













物聯網安全:軌跡隱私保護
軌跡隱私是一種特殊的個人隱私,指用戶的運行軌跡本身含有的敏感信息(如用戶去過的一些敏感區域等),或者可以通過運行軌跡推導出其他的個人信息(如用戶的家庭住址、工作地點、健康狀況、生活習慣等)。因此,軌跡隱私保護既要保證軌跡本身的敏感信息不泄露,又要防止攻擊者通過軌跡推導出其他的個人信息。
01 軌跡隱私的度量
在軌跡數據的發布過程中,發布的數據為了方便研究者研究利用,在進行隱私保護時需要具有較高的數據可用性。針對位置隱私保護,保護技術既要保護用戶的隱私安全,又要保證用戶能夠享受到較高的服務質量。
針對軌跡隱私的保護程度,一般可用3個指標來對其進行度量:軌跡上點與點之間的關聯性、軌跡中數據點的精確性、軌跡的隱私泄露概率。
軌跡是指某個用戶在一天內的位置和時間關聯排序的一組序列。一條軌跡可以表示為Ti={(xi1,yi1,ti1),(xi2,yi2,t2i),…,(xji,yji,tji),…,(xni,yni,tni)}。其中,Ti表示第i個用戶的軌跡,(xji,yji,tji)(1≤j≤n)表示此移動的用戶在tj時刻所在的位置為(xji,yji),tj為采樣時刻。基站或服務器將用戶在一天內所有的數據收集起來,然后將位置數據根據時間串聯起來就是此用戶的軌跡。軌跡數據蘊含了豐富的時空信息,對軌跡的分析和挖掘可以支持許多移動應用。例如:研究者通過分析人們的日常軌跡可以研究人類的行為模式;政府機構可以利用用戶的移動GPS軌跡數據可以分析基礎交通設施的建設情況。由此可知,用戶的軌跡數據對社會的發展提供了許多信息,同樣也會帶來隱私安全問題。
軌跡隱私與位置隱私最大的不同是軌跡包含時間和位置的關聯信息,很容易通過一個信息來推測出其他的信息。在傳統的軌跡隱私度量方法中,大都用時間和空間兩者進行分析度量,之后加入了軌跡形狀來對軌跡進行度量,其更能準確地衡量出兩條軌跡之間的相似性。
在定義軌跡相似性的度量標準時,需要從兩方面進行考慮。如圖1所示,有3條軌跡,每條軌跡都具有5個數據點,每個數據點都是在同一采樣時間上通過采樣得到的,假設每個采樣時刻的3個數據點的x軸坐標相同,只有y軸坐標不同。通過計算對應的5個數據點之間的歐氏距離,最后得出軌跡2和軌跡3到軌跡1的距離相等,但是從圖中可以觀察看出,軌跡2與軌跡1的形狀完全相同,而軌跡3與軌跡1不同,所以軌跡2與軌跡1的相似性明顯強于軌跡3與軌跡1的相似性。所以,在進行軌跡相似性度量時,要從兩個方面著手。
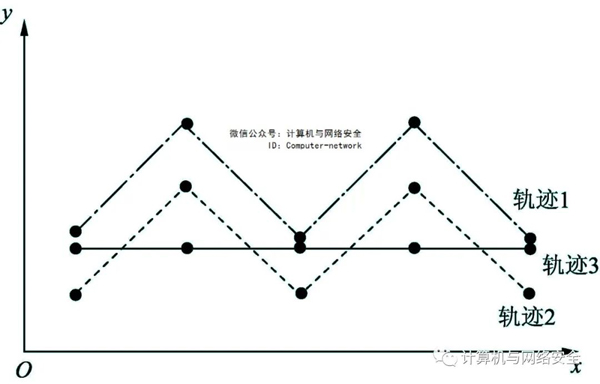
圖1 軌跡相似性對比
軌跡形狀距離:給定兩條軌跡Ti={(x1i,y1i,t1i),(xi2,y2i,t2i),…,(xni,yni,tni)}和Tj={(x1j,y1j,t1j),(x2j,y2j,t2j),…,(xnj,ynj,tnj)},則兩條軌跡之間的形狀距離如下所示:
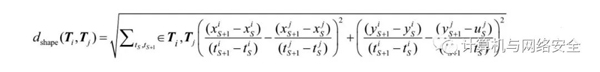
軌跡位置距離:針對定義6.1中給定的兩條軌跡,它們之間的位置距離如下所示:
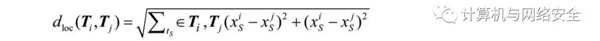
基于上述兩種距離形式的定義,將它們進行加權合并,即可得到兩條軌跡的軌跡距離。
軌跡距離:軌跡距離的定義如下所示:
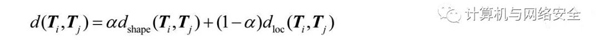
這里,α∈[0,1]為軌跡形狀距離和軌跡位置距離兩者的一個權重,一般取值為α=0.5。
02 軌跡隱私保護場景
目前,關于軌跡隱私保護的研究工作主要解決下述兩種應用場景中的隱私問題。
1. 數據發布中的軌跡隱私保護
軌跡數據本身蘊含了豐富的時空信息,對軌跡數據的分析和挖掘結果可以支持多種移動應用,因此,許多政府及科研機構都加大了對軌跡數據的研究力度。例如:美國政府利用移動用戶的GPS軌跡數據分析基礎交通設施的建設情況,進而為是否更新和優化交通設施提供依據;社會學的研究者們通過分析人們的日常軌跡來研究人類的行為模式;某些公司通過分析雇員的上下班軌跡來提高雇員的工作效率等。然而,假如惡意攻擊者在未經授權的情況下,計算推理獲取與軌跡相關的其他個人信息,則用戶的個人隱私會通過其軌跡完全暴露。數據發布中的軌跡隱私泄露情況大致可分為以下兩類。
① 軌跡上敏感或頻繁訪問位置的泄露導致移動對象的隱私泄露。軌跡上的敏感或頻繁訪問的位置很可能暴露其個人興趣愛好、健康狀況、政治傾向等個人隱私,如某人在某個時間段內頻繁訪問醫院或診所,攻擊者可以由此推斷出這個人近期患上了某種疾病。
② 移動對象的軌跡與外部知識的關聯導致隱私泄露。例如,某人每天早上在固定的時間段從地點A出發到地點B,每天下午在固定的時間段從地點B出發到地點A,通過挖掘分析,攻擊者很容易做出判斷:A是某人的家庭住址,B是其工作單位。通過查找A所在區域和B所在區域的郵編、電話簿等公開內容,很容易確定某人的身份、姓名、工作地點、家庭住址等信息。因此,某人的個人隱私通過其運行軌跡被完全泄露。
在軌跡數據發布中,最簡單的隱私保護方法是刪除每條軌跡的準標志屬性,即QI屬性。然而,單純地將QI屬性移除并不能保護移動對象的軌跡隱私,攻擊者通過將背景知識(如受攻擊者的博客、談話記錄或其他外部信息等)與特定用戶相匹配,亦可推導出個體的隱私信息。
例如,在刪除了QI屬性的數據中,攻擊者發現某個移動對象在某個時刻ti訪問了地點L1和L2,在攻擊者已知的背景知識中,小王曾在時刻ti左右分別訪問過這兩個位置,如果小王是在ti時刻唯一分別訪問過L1和L2的移動對象,那么攻擊者就可以斷定該軌跡屬于小王,繼而可從軌跡中發現小王訪問過的其他位置。可見,簡單地刪除移動對象的QI屬性并不能起到隱私保護的目的。
2. 位置服務中的軌跡隱私保護
用戶在獲取LBS服務時,需要提供自己的位置信息,為了保護移動對象的位置隱私,出現了位置隱私保護技術。然而,保護了移動對象的位置隱私并不代表能保護移動對象的實時運行軌跡隱私,攻擊者極有可能通過其他手段獲得移動對象的實時運行軌跡。例如,利用位置k-匿名模型對發出連續查詢的用戶進行位置隱私保護時,移動對象的匿名框的位置和大小會產生連續更新。如果將移動對象發出LBS請求時各個時刻的匿名框連接起來,就可以得到移動對象大致的運行路線。這是由于移動對象在查詢過程中生成的匿名框包含了不同移動對象的信息,單純地延長匿名框的有效時間會導致服務質量下降。雖然,目前已有針對連續查詢的位置隱私保護技術,但是,其查詢有效期處于秒級,無法滿足軌跡隱私保護的需求。因此,在LBS中也需要軌跡隱私保護技術。
在上述兩種場景中,軌跡隱私保護需要解決以下幾個關鍵問題:
① 保護軌跡上的敏感/頻繁訪問位置信息不泄露;
② 保護個體和軌跡之間的關聯關系不泄露,即保證個體無法與某條軌跡相匹配;
③ 防止由移動對象的相關參數限制(如最大速度、路網等)而泄露移動對象軌跡隱私的問題發生。
03 軌跡隱私保護技術分類
軌跡隱私保護技術大致可以分為3類。
(1)基于假數據的軌跡隱私保護技術
該技術通過添加假軌跡對原始數據進行干擾,同時又要保證被干擾的軌跡數據的某些統計屬性不發生嚴重失真。基于假數據的軌跡隱私保護技術主要是在原始數據的基礎上添加假數據,進而對原始軌跡數據進行干擾,同時又不會使原始軌跡數據失真。例如,在表1中有3個移動對象O1、O2、O3,表中數據分別對應它們在時刻t1、t2、t3中的數據點,每個對象可根據時間關聯形成一條軌跡。

表1 原始數據
利用假數據法對表1中的數據進行干擾之后,形成了6條軌跡,如表2所示,在此6條軌跡中,I1、I2、I3是O1、O2、O3的假名。由此可將每條真實軌跡被泄露的風險降至0.5。
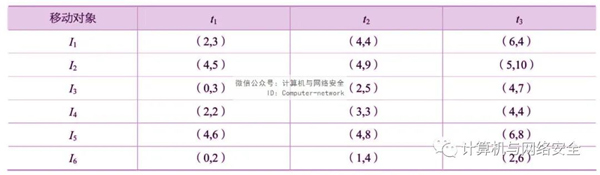
表2 用假數據法干擾后的數據
針對假數據方法,假軌跡的數量越多,被泄露的風險就越低,但是這會對原始數據產生較大的影響。假軌跡的產生在空間關系中增加了復雜性,會產生許多交叉點,因易于混淆而可降低風險。在運行模式中,假軌跡的運行模式與原始軌跡相似,也會對攻擊者的攻擊造成一定的影響。此類方法較簡單且計算量小,但易造成存儲量的擴大,使數據可用性降低。
(2)基于泛化法的軌跡隱私保護技術
該技術是指將軌跡上所有的采樣點都泛化為對應的匿名區域,以達到隱私保護的目的。基于泛化法的軌跡隱私保護技術針對所有軌跡中的每一個點進行泛化,并將它們泛化成數據點對應的匿名區,從而達到隱私保護的目的。在泛化的保護技術中,最常用的是軌跡k-匿名保護技術,其主要的保護技術是將其需要保護的核心屬性進行泛化,使其無法與其他k-1條記錄區分開。針對表1中的軌跡數據,將其中的3條軌跡進行軌跡泛化匿名,即針對每個采樣時刻的點,將數據點泛化為匿名區,如表3所示。

表3 軌跡6-匿名
在進行匿名時依然通過假名進行發布,同時也須對3個匿名時刻中的數據點進行匿名泛化。此方法可以保證數據均為真實數據,但是由于計算開銷比較大,因此需要考慮性能的問題。
(3)基于抑制法的軌跡隱私保護技術
該技術根據具體情況有條件地發布軌跡數據,不發布軌跡上的某些敏感位置或頻繁訪問的位置以實現隱私保護。表4所示為表2進行抑制發布后的數據。

表4 抑制法進行軌跡匿名
抑制法較其他方法來說簡單有效,在攻擊者具有一定背景知識的前提下亦可進行軌跡保護,效率也比較高。但在不能確切地了解攻擊者具有的背景知識時,這種方法就不再適用了。另一方面,此方法雖然限制了敏感數據的發布且實現過程簡單,但是信息丟失量過大。
總之,基于假數據的軌跡隱私保護技術簡單、計算量小,但易造成假數據的存儲量大及數據可用性降低等問題;基于泛化法的軌跡隱私保護技術可以保證數據的真實性,但計算開銷較大;基于抑制法的軌跡隱私保護技術可限制發布某些敏感數據,實現也簡單,但信息丟失量較大。目前,基于泛化法的軌跡k-匿名技術在隱私保護度和數據可用性上取得了較好的平衡,是目前軌跡隱私保護使用的主流方法。
04 基于語義的軌跡隱私保護方法
原始的軌跡數據與用戶的各類隱私信息緊密相關,如果不對收集到的軌跡數據做任何處理就發布,惡意攻擊者就可以通過對軌跡數據進行挖掘分析,獲得用戶的家庭住址、興趣愛好、行為模式等敏感信息。因此,離線軌跡數據發布必須遵循“數據采集、隱私保護處理、軌跡發布”的原則。
軌跡發布后,不論是商業機構還是科研單位,都希望能夠從保護后的軌跡中分析出可用的信息。因此,軌跡隱私保護處理的目標是:既要能防止惡意攻擊者從處理后的軌跡中推測出用戶的敏感信息,也要確保處理后的軌跡仍然具有較高的完整性和數據可用性。
目前,離線軌跡發布中的隱私保護方法,如軌跡聚類、假軌跡等,都僅把軌跡數據看作歐式空間中具有時間屬性的位置點序列,只考慮到了軌跡的時間和空間屬性,卻忽視了軌跡上各個采樣點在實際環境中對應的位置信息,即軌跡的語義屬性。
通常,用戶軌跡上的位置點可以分為移動點和停留點。移動點只能分析出用戶途經了哪些道路,而停留點卻能反映出用戶某個時間段的重要位置特征。通過對停留點進行分析可以知道用戶頻繁訪問的地點,進而推測出用戶的工作地址、興趣愛好甚至是宗教信仰、身體狀況等私密信息。因此相比移動點,停留點會暴露用戶更多的敏感信息。保護停留點不僅能夠確保用戶的隱私,還能減少對原始軌跡的破壞,在隱私保護和數據可用性之間取得了較好的平衡。
實際生活中,不同用戶對相同語義位置的敏感程度可能并不相同,如患者和醫生對醫院的敏感性就不一樣,患者可能并不想暴露自己的身體健康狀況,但醫生一般不介意自己的工作地點被泄露,因此,對軌跡進行保護時不能忽略用戶的個性化隱私需求。假如對所有用戶采用相同的處理標準,就可能會導致部分用戶的軌跡保護程度不夠而造成隱私泄露,部分用戶的軌跡保護過度而造成數據損失。
忽略軌跡的語義屬性會導致部分現有方案容易遭受語義攻擊。相比自己路過的位置,用戶更關心自己曾經頻繁訪問、長時間逗留的地點是否會泄露隱私。因此,為了維持軌跡的最大完整性,無須對軌跡上的所有采樣點進行保護處理。
圖2提出的方案旨在維持軌跡安全性與數據可用性之間良好的平衡,用停留點周圍不同語義的興趣點取代用戶敏感的停留點,同時重置少量采樣點以隱藏用戶的敏感信息。該方案采取了個性化隱私保護,用戶可以自定義自身的敏感語義位置集和隱私保護程度,以在保證軌跡隱私安全的同時確保軌跡不被過度處理。
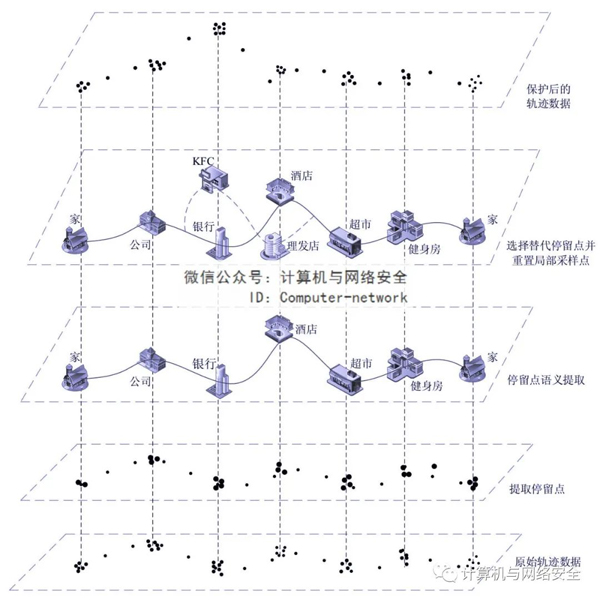
圖2 基于語義的軌跡隱私保護方案示意
1. 基于語義的軌跡隱私保護方案
該方案首先根據原始軌跡數據,分析用戶的移動特征,針對時間、經度和緯度3個屬性進行多維聚類,提取出用戶一天內的停留點集合,利用地圖反解析獲取停留點對應的實際位置并標記其語義;其次,根據用戶自定義的敏感語義位置集,獲取用戶的敏感停留點集合(即圖2中的銀行和酒店);然后,結合用戶的移動方向,為每個敏感停留點合理地規劃一個候選區,分析候選區內興趣點的語義和距離特性,查找到滿足用戶隱私需求的不同語義的興趣點,將包含這些興趣點的最小矩形作為敏感區,并在敏感區內隨機選取一個替代停留點(即圖2中的KFC和理發店);最后,為了防止替換停留點導致軌跡上位置點發生突變,以減少軌跡變動,僅對敏感區內的局部采樣位置點進行重新選擇,并確保敏感區內的采樣位置點數量與原始軌跡的一致,進而形成最終可發布的軌跡數據。
2. 語義停留點的提取
根據用戶軌跡進行語義停留點提取是本方案的首要工作。
一個用戶在日常生活中會產生大量的停留點:對于大部分用戶來說,在夜間12點到早晨6點都在自己家中,此時用戶的家庭位置就成為了他的一個停留點;用戶的日常工作地點也會成為他的一個停留點;在銀行辦理業務的用戶,銀行也會成為他的一個停留點。
對于具有地圖背景知識的惡意攻擊者,通過提取用戶軌跡中的停留點并將其映射到語義地圖上,可以獲取用戶大量的個人隱私。
用戶軌跡上的所有采樣位置點都具有相對應的語義屬性。相比移動中的位置點,惡意攻擊者對用戶頻繁訪問和長時間停留的位置點更感興趣,這是因為他們能從中挖掘分析出更多的用戶隱私信息。因此,對停留點進行隱私保護至關重要。
圖3所示為某個用戶在一段時間內的軌跡數據Traj={P1,P2,…,P9}。通過分析可知,軌跡中的5個連續采樣位置點{P3,P4,P5,P6,P7}均處于一定的范圍內,由此推斷該用戶曾經在這個地點(圖中虛線圈)停留過。具有地圖背景知識的惡意攻擊者此時就可以通過將停留點映射到真實地圖中,得到該用戶停留的地點,并由此獲得用戶的某些隱私信息。
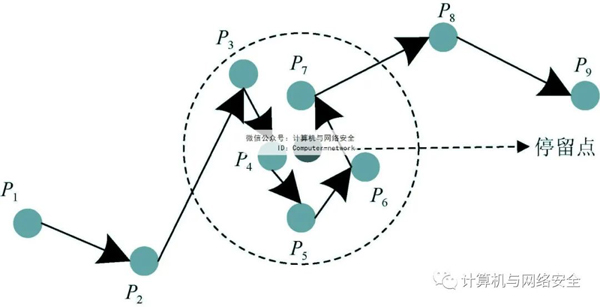
圖3 個人停留點示意圖
從上面的例子不難看出,通過挖掘分析用戶停留點,具有背景知識的攻擊者就可以輕易獲得用戶大量隱私信息。而對敏感停留點進行保護,無須處理軌跡上所有的采樣位置點,這不僅能隱藏軌跡上用戶的敏感信息,還能減少對原始軌跡的破壞。
該方法首先讀取某個區域在一段時間內全體用戶的原始軌跡數據,如圖4所示,Lij表示用戶Mi(1≤i≤m)在tj(1≤j≤n)時刻的位置,依次對每個用戶的軌跡進行多維聚類,包括時間、經度和緯度聚類,以提取用戶個人停留點集合。聚類時需要3個閾值:時間閾值σt、距離閾值σd和位置點數閾值σn。

圖4 用戶原始軌跡數據
然后,通過遍歷一個用戶軌跡上的采樣位置點,可以找到所有停留核心點。停留核心點是用戶Mi在tj時刻的位置點Lij,遍歷該用戶軌跡上的所有位置點Lik(1≤k≤n)并使它們與其進行比較,找到所有滿足|Lij-Lik|≤σd且|tj-tk|≤σt的點。如果Lij處滿足以上條件的點的數量不少于σn,則Lij為停留核心點。
最后,將時空上鄰近的停留核心點劃分到一個集合,最終得到多個停留核心點的集合,這個集合稱為語義停留點。
由此可見,通過多維聚類的方法對個體用戶的多維空間數據進行分析,可以得到用戶的移動特征;根據用戶的移動特征,可以提取個人停留點集合;將停留點一一映射到地圖上,通過標記其語義,并根據用戶自定義的敏感語義位置集,即可獲得個人敏感停留點集合(即語義停留點集合)。
3. 語義停留點的合并
采樣的用戶軌跡上可能由于某種原因存在采樣異常點,如一個采樣位置點與其前后相鄰時刻的采樣位置點之間的距離過大,如圖5所示。P5與P4和P6之間的距離差過大,不符合實際,即該采樣位置點和它相鄰的位置點在采樣時間內是不可到達的。異常點的存在會影響個人停留點的提取及其語義標記的精度,因此,在將相鄰的停留核心點聚集成停留點之前需要對軌跡數據進行掃描以檢測異常點。正常用戶行走的速度大致為3 km/h,用戶在某個地方停留時一般會處于靜止或者慢速移動的狀態,速度不應該大于正常移動速度,結合采樣時間可以計算出一個距離δ,如果tj時刻的采樣位置Lij與其前后相鄰時刻采樣位置點之間的距離差|Lij-Li(j-1)|和|Lij-Li(j+1)|均大于δ,則認為Lij是采樣異常點,在合并相鄰停留核心點時應舍棄該異常點。完成軌跡數據檢測和異常點舍棄之后,便可以進行停留核心點的合并。
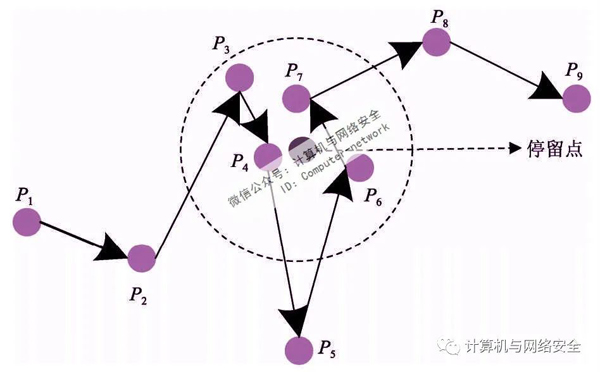
圖5 采樣異常點
通過上述方法,可以提取到每個用戶在一段時間內的停留點集合SP={SP1,SP2,…,SPn},其中SPi(1≤i≤n)是包含多個停留核心點的停留點,每個停留點內包含的停留核心點可以表示為SPi={P1,P2,…,Pm}。后續需要對停留點進行替換和采樣點的重置,這里將能夠覆蓋SPi內所有停留核心點的最小覆蓋圓的圓心作為停留點的代表坐標,如圖5中的停留點,同時須求出最小覆蓋圓半徑以備后續重置采樣點。
針對每個停留點SPi={P1,P2,…,Pm},求其最小覆蓋圓,基本思想為:首先在SPi內任選3個停留核心點組成三角形,求出該三角形的最小覆蓋圓圓心與半徑;然后依次遍歷剩余的停留核心點,判斷該點是否在已得到的圓內,如果在圓內,則說明該圓依舊是最小覆蓋圓,如果不在圓內,則隨機在上述3個點中選擇兩個點與該點形成新的三角形,并重新計算新的最小覆蓋圓的圓心與半徑。重復以上過程,直到求出能覆蓋所有停留核心點的最小覆蓋圓的圓心與半徑。
通過上述方法可以獲得每個停留點的坐標信息及覆蓋范圍。接著調用百度地圖Web服務API,利用逆地址編碼服務,獲取停留點坐標所在的位置并標記其語義屬性。
4. 敏感停留點的替換
在完成用戶原始軌跡上所有敏感停留點的提取后,接下來須根據用戶個性化的隱私保護程度要求,在合理的空間范圍內將敏感停留點替換成不同語義的興趣點。其中,選擇合適的替代停留點是關鍵,為了保證處理后的軌跡的安全性和完整性,替代停留點的選取不能完全隨機,需要充分考慮用戶的移動方向,興趣點的語義、距離等特性。替代停留點的選擇過程分為兩部分:首先為每個敏感停留點構建一個合適的候選區,然后在候選區內選擇一個合適的興趣點并將其作為替代停留點。
(1)候選區的構建
為了防止替代停留點偏離相應的敏感停留點太遠,影響受保護后軌跡數據的可用性,須根據敏感停留點自身構建候選區,候選區的范圍由該敏感停留點以及在軌跡上與其時空相鄰的前后兩個停留點之間的距離共同決定。
如圖6所示,用戶軌跡上分別有敏感停留點SP2和SP3。若在候選區的重疊區域內選擇了各自的替代停留點SP′2和SP′3,則通過比較發現保護后的軌跡與原始軌跡在形狀、方向上都出現了較大的偏差,嚴重降低了兩條軌跡之間的相似性。由于保護后的軌跡與原始軌跡之間的相似性是衡量軌跡數據可用性的重要指標,因此,為了防止敏感停留點替換后會破壞軌跡的可用性,需要確保相鄰敏感停留點的候選區不能存在重疊區域。若現有候選區范圍內的興趣點無法滿足用戶隱私需求,則為了搜索更多的興趣點,應擴大候選區。如果候選區的擴張導致部分候選區出現重疊,則應避免在候選區的重疊區域選擇替代停留點。
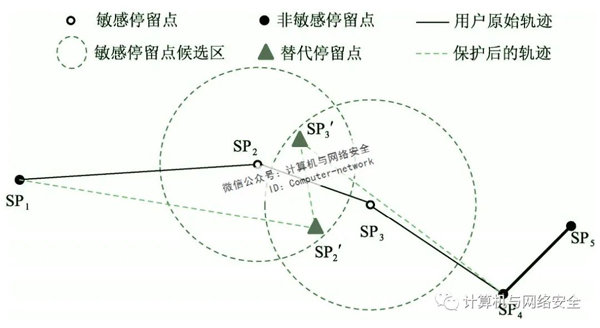
圖6 候選區重疊導致軌跡相似度降低
方案中每個敏感停留點的候選區均是以其自身為圓心、其到相鄰停留點的距離中的較小值為直徑的圓域。對于軌跡上的第一個停留點,若它為敏感停留點,則由于它沒有上一個相鄰停留點,因此,它的候選區直徑為它與下一個停留點間的距離;同樣,若軌跡上的最后一個停留點為敏感停留點,則由于它不存在下一個相鄰停留點,因此,它的候選區直徑為它與上一個停留點間的距離。
如圖7所示,對某用戶進行移動特征分析,從其軌跡上提取出了5個停留點{SP1,SP2,SP3,SP4,SP5}。若其中{SP1,SP2,SP3}為敏感停留點集合,則虛線圓域分別為它們的候選區。其中SP1和SP5由于是邊界點,僅有一個相鄰停留點,因此,它們的候選區半徑分別為SP1到SP2、SP4到SP5距離的一半;而SP3存在前后相鄰停留點SP2和SP4,因此它的候選區半徑為SP3到SP4距離的一半(因為SP3到SP4的距離小于SP2到SP3的距離)。如此構建的候選區不會導致替代位置點太偏離停留點本身,同時也能避免出現候選區重疊導致軌跡相似度降低的情況。
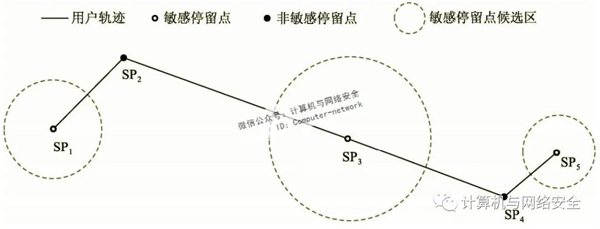
圖7 敏感停留點候選區
(2)替代停留點的選擇
隱私保護程度l表示敏感區中與敏感停留點距離最近但語義不同的其他興趣點的個數至少為l個。隱私保護程度體現了敏感區內興趣點的多樣性。l值越大表示用戶隱私需求越高。
為每個敏感停留點構造好合理的候選區之后,下一項工作是結合用戶自定義的隱私需求,在候選區內為每個敏感停留點選取合適的興趣點并將它們作為替代停留點。如果選取與敏感停留點語義相同或者相似的興趣點并將它們作為替代停留點,則惡意攻擊者還是能夠從替換后的停留點的語義中推測出用戶的敏感信息;而且在實際環境中,某些具有相同語義的興趣點一般距離較遠,這可能會導致選擇的替代停留點偏離敏感停留點較遠,要重置的采樣位置點數量較多,軌跡的完整性較低。
在本方案中,敏感停留點會被替換成語義不同的興趣點。首先,以敏感停留點自身為中心,搜索替代停留點,并逐漸擴大搜索半徑,直至找到不少于l個且語義與敏感停留點不同的興趣點;然后,將搜索到的興趣點按照離敏感停留點的距離由近至遠排序,取前l個作為替代停留點的候選集,并把包含敏感停留點和這l個興趣點的最小矩形作為敏感區SA;最后,在敏感區內隨機選擇一個興趣點并將其作為替代停留點。
在查找替代停留點集時,遍歷每一個新搜索到的興趣點,如果其語義與敏感停留點不同,則將其加入候選集,反之,則忽略它,最終在形成的敏感區內隨機選擇一個興趣點并將其作為替代停留點。敏感區內包含了位置和語義多樣性的興趣點,這加大了攻擊者推測出真實敏感停留點的難度,同時興趣點選擇的隨機性也提高了真實敏感停留點的安全性。將最小包圍矩形作為敏感區,可減少之后須重置的采樣點數量,為提高軌跡的完整性奠定基礎。
(3)局部采樣點的重置
為敏感停留點SPi選取合適的替代位置后,需要為替代停留點SPif選擇其包含的停留核心點。同時停留點替換后可能會造成部分移動采樣點在采樣間隔內不可到達替代停留點,從而導致位置突變,使攻擊者易推斷出該軌跡段被替換過,因此,為了提高發布后軌跡的安全性,還需要重新選擇軌跡上的部分移動點。為了最大程度保持軌跡形狀的一致性,盡量少修改原始軌跡,局部采樣點重置僅在敏感區內進行,且重置時要充分考慮原始軌跡上移動點的速度。同時敏感區內包含的采樣點數量應該與原來的相同,以提高重置后軌跡段的真實性。
局部采樣點重置分為3部分:敏感區入口到替代停留點之間的移動采樣點重置、替代停留點包含的停留核心點重置,以及替代停留點到敏感區出口之間的移動采樣點重置。首先進行局部采樣點的重置,如圖8所示,敏感區內的第一個采樣點為A,最后一個采樣點為B;在A到SPi的原始軌跡段上尋找點C,使C到SPi與C到SPif的距離差最小,同理在B到SPi的原始軌跡段上找到點D,使D到SPi與D到SPif的距離差最小;同時將敏感停留點SPi的覆蓋范圍作為替代停留點SPif的覆蓋范圍;然后獲取敏感區內移動點的速度取值范圍{Vmin,Vmax},分別在C到SPif和D到SPif段根據速度值和采樣時間確定合適的新采樣位置,并保證兩條軌跡段上重置的采樣點數與對應原始軌跡段上的采樣點數相等。最后進行停留核心點的重置,在SPif覆蓋范圍內隨機選取采樣點,同樣須保證采樣位置點數不變。同時,為了提高軌跡抵抗攻擊的能力,在選取任何新的采樣點時需要檢測其位置是否合理,采樣點一般不應該位于湖泊中央等小概率的位置處。

圖8 局部采樣點重置示意圖
查找到C、D兩個采樣點使得在局部采樣點重置的過程中,不需要重新選擇整個敏感區的采樣位置點了。這不僅減少了需要處理的采樣位置點的數量,同時也提高了軌跡的完整性。局部采樣點重置后,用戶軌跡的敏感隱私信息已不存在,可直接發布共享,用于數據分析與研究。
















