可以得到矯正后的最終特征圖。
多尺度特征聚合模塊
多尺度特征聚合模塊 [2] 的作用是對特征感受野進(jìn)行動態(tài)修正,不同尺度的前后層特征圖輸入模塊,通過整合并賦予各自的權(quán)重,最終將這些特征進(jìn)行聚合,輸出更為豐富的全局特征,這些特征帶有來自多個尺度的上下文信息。
如圖 7 所示,以三個不同尺度輸入模塊為例,模塊先使用 1x1 卷積和 PReLU 將上層 L_1 和下層 L_3 的特征通道變換為和當(dāng)前層 L_2 ∈ R^(H×W×C) 一致,再通過元素和的方式將特征聚合成 L_C=L_1+ L_2+ L_3,然后經(jīng)過一個空間維度的全局平均池化得到基于通道的統(tǒng)計 S ∈ R^(1×1×C),之后為了降低計算量經(jīng)過一個 C/r 的 1x1 卷積和 PReLU 激活函數(shù),生成一個壓縮的特征表示 Z∈ R^(1×1×r),r 與自注意力特征篩選模塊一致。這里讓 Z 經(jīng)過與尺度數(shù)量相同的平行卷積層,得到對應(yīng)的特征描述向量 v_1、v_2 和 v_3, v_i ∈ R^(1×1×C)。將這些特征描述向量合并,再經(jīng)過 Softmax 激活函數(shù),得到各個尺度特征通道的校正系數(shù) s_1、s_2 和 s_3, s_i ∈ R^(1×1×C)。將特征通道系數(shù)與對應(yīng)尺度的特征圖相乘后再進(jìn)行聚合相加,得到最終的聚合特征 F_aggregation,表示為:
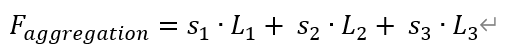
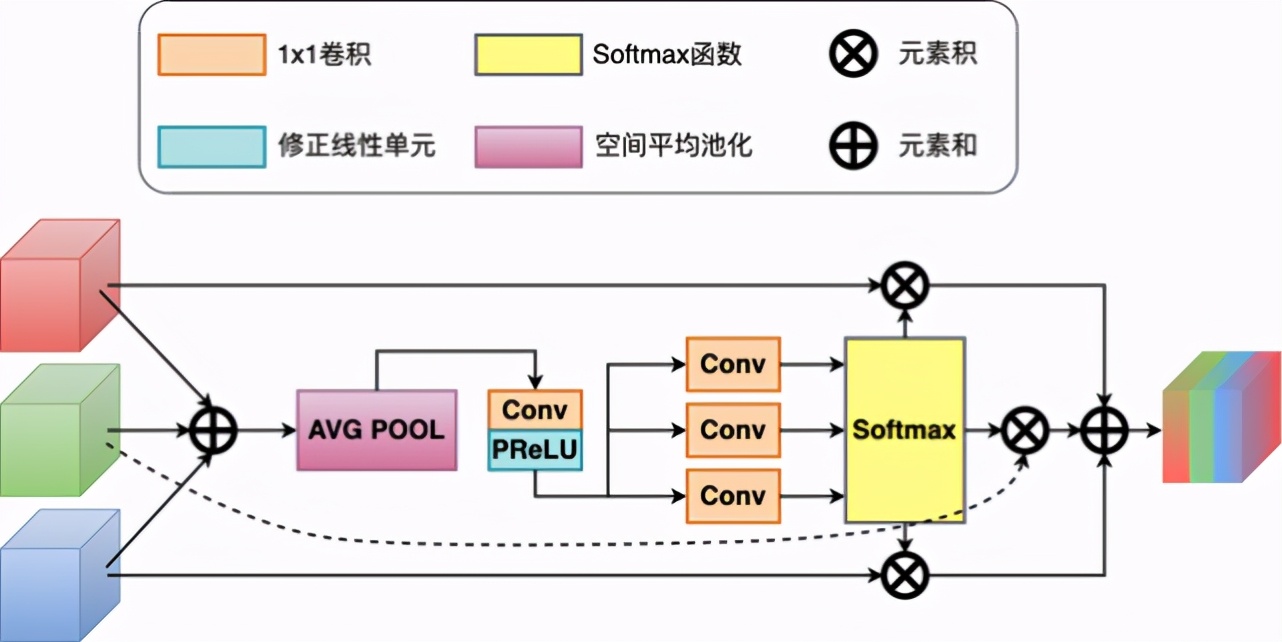
圖 7. 多尺度特征聚合模塊結(jié)構(gòu)
MTlab 所提出的 AI 中性灰精修方案通過設(shè)計有效的網(wǎng)絡(luò)結(jié)構(gòu)以及流程,結(jié)合特殊的訓(xùn)練方法,能夠便捷、精確地進(jìn)行智能中性灰人像修圖。首先,相較于磨皮等傳統(tǒng)圖像處理方法,本方案輸出的智能修圖結(jié)果精細(xì)、自然,能夠最大程度地保留人像膚質(zhì)細(xì)節(jié),對于各類復(fù)雜場景都具有更好的魯棒性;其次,相較于人工中性灰修圖,本方法能夠保證穩(wěn)定的修圖效果,同時極大縮短處理時間,從而提升影樓圖像后期處理的效率。
智能調(diào)色技術(shù)
常見修圖所涉及的調(diào)色技術(shù)主要包括去霧,光照調(diào)整和背景增強等,其中光照調(diào)整涉及過曝修復(fù)和欠曝增強。其中,去霧主要用于保持圖像的清晰度和對比度,使圖像從視覺感觀上不會存在明顯霧感;曝光主要用于改善圖像的光影效果,保證成像光影質(zhì)量,使得相片能夠呈現(xiàn)完美光影效果;而智能白平衡則是能夠還原圖像的真實色彩,保證圖像最終成像不受復(fù)雜光源影響。調(diào)色涉及的技術(shù)較多,此處以白平衡智能調(diào)整技術(shù)為例,詳細(xì)介紹 AI 技術(shù)調(diào)色流程。
目前常用白平衡算法進(jìn)行色偏校正,存在以下難點:
傳統(tǒng)白平衡算法雖然能夠校正色偏,但是魯棒性不足,無法應(yīng)對實際需求中的復(fù)雜場景,往往需要設(shè)置不同的參數(shù)進(jìn)行調(diào)整,操作繁瑣。
目前主流的色偏校正方案大多數(shù)是基于卷積神經(jīng)網(wǎng)絡(luò),而常規(guī)的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)并不能徹底校正色偏,這些方案對于與低色溫光源相近的顏色,比如木頭的顏色,會存在將其誤判為低色溫光源的現(xiàn)象。
大多數(shù)數(shù)碼相機提供了在圖像菜雞過程中調(diào)整白平衡設(shè)置的選項。但是,一旦選擇了白平衡設(shè)置并且 ISP 將圖像完全處理為最終的 sRGB 編碼,就很難在不訪問 RAW 圖像的情況下執(zhí)行 WB 編輯,如果白平衡設(shè)置錯誤,此問題將變得更加困難,從而導(dǎo)致最終 sRGB 圖像中出現(xiàn)強烈的偏色。
美圖影像實驗室 MTlab 自主研發(fā)了一套專門能夠適應(yīng)多場景復(fù)雜光源下的智能調(diào)色技術(shù)。傳統(tǒng)白平衡算法的核心是通過實時統(tǒng)計信息,比照傳感器的先驗信息,計算出當(dāng)前場景的光源,通過傳感器先驗信息做白平衡,這種方法仍然有很多局限。MTlab 提出的智能白平衡方案(AWBGAN),依靠海量場景的無色偏真實數(shù)據(jù),能夠?qū)崿F(xiàn)自適應(yīng)的光源估計,完成端到端的一站式調(diào)色服務(wù)。AWBGAN 滿足以下 2 個特點:
- 全面性:多場景多光源,涵蓋常見場景進(jìn)行多樣化處理。
- 魯棒性:不會存在場景以及光源誤判問題,色偏校正后不會造成二次色偏。
當(dāng)前的主流算法主要是集中在 sRGB 顏色域上進(jìn)行色偏校正,但是這樣處理并不合理。因為相機傳感器在獲取原始的 RAW 圖像再到最終輸出 sRGB 圖像,中間經(jīng)過一系列的線性以及非線性映射處理,例如曝光校正,白平衡以及去噪等處理流程。ISP 渲染從白平衡過程開始,該過程用于消除場景照明的偏色。然后,ISP 進(jìn)行了一系列的非線性顏色處理,以增強最終 sRGB 圖像的視覺質(zhì)量。由于 ISP 的非線性渲染,使用不正確的白平衡渲染的 sRGB 圖像無法輕松校正。為此 MTlab 設(shè)計了 AWBGAN 訓(xùn)練學(xué)習(xí)網(wǎng)絡(luò)來完成色偏校正。
針對一張待校正色偏的圖像,首先需要使用已經(jīng)訓(xùn)練好的場景分類模型進(jìn)行場景判定,獲得校正系數(shù),該校正系數(shù)將會用于 AWBGAN 的校正結(jié)果,能在校正結(jié)果的基礎(chǔ)上進(jìn)行動態(tài)調(diào)整。對于高分辨率圖像如果直接進(jìn)行色偏校正處理,耗時高。為了提高計算效率,MTlab 會將待校正色偏圖像采樣到一定尺度再進(jìn)行校正操作,最后再將結(jié)果使用金字塔操作逆向回原圖尺寸。完整的校正流程如圖 8 所示。
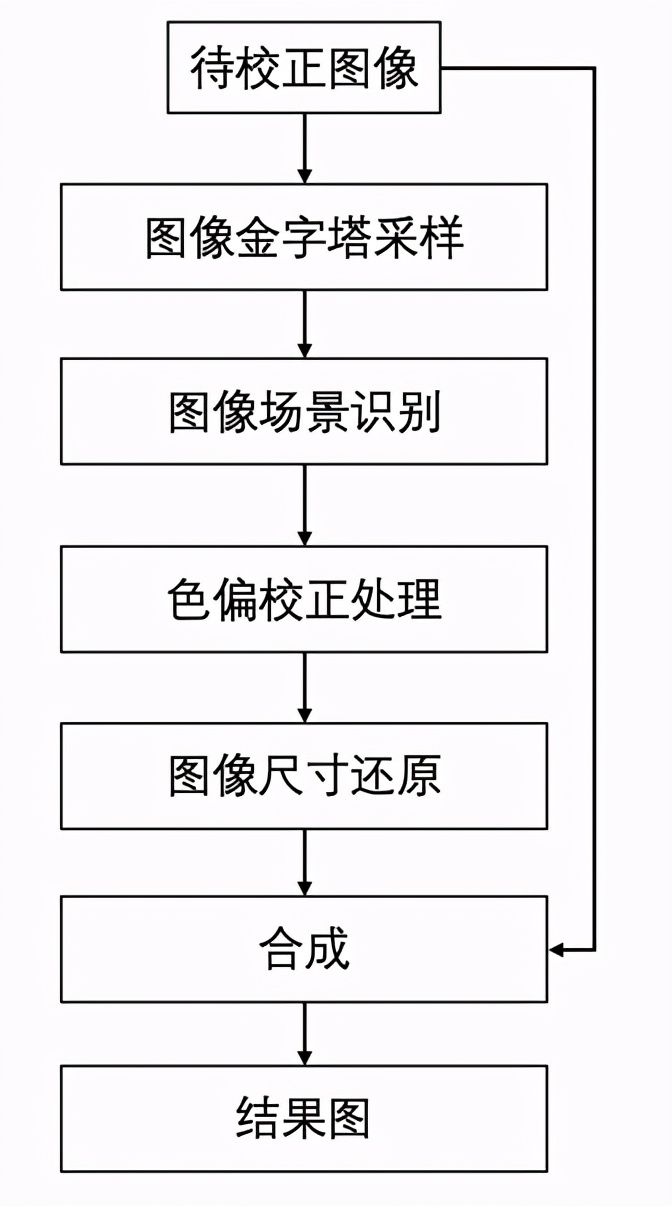
圖 8. 色偏校正方案整體流程
生成網(wǎng)絡(luò)的設(shè)計
上文中提到在 sRGB 圖像上直接進(jìn)行處理并沒有在 Raw 圖上處理效果好,因此生成器采用類 U-Net 網(wǎng)絡(luò)結(jié)構(gòu)模擬 sRGB 到 RAW 再轉(zhuǎn)換回 sRGB 的非線性映射過程,其中編碼器將 sRGB 逆向還原回 RAW 圖并進(jìn)行 RAW 圖上的色偏校正,在完成正確的白平衡設(shè)置后,解碼器進(jìn)行解碼,生成使用了正確白平衡設(shè)置的 sRGB 圖像。整個 G 網(wǎng)絡(luò)的目的不是將圖像重新渲染會原始的 sRGB 圖,而是在 RAW 上使用正確的白平衡設(shè)置生成無色偏圖像。鑒于直接使用原始的 U-Net 網(wǎng)絡(luò)生成的圖像會存在色彩不均勻的問題,G 網(wǎng)絡(luò)參考 U-Net 以及自主研發(fā)的方案做了一些調(diào)整:
在編碼器與解碼器之間加入另外一個分支,使用均值池化代替全連接網(wǎng)絡(luò)提取圖像的全局特征從而解決生成圖像存在色塊和顏色過度不均勻的問題;
使用 range scaling layer 代替 residuals,也就是逐個元素相乘,而不是相加,學(xué)習(xí)范圍縮放層(而不是殘差)對于感知圖像增強效果非常好;
為了減少生成圖像的棋盤格偽影,將解碼器中的反卷積層替換為一個雙線性上采樣層和一個卷積層。
生成網(wǎng)絡(luò)結(jié)構(gòu)如圖 9 所示,提取全局特征的網(wǎng)絡(luò)分支具體結(jié)構(gòu)如圖 10 所示。
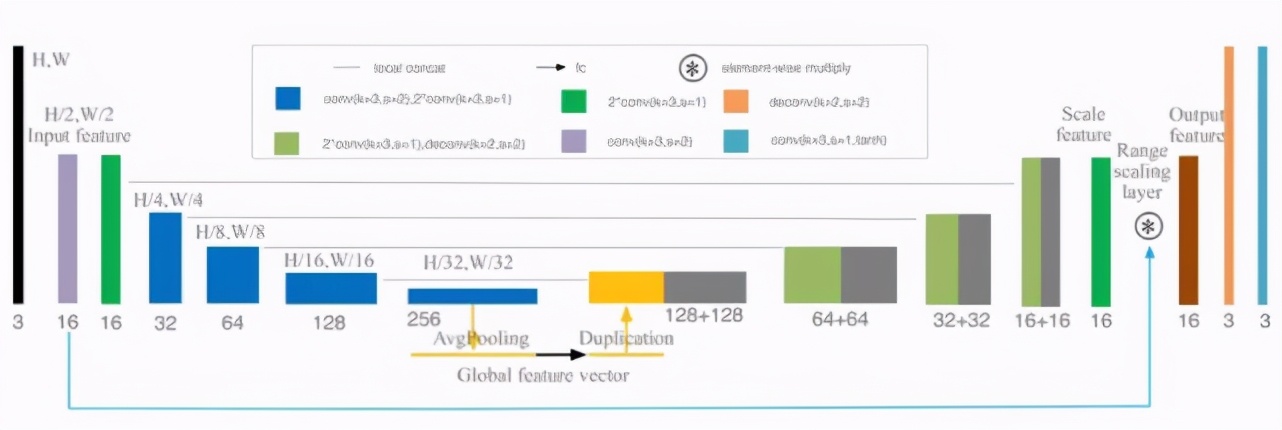
圖 9. 生成網(wǎng)絡(luò)結(jié)構(gòu)圖
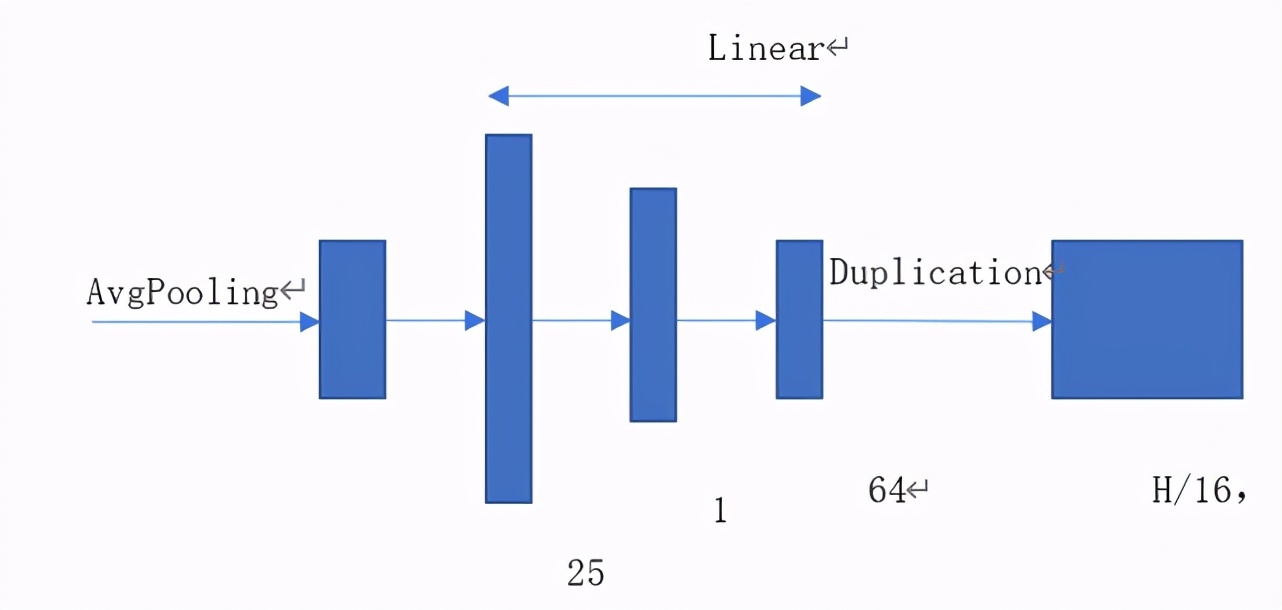
圖 10. 全局分支網(wǎng)絡(luò)結(jié)構(gòu)
判別器設(shè)計
為了能夠獲得更加逼近真實結(jié)果的圖像,此處采用了對抗性損失來最小化實際光分布和輸出正態(tài)光分布之間的距離。但是一個圖像級的鑒別器往往不能處理空間變化的圖像,例如輸入圖像是在室內(nèi)復(fù)雜光源場景下獲取的,受到室內(nèi)光源漫反射的影響,每個區(qū)域需要校正的程度不同,那么單獨使用全局圖像判別器往往無法提供所需的自適應(yīng)能力。
為了自適應(yīng)地校正局部區(qū)域色偏,MTlab 采用文獻(xiàn)[4]EnlightenGAN 中的 D 網(wǎng)絡(luò)。該結(jié)構(gòu)使用 PatchGAN 進(jìn)行真假鑒別。判別器包含全局以及局部兩個分支,全局分支判斷校正圖像的真實性,局部分支從輸入圖像隨機剪裁 5 個 patch 進(jìn)行判別,改善局部色偏校正效果。D 網(wǎng)絡(luò)的輸入圖像與 target 圖像,都會從 RGB 顏色域轉(zhuǎn)換成 LAB 顏色域,Lab 是基于人對顏色的感覺來設(shè)計的,而且與設(shè)備無關(guān),能夠,使用 Lab 進(jìn)行判別能夠獲得相對穩(wěn)定的效果。全局 - 局部判別器網(wǎng)絡(luò)結(jié)構(gòu)如圖 11 所示。
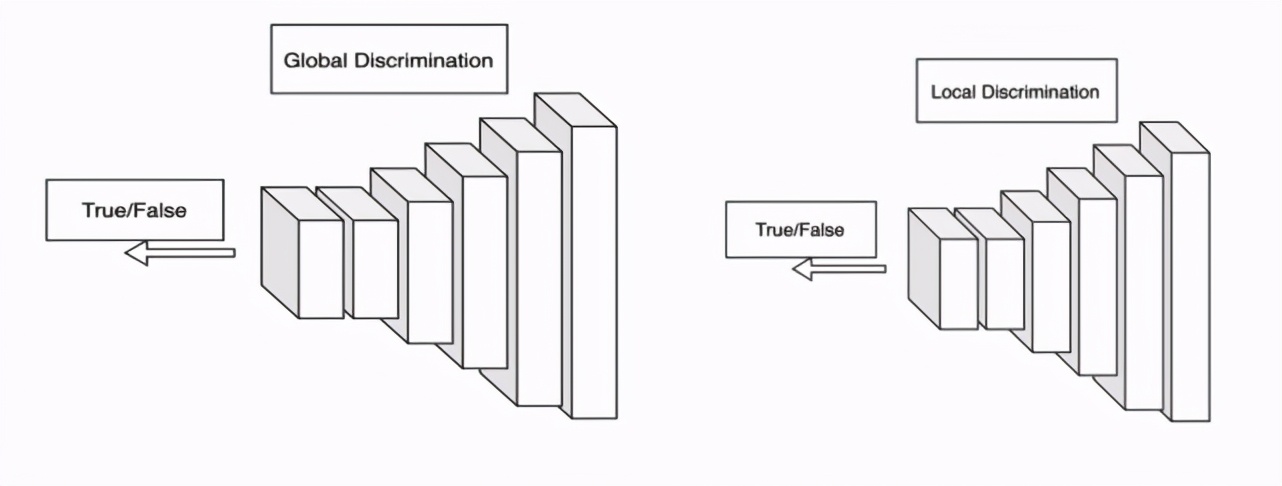
圖 11. 全局 - 局部判別器
Loss 函數(shù)的設(shè)計包括 L1 loss, MS-SSIM loss, VGG loss, color loss and GAN loss。其中 L1 loss 保證圖像的色彩亮度的真實性;MS-SSIM loss 使得生成圖像不會丟失細(xì)節(jié),保留結(jié)構(gòu)性信息,VGG loss 限制圖像感知相似性;color loss 分別將增強網(wǎng)絡(luò)得到 image 與 target 先進(jìn)行高斯模糊,也就是去掉部分的邊緣細(xì)節(jié)紋理部分,剩下的能作為比較的就是對比度以及顏色;GAN loss 確保圖像更加真實。這五個 loss 相加就構(gòu)成了 AWBGAN 的損失函數(shù)。
最終色偏校正方案的校正效果如圖 12 所示。

圖 12. 美圖云修智能白平衡結(jié)果。(左:色溫 6500K 情況,中:色溫 2850K 情況,右:校正后圖像)
智能祛除技術(shù)
修圖師在修圖過程中,會祛除一些皮膚本身固有的瑕疵,如皺紋、黑眼圈、淚溝等。對于人工智能的后期人像修圖來說,皺紋檢測有著重要的現(xiàn)實意義:一方面有助于皮膚衰老度的分析,揭示皺紋發(fā)生的區(qū)域和嚴(yán)重程度,成為評估膚齡的依據(jù);另一方面,則能為圖像中的自動化人臉祛皺帶來更便捷的體驗,即在后期修圖的過程中,用戶可以利用算法自動快速定位皺紋區(qū)域,從而告別繁復(fù)的手工液化摸勻的過程。
1. 皺紋識別
在科研領(lǐng)域中,常用的皺紋檢測算法主要有以下幾種:
- 基于一般邊緣檢測的方法:比如常見的 Canny 算子、Laplace 算子、DoG 算子,但這些算子所檢出的邊緣實質(zhì)上是圖像中兩個灰度值有一定差異的平坦區(qū)域之間的分界處,而不是皺紋的凹陷處,故不利于檢出具有一定寬度的皺紋;
- 基于紋理提取的方法:有以文獻(xiàn) [5] 的 Hybrid Hessian Filter(HHF)以及文獻(xiàn) [6] 的 Hessian Line Tracking (HLT)為代表的,基于圖像 Hessian 矩陣的特征值做濾波的方法,可用來提取圖像中的線性結(jié)構(gòu);也有以文獻(xiàn) [7] 的 Gabor Filter Bank 為代表的,利用在提取線性紋理的 Gabor 濾波的方法。這些方法需要手工設(shè)計濾波器,帶來了額外的調(diào)參代價,而且通常只能檢測線狀的抬頭紋和眼周紋,對于溝狀的法令紋的兼容較差,檢測結(jié)果也容易受到其他皮膚紋理或非皮膚物體的影響;
- 基于 3D 掃描的方法:如文獻(xiàn) [8] 提出的利用 3D 點云的深度信息映射到 2D 圖像的分析方法,但該方法依賴于額外的采集設(shè)備,在算法的普適性上較弱。
在自動化人臉祛皺的需求引領(lǐng)下,為了擺脫傳統(tǒng)皺紋檢測算法的限制,美圖影像實驗室 MTlab 自主研發(fā)了一套全臉 (含脖子) 皺紋檢測技術(shù)。該技術(shù)在覆蓋全年齡段的真實人臉皺紋數(shù)據(jù)的驅(qū)動之下,發(fā)揮了深度學(xué)習(xí)表征能力強和兼容性高的優(yōu)勢,實現(xiàn)了端到端的抬頭紋、框周紋、法令紋和頸紋的精準(zhǔn)分割,成為了自動化祛皺算法的關(guān)鍵一環(huán)。
由于抬頭紋、框周紋、法令紋和頸紋這四類皺紋的類內(nèi)模式相似性較高而類間模式相似較低,MTlab 采用零件化的思想,將全臉皺紋檢測任務(wù)分解成四個互相獨立的子任務(wù),分別對上述的四類皺紋進(jìn)行檢測。在四類皺紋的人臉區(qū)域定位上, MTlab 的人臉語義關(guān)鍵點檢測技術(shù)發(fā)揮了重要作用。在不同拍攝場景以及人臉姿態(tài)下,該技術(shù)都能正確劃分額頭、眼周、臉頰和頸部區(qū),從而為皺紋檢測任務(wù)提供了穩(wěn)定可靠的輸入來源。MTlab 還利用眼周和臉頰區(qū)域的左右對稱性,在進(jìn)一步減少網(wǎng)絡(luò)輸入尺寸的同時,也讓網(wǎng)絡(luò)在模式學(xué)習(xí)上變得更簡單。
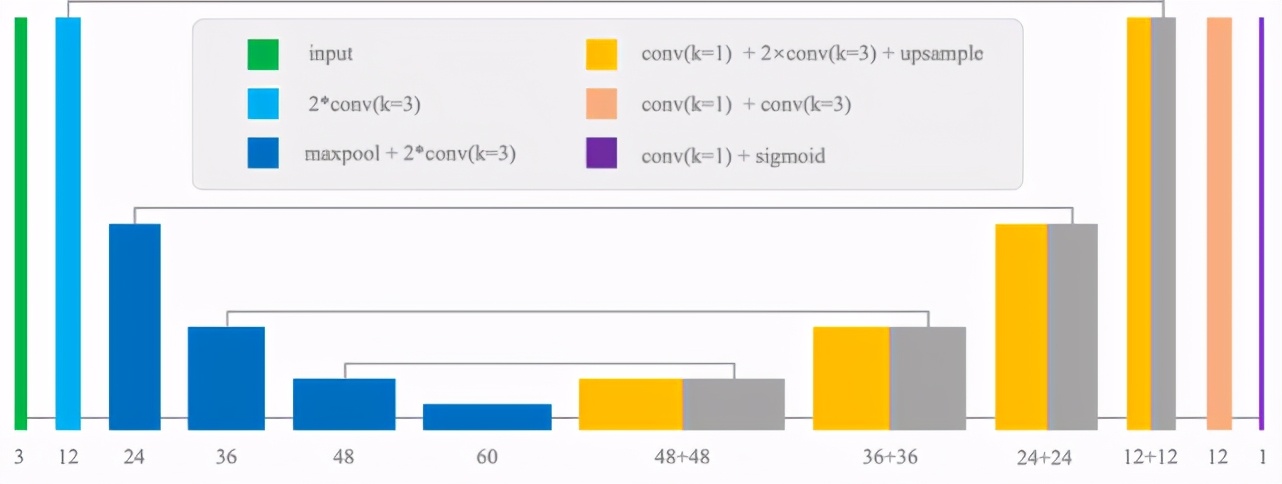
圖 13. 皺紋檢測網(wǎng)絡(luò)結(jié)構(gòu)圖
類 U-Net 的網(wǎng)絡(luò)結(jié)構(gòu)在圖像特征編碼和高低層語義信息融合上有著先天的優(yōu)勢,故受到許多分割任務(wù)的青睞。鑒于皺紋檢測本質(zhì)也是分割任務(wù),MTlab 也在 U-Net 的基礎(chǔ)上進(jìn)行網(wǎng)絡(luò)設(shè)計,并做了以下調(diào)整:
- 保留了編碼器淺層的高分辨率特征圖,并將其與解碼器相同尺度的特征圖進(jìn)行信息融合:有助于引導(dǎo)解碼器定位皺紋在圖像中的位置,提升了寬度較細(xì)的皺紋檢出率;
- 將解碼器中的反卷積層替換為一個雙線性上采樣層和一個卷積層:避免分割結(jié)果的格狀邊緣效應(yīng),讓網(wǎng)絡(luò)輸出的結(jié)果更貼合皺紋的原始形狀。
- 皺紋檢測的 loss 需要能起到真正監(jiān)督的作用,為此總體的 loss 由兩部分組合而成:Binary Cross Entropy Loss 以及 SSIM Loss。Binary Cross Entropy Loss 是分割任務(wù)的常用 loss,主要幫助網(wǎng)絡(luò)區(qū)分前景像素和背景像素;SSIM Loss 則更關(guān)注網(wǎng)絡(luò)分割結(jié)果與 GT 的結(jié)構(gòu)相似性,有助于網(wǎng)絡(luò)學(xué)習(xí)一個更準(zhǔn)確的皺紋形態(tài)。
2. 皺紋自動祛除
皺紋祛除主要是基于圖片補全實現(xiàn),將皺紋部分作為圖片中的待修復(fù)區(qū)域,借助圖片補全技術(shù)重新填充對應(yīng)像素。目前,圖片補全技術(shù)包含傳統(tǒng)方法和深度學(xué)習(xí)兩大類:
- 傳統(tǒng)圖片補全技術(shù),這類方法無需數(shù)據(jù)訓(xùn)練,包括基于圖片塊 (patch)[9,11] 和基于像素 [2] 這兩類補全方法。這兩類方法的基本思想是根據(jù)一定的規(guī)則逐步的對圖像中的受損區(qū)域進(jìn)行填充。此類方法速度快,但需要人工劃定待修復(fù)區(qū)域,適用于小范圍的圖像修復(fù),受損區(qū)域跨度較大時容易出現(xiàn)模糊和填充不自然的情況。
- 基于深度學(xué)習(xí)的 Inpainting 技術(shù) [12,13,14,15],這類方法需收集大量的圖片數(shù)據(jù)進(jìn)行訓(xùn)練。基本思想是在完整的圖片上通過矩形(或不規(guī)則圖形) 模擬受損區(qū)域,以此訓(xùn)練深度學(xué)習(xí)模型。現(xiàn)有方法的缺陷在于所用數(shù)據(jù)集及假定的受損區(qū)域與實際應(yīng)用差異較大,應(yīng)用過程易出現(xiàn)皺紋無法修復(fù)或是紋理不清,填充不自然的情況。
鑒于影樓用戶對于智能修圖的迫切需求,美圖影像實驗室 MTlab 自主研發(fā)了一套能夠適應(yīng)復(fù)雜場景的的皺紋祛除方案。MTlab 提出的智能皺紋祛除方案,依靠海量場景的真實數(shù)據(jù),在識別皺紋線的基礎(chǔ)上借助 Inpainting 的深度學(xué)習(xí)網(wǎng)絡(luò)予以消除,提供端到端的一鍵式祛除皺紋,使其具備以下 2 個效果:
- 一致性:填充區(qū)域紋理連續(xù),與周圍皮膚銜接自然。
- 魯棒性:受外部環(huán)境影響小,效果穩(wěn)定。
MTlab 針對該問題收集的海量數(shù)據(jù)集能夠涵蓋日常生活場景中的多數(shù)場景光源,賦能模型訓(xùn)練最大驅(qū)動力,保障模型的性能,較好的解決了上述問題,并成功落地于應(yīng)用場景。
針對現(xiàn)有方案存在的缺陷,MTlab 根據(jù)皺紋的特點設(shè)計了皺紋祛除模型(WrinkleNet)。將原始圖片和皺紋 mask 同時送入祛除模型,即可以快速的完成祛除,并且保持了資深人工修圖在效果上自然、精細(xì)的優(yōu)點,在各種復(fù)雜場景都有較強的魯棒性,不僅對臉部皺紋有效,同時也可用于其他皮膚區(qū)域(如頸部)的皺紋祛除,其核心流程如圖 14 所示。
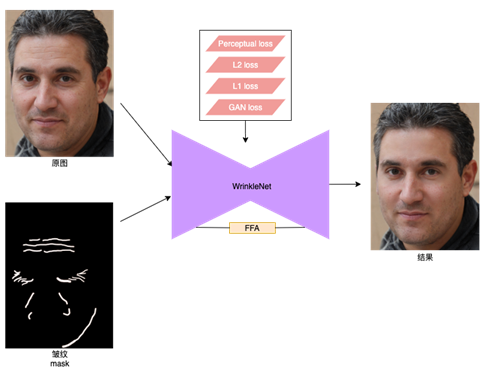
圖 14. 祛皺核心流程
數(shù)據(jù)集制作:
如前所述,數(shù)據(jù)集會極大的影響深度學(xué)習(xí)模型的最終效果,目前主流的圖像補全模型多采用開源數(shù)據(jù)集,使用矩形或不規(guī)則圖形模擬圖像中待補全的區(qū)域。針對皺紋祛除任務(wù)這么做是不合理的。一方皮膚區(qū)域在顏色和紋理上較圖片其他區(qū)域差異較大,另一方面皺紋多為弧形細(xì)線條,其形狀不同于已有的補齊模式(矩形、不規(guī)則圖形),這也是導(dǎo)致現(xiàn)有模型效果不夠理想的原因之一。因此,在數(shù)據(jù)集的準(zhǔn)備上,MTlab 不僅收集了海量數(shù)據(jù),對其皺紋進(jìn)行標(biāo)注,同時采用更貼近皺紋紋理的線狀圖形模擬待填充區(qū)域。
生成網(wǎng)絡(luò)設(shè)計:
生成網(wǎng)絡(luò)基于 Unet 設(shè)計,鑒于直接使用原始的 U-Net 網(wǎng)絡(luò)生成的圖像會存在紋理銜接不自然,紋理不清的問題,因此對其結(jié)構(gòu)做了一些調(diào)整。1)解碼的其輸出為 4 通道,其中一個通道為 texture 回歸,用于預(yù)測補齊后的圖片紋理;2)在 Unet 的 concat 支路加入了多特征融合注意力模塊(簡稱 FFA)結(jié)構(gòu),F(xiàn)FA 的結(jié)構(gòu)如圖 15 所示,該結(jié)構(gòu)旨在通過多層特征融合注意力模塊,如圖 16 所示,提高模型對細(xì)節(jié)紋理的關(guān)注度。
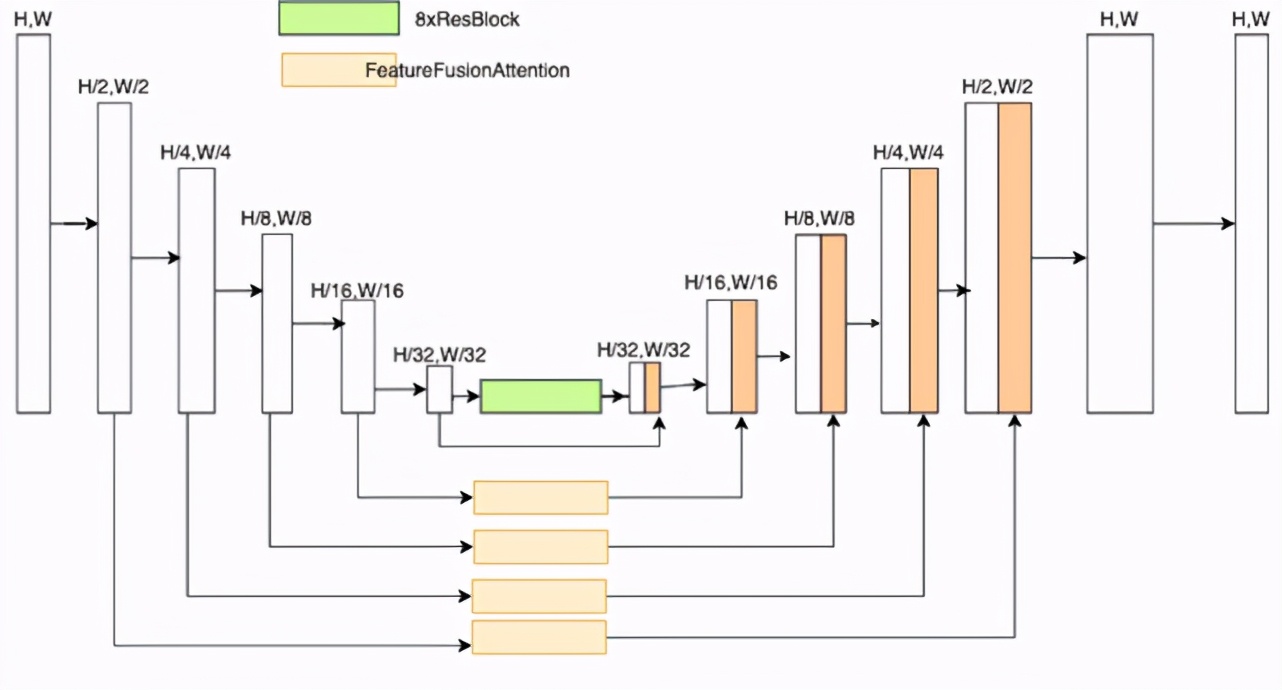
圖 15. 生成網(wǎng)絡(luò)結(jié)構(gòu)圖
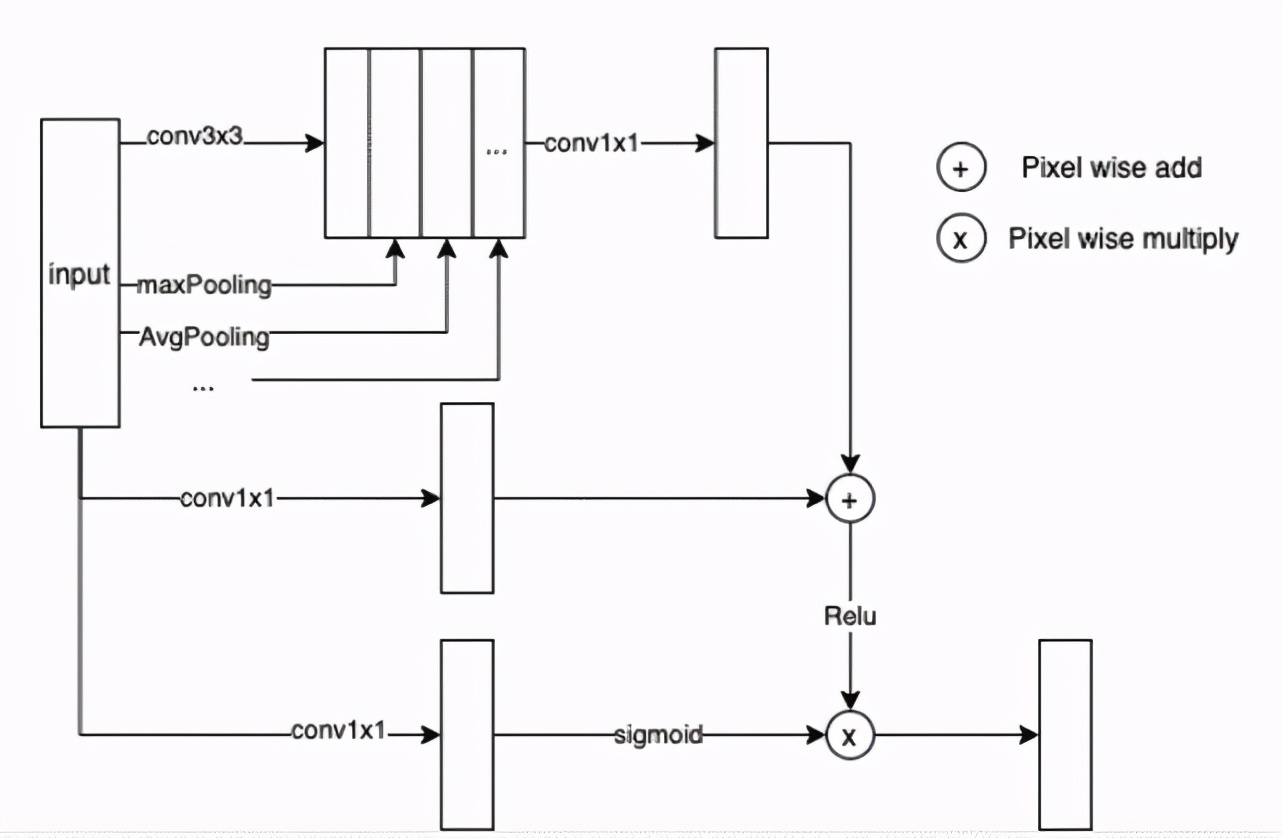
圖 16. 多特征融合注意力模塊
Loss 設(shè)計:
Loss 函數(shù)的設(shè)計包括 L1-loss, L2-loss, VGG-loss,以及 GAN-loss。其中 L1-loss 度量輸出圖像與真實圖像間的像素距離;L2-Loss 用于度量輸出紋理與真實紋理間的差異;VGG loss 限制圖像感知相似性;GAN loss 采用 PatchGAN 結(jié)構(gòu),確保圖像更加真實。這四個 loss 相加就構(gòu)成了 WrinklNet 的損失函數(shù)。
最終臉部和脖子的祛皺效果分別如圖 17 和圖 18 所示。

圖 17. 美圖云修臉部祛皺效果

圖 18. 美圖云修脖子祛皺效果
智能修復(fù)技術(shù)
在現(xiàn)實生活中,齙牙、缺牙、牙縫、牙齒畸形等等問題會讓用戶在拍照時不敢做過多如大笑等露出牙齒的表情,對拍攝效果有一定影響。美圖云修基于 MTlab 自主研發(fā)的一個基于深度學(xué)習(xí)技術(shù)的網(wǎng)絡(luò)架構(gòu),提出了全新的牙齒修復(fù)算法,可以對用戶各類不美觀的牙齒進(jìn)行修復(fù),生成整齊、美觀的牙齒,修復(fù)效果如圖 19 所示。

圖 19. 美圖云修牙齒修復(fù)效果
MTAITeeth 牙齒修復(fù)方案:
要將牙齒修復(fù)算法真正落地到產(chǎn)品層面需要保證以下兩個方面的效果:
- 真實性,生成的牙齒不僅要美觀整齊,同時也要保證生成牙齒的立體度和光澤感,使其看起來更為自然。
- 魯棒性,不僅要對大多數(shù)常規(guī)表情(如微笑)下的牙齒做修復(fù)和美化,同時也要保證算法能夠適應(yīng)某些夸張表情(如大笑、齜牙等)。
MTlab 提出的 MTAITeeth 牙齒修復(fù)算法,較好地解決了上述兩個問題,并率先將技術(shù)落地到實際產(chǎn)品中,其核心流程如圖 20 所示。
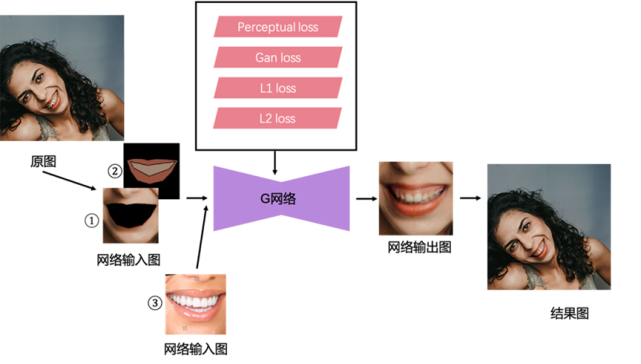
圖 20. AITeeth 牙齒修復(fù)方案流程圖
圖中所展示的流程主要包括: G 網(wǎng)絡(luò)模塊和訓(xùn)練 Loss 模塊,該方案的完整工作流程如下:
- 通過 MTlab 自主研發(fā)的人臉關(guān)鍵點檢測算法檢測出人臉點,根據(jù)人臉點判斷是否有張嘴;
- 若判定為張嘴,則裁剪出嘴巴區(qū)域并旋轉(zhuǎn)至水平,再根據(jù)人臉點計算出嘴唇 mask、牙齒區(qū)域 mask 以及整個嘴巴區(qū)域(包括嘴唇和牙齒)的 mask;
- 根據(jù)嘴巴區(qū)域的 mask 得到網(wǎng)絡(luò)輸入圖①,根據(jù)牙齒區(qū)域和嘴唇區(qū)域的 mask,分別計算對應(yīng)區(qū)域的均值,得到網(wǎng)絡(luò)輸入圖②,兩個輸入圖均為 3 通道;
- G 網(wǎng)絡(luò)有兩個分支,訓(xùn)練時,將圖①和圖②輸入 G 網(wǎng)絡(luò)的第一個分支,再從數(shù)據(jù)集中隨機挑選一張參考圖(網(wǎng)絡(luò)輸入圖③)輸入 G 網(wǎng)絡(luò)的第二個分支,得到網(wǎng)絡(luò)輸出的結(jié)果圖,根據(jù)結(jié)果圖和目標(biāo)圖計算 Perceptual loss、Gan loss、 L1 loss 以及 L2 loss,上述幾個 loss 控制整個網(wǎng)絡(luò)的學(xué)習(xí)和優(yōu)化;
- 實際使用時,將裁剪好的嘴巴區(qū)域的圖進(jìn)行步驟 3 中的預(yù)處理,并輸入訓(xùn)練好的 G 網(wǎng)絡(luò),就可以得到網(wǎng)絡(luò)輸出的結(jié)果圖,結(jié)合圖像融合算法將原圖和結(jié)果圖進(jìn)行融合,確保結(jié)果更加真實自然,并逆回到原始尺寸的原圖中,即完成全部算法過程。
GAN 網(wǎng)絡(luò)的構(gòu)建:
對于方案中的整個網(wǎng)絡(luò)結(jié)構(gòu),以及 perceptual loss、L1 loss、L2 loss 和 Gan loss,方案參考了論文 EdgeConnect[16]中的網(wǎng)絡(luò)結(jié)構(gòu)并結(jié)合自有方案進(jìn)行了調(diào)整。僅用網(wǎng)絡(luò)輸入圖①和網(wǎng)絡(luò)輸入圖②訓(xùn)練網(wǎng)絡(luò)模型,會造成生成的牙齒并不美觀甚至不符合常規(guī),為了使網(wǎng)絡(luò)模型可以生成既美觀又符合常規(guī)邏輯的牙齒,本方案構(gòu)建了一個雙分支輸入的全卷積網(wǎng)絡(luò),第二個分支輸入的是一張牙齒的「參考圖」,訓(xùn)練時,該參考圖是從訓(xùn)練數(shù)據(jù)集中隨機選擇的,參考圖可以對網(wǎng)絡(luò)生成符合標(biāo)準(zhǔn)的牙齒起到正向引導(dǎo)的作用:
- 第一個分支為 6 通道輸入,輸入為圖①和圖②的 concat,并歸一化到(-1,1)區(qū)間;
- 第二個分支為 3 通道輸入,輸入圖像是在構(gòu)建的訓(xùn)練數(shù)據(jù)集中隨機挑選的“參考圖”,同樣歸一化到(-1,1)區(qū)間;
G 網(wǎng)絡(luò)是本質(zhì)上是一個 AutoEncoder 的結(jié)構(gòu),解碼部分的上采樣采用的是雙線性上采樣 + 卷積層的結(jié)合,與論文中 [16] 有所不同,為了減輕生成圖像的 artifacts 和穩(wěn)定訓(xùn)練過程,本方案中的歸一化層統(tǒng)一都采用 GroupNorm,而網(wǎng)絡(luò)最后一層的輸出層激活函數(shù)為 Tanh。
判別網(wǎng)絡(luò)部分:判別網(wǎng)絡(luò)采用的是 multi_scale 的 Discriminator,分別判別不同分辨率下的真假圖像。本方案采用 3 個尺度的判別器,判別的是 256x256,128x128,64x64 三個尺度下的圖像。獲得不同分辨率的圖像,直接通過 Pooling 下采樣即可。
Loss 函數(shù)的設(shè)計包括 L1 loss, L2 loss, Perceptual loss 和 GAN loss。其中 L1 loss 和 L2 loss 可以保證圖像色彩的一致性;GAN loss 使得生成圖像的細(xì)節(jié)更加真實,也使得生成的牙齒更加清晰、自然、更加具有立體度和光影信息;Perceptual loss 限制圖像感知的相似性,以往的 VGG loss 往往會造成顏色失真與假性噪聲的問題,本方案采用的是更加符合人類視覺感知系統(tǒng)的 lpips(Learned Perceptual Image Patch Similarity) loss[17],很大程度上緩解了上述問題,使生成圖像具有更加自然的視覺效果;上述這幾個 loss 相加就構(gòu)成了 MTAITeeth 方案的損失函數(shù)。
結(jié)語
影樓修圖涉及眾多技術(shù),除了上述提到的特色修圖功能外,還包括人臉檢測、年齡檢測、性別識別、五官分割、皮膚分割、人像分割、實例分割等相對成熟的技術(shù),可見成熟的 AI 技術(shù)能夠替代影樓修圖費時費力且重復(fù)度高的流程,大幅節(jié)省人工修圖時間,節(jié)省修圖成本。在智能調(diào)色、智能中性灰、智能祛除、智能修復(fù)等 AI 技術(shù)的加持下,提高修圖質(zhì)量,解決手工修圖存在的問題。AI 自動定位臉部瑕疵、暗沉、黑頭等,在不磨皮的情況下予以祛除,實現(xiàn)膚色均勻,增強細(xì)節(jié)清晰度;識別皺紋、黑眼圈、淚溝等皮膚固有的缺陷,在保持紋理細(xì)節(jié)和過渡自然的前提下予以祛除;針對用戶的牙齒、雙下巴等影響美觀的缺陷,采用 AI 技術(shù)進(jìn)行自然修復(fù),達(dá)到美觀和諧的效果。
憑借在計算機視覺、深度學(xué)習(xí)、增強現(xiàn)實、云計算等領(lǐng)域的算法研究、工程開發(fā)和產(chǎn)品化落地的多年技術(shù)積累,MTlab 推出的的美圖云修人工智能修圖解決方案能為影像行業(yè)注入更多的活力,為商業(yè)攝影提供低成本、高品質(zhì)、高效率的的后期修圖服務(wù)。