













一文搞懂Undo Log版本鏈與ReadView機制如何讓事務讀取到該讀的數據
本文轉載自微信公眾號「菜鳥飛呀飛」,作者劉進坤。轉載本文請聯系菜鳥飛呀飛公眾號。
undo log 版本鏈
在 MySQL 的數據表中,存儲著一行行的數據記錄,對每行數據而言,不僅僅記錄著我們定義的字段值,還會隱藏兩個字段:row_trx_id 和 roll_pointer,前者表示更新本行數據的事務 id,后者表示的是回滾指針,它指向的是該行數據上一個版本的 undo log(如果不明白這是什么,可以先繼續往后看)。
對于每行有兩個隱藏的字段,在《高性能 MySQL》第三版的第 13 頁中把它們叫做數據的更新時間和過期時間,這兩個字段存儲的不是真實的時間,而是事務的版本號。
這與本文 row_trx_id 和 roll_pointer 的叫法差異很大,實際上,不用在意這兩個字段具體叫什么,反正它們都是為了實現 MVCC 機制而設計的。
我個人覺得把它們分別叫做 row_trx_id 和 roll_pointer,會更容易理解一點。
我們知道,當我們進行數據的新增、刪除、修改操作時,會寫 redo log(解決數據庫宕機重啟丟失數據的問題)和 binlog(主要用來做復制、數據備份等操作),另外還會寫 undo log,它是為了實現事務的回滾操作。
每一條 undo log 的具體內容本文今天先不解釋,有興趣的同學可以自行網上查閱。我們只需要知道每行 undo log 日志會記錄對應的事務 id,還會記錄當前事務將數據修改后的最新值,以及指向當前行數據上一個版本的 undo log 的指針,也就是 roll_pointer。
為了方便理解,每一行 undo log 可以簡化為下圖所示的結構:
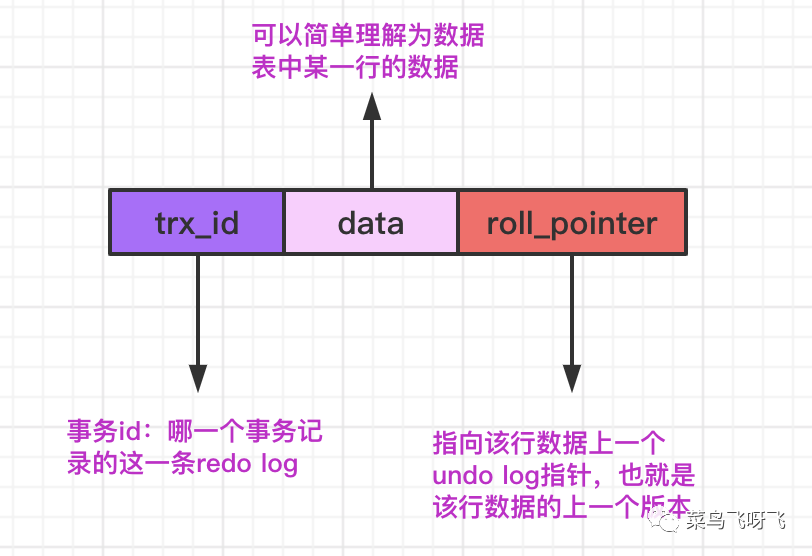
圖1
舉個例子,現在有一個事務 A,它的事務 id 為 10,向表中新插入了一條數據,數據記為 data_A,那么此時對應的 undo log 應該如下圖所示:
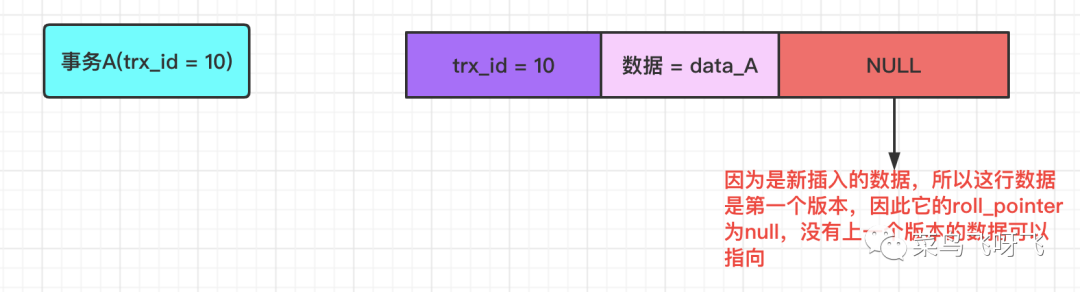
圖2
由于是新插入的一條數據,所以這行數據是第一個版本,也就是它沒有上一個數據版本,因此它的 roll_pointer 為 null。
接著事務 B(trx_id=20),將這行數據的值修改為 data_B,同樣也會記錄一條 undo log,如下圖所示,這條 undo log 的 roll_pointer 指針會指向上一個數據版本的 undo log,也就是指向事務 A 寫入的那一行 undo log。
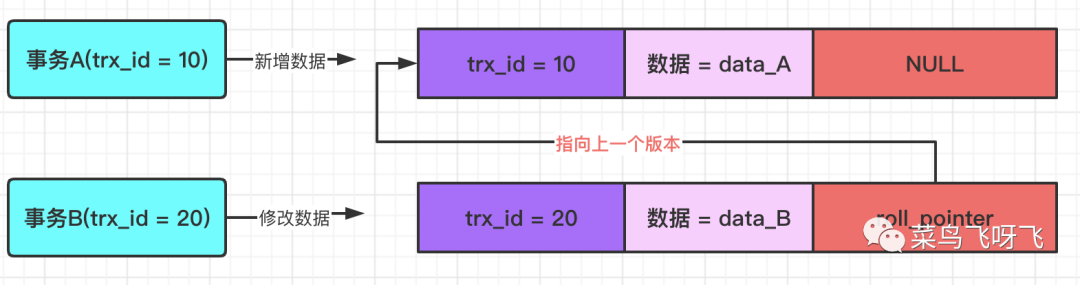
圖3
再接著,事務 C(trx_id=30),將這行數據的值修改為 data_C,對應的示意圖如下。
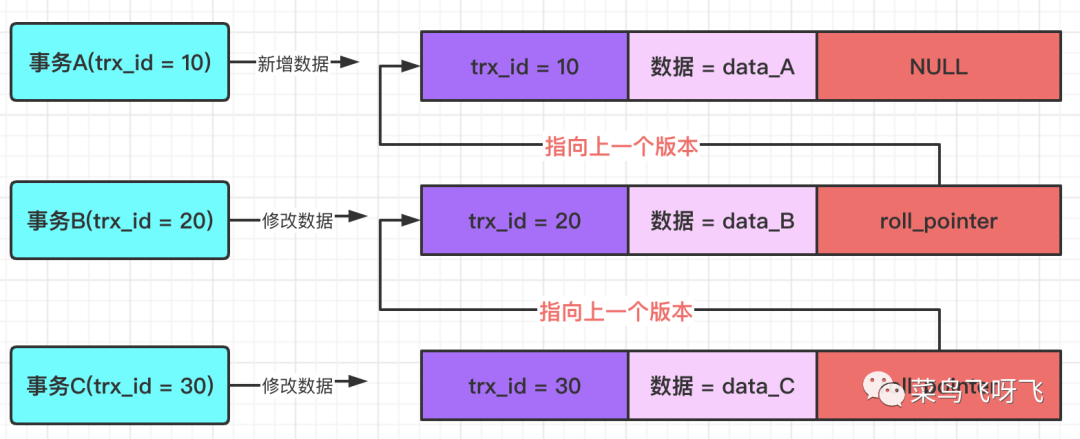
圖4
只要有事務修改了這一行的數據,那么就會記錄一條對應的 undo log,一條 undo log 對應這行數據的一個版本,當這行數據有多個版本時,就會有多條 undo log 日志,undo log 之間通過 roll_pointer 指針連接,這樣就形成了一個 undo log 版本鏈
ReadView 機制
當事務在開始執行的時候,會給每個事務生成一個 ReadView。這個 ReadView 會記錄 4 個非常重要的屬性:
- creator_trx_id: 當前事務的 id;
- m_ids: 當前系統中所有的活躍事務的 id,活躍事務指的是當前系統中開啟了事務,但是還沒有提交的事務;
- min_trx_id: 當前系統中,所有活躍事務中事務 id 最小的那個事務,也就是 m_id 數組中最小的事務 id;
- max_trx_id: 當前系統中事務的 id 值最大的那個事務 id 值再加 1,也就是系統中下一個要生成的事務 id。
ReadView 會根據這 4 個屬性,再結合 undo log 版本鏈,來實現 MVCC 機制,決定讓一個事務能讀取到哪些數據,不能讀取到哪些數據。
那么到底是如何來實現的呢?
如果用一個坐標軸來表示的話,min_trx_id 和 max_trx_id 會將這個坐標軸分成 3 個部分:

圖5
當一個事務讀取某條數據時,就會按照如下規則來決定當前事務能讀取到什么數據:
- 如果當前數據的 row_trx_id 小于 min_trx_id,那么表示這條數據是在當前事務開啟之前,其他的事務就已經將該條數據修改了并提交了事務(事務的 id 值是遞增的),所以當前事務能讀取到。
- 如果當前數據的 row_trx_id 大于等于 max_trx_id,那么表示在當前事務開啟以后,過了一段時間,系統中有新的事務開啟了,并且新的事務修改了這行數據的值并提交了事務,所以當前事務肯定是不能讀取到的,因此這是后面的事務修改提交的數據。
- 如果當前數據的 row_trx_id 處于 min_trx_id 和 max_trx_id 的范圍之間,又需要分兩種情況:
(a)row_trx_id 在 m_ids 數組中,那么當前事務不能讀取到。為什么呢?row_trx_id 在 m_ids 數組中表示的是和當前事務在同一時刻開啟的事務,修改了數據的值,并提交了事務,所以不能讓當前事務讀取到;
(b) row_trx_id 不在 m_ids 數組中,那么當前事務能讀取到。row_trx_id 不在 m_ids 數組中表示的是在當前事務開啟之前,其他事務將數據修改后就已經提交了事務,所以當前事務能讀取到。
注意:如果 row_trx_id 等于當前事務的 id,那表示這條數據就是當前事務修改的,那當前事務肯定能讀取到啊。
這里可能有人會有一個疑惑,事務的 id 值是遞增的,那么在什么場景下,row_trx_id 處于 min_trx_id 和 max_trx_id 之間,但是卻又不再 m_id 數組內呢?
這個問題也是困擾了我很長一段時間,最近終于想通了,答案就是在讀提交的事務隔離級別下,會出現這種現象。
至于為什么,需要看完這一篇文章以及下下一篇文章《在讀提交的事務隔離級別下,MVCC 機制是如何工作的?》,才能明白為什么。
下面舉幾個例子,來解釋一下 ReadView 機制下,數據的讀取規則。先假設表中有一條數據,它的 row_trx_id=10,roll_pointer 為 null,那么此時 undo log 版本鏈就是下圖這樣:

圖6
假設現在有事務 A 和事務 B 并發執行,事務 A 的事務 id 為 20,事務 B 的事務 id 為 30。
那么此時對于事務 A 而言,它的 ReadView 中,m_ids=[20,30],min_trx_id=20,max_trx_id=31,creator_trx_id=20。
對于事務 B 而言,它的 ReadView 中,m_ids=[20,30],min_trx_id=20,max_trx_id=31,creator_trx_id=30。
如果此時事務 A(trx_id=20)去讀取數據,那么在 undo log 版本鏈中,數據最新版本的事務 id 為 10,這個值小于事務 A 的 ReadView 里 min_trx_id 的值,這表示這個數據的版本是事務 A 開啟之前,其他事務提交的,因此事務 A 可以讀取到,所以讀取到的值是 data0。
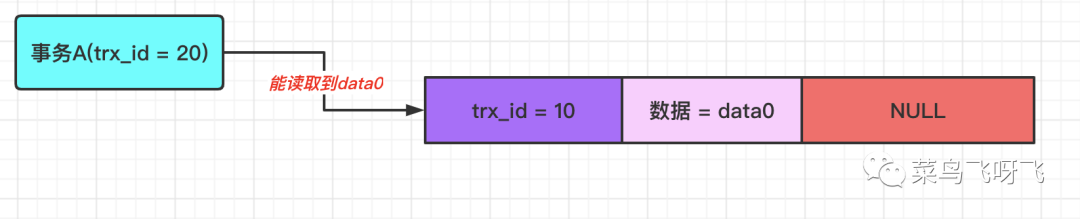
圖7
接著事務 B(trx_id=30)去修改數據,將數據修改為 data_B,先不提交事務。雖然不提交事務,但是仍然會記錄一條 undo log,因此這條數據的 undo log 的版本鏈就有兩條記錄了,新的這條 undo log 的 roll_pointer 指針會指向前一條 undo log,示意圖如下。
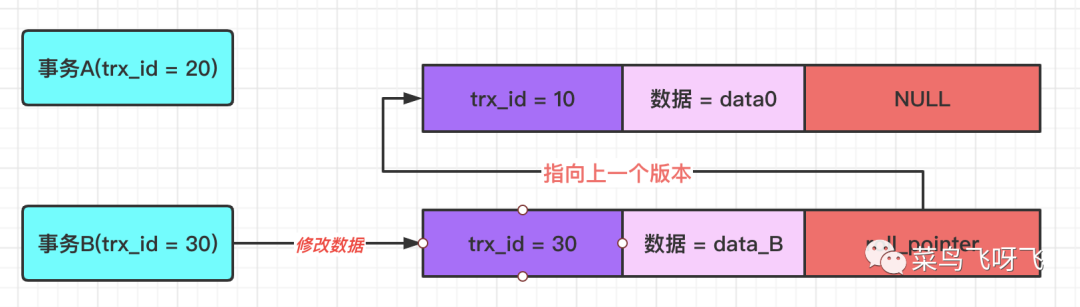
圖8
接著事務 A(trx_id=20)去讀取數據,那么在 undo log 版本鏈中,數據最新版本的事務 id 為 30,這個值處于事務 A 的 ReadView 里 min_trx_id 和 max_trx_id 之間,因此還需要判斷這個數據版本的值是否在 m_ids 數組中,結果發現,30 確實在 m_ids 數組中,這表示這個版本的數據是和自己同一時刻啟動的事務修改的,因此這個版本的數據,數據 A 讀取不到。所以需要沿著 undo log 的版本鏈向前找,接著會找到該行數據的上一個版本,也就是 trx_id=10 的版本,由于這個版本的數據的 trx_id=10,小于 min_trx_id 的值,因此事務 A 能讀取到該版本的值,即事務 A 讀取到的值是 data0。
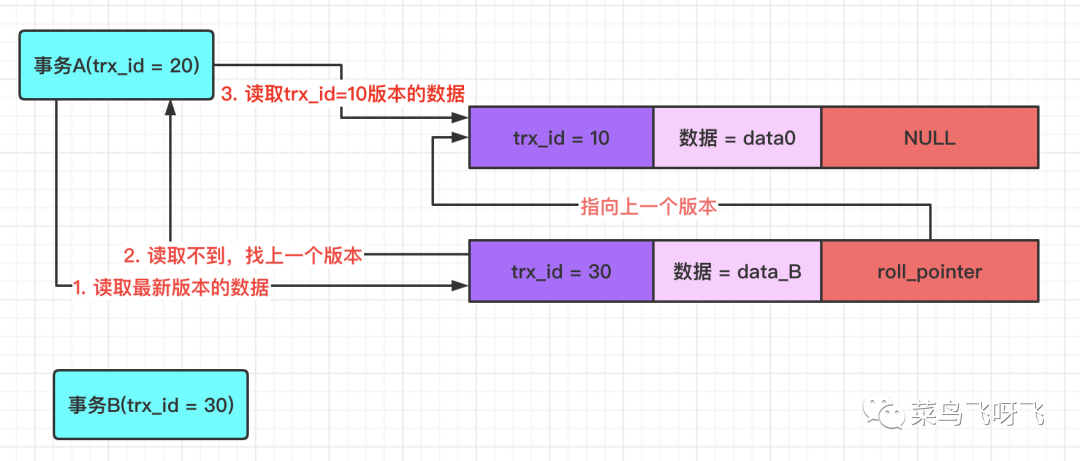
圖9
緊接著事務 B 提交事務,那么此時系統中活躍的事務就只有 id 為 20 的事務了,也就是事務 A。那么此時事務 A 再去讀取數據,它能讀取到什么值呢?還是 data0。為什么呢?
雖然系統中當前只剩下 id 為 20 的活躍事務了,但是事務 A 開啟的瞬間,它已經生成了 ReadView ,后面即使有其他事務提交了,但是事務 A 的 ReadView 不會修改,也就是 m_ids 不會變,還是 m_ids=[20,30],所以此時事務 A 去根據 undo log 版本鏈去讀取數據時,還是不能讀取最新版本的數據,只能往前找,最終還是只能讀取到 data0。
接著系統中,新開了一個事務 C,事務 id 為 40,它的 ReadView 中,m_ids=[20,40],min_trx_id=20,max_trx_id=41,creator_trx_id=40。
然后事務 C(trx_id=40)將數據修改為 data_C,并提交事務。此時 undo log 版本鏈就變成了如下圖所示。
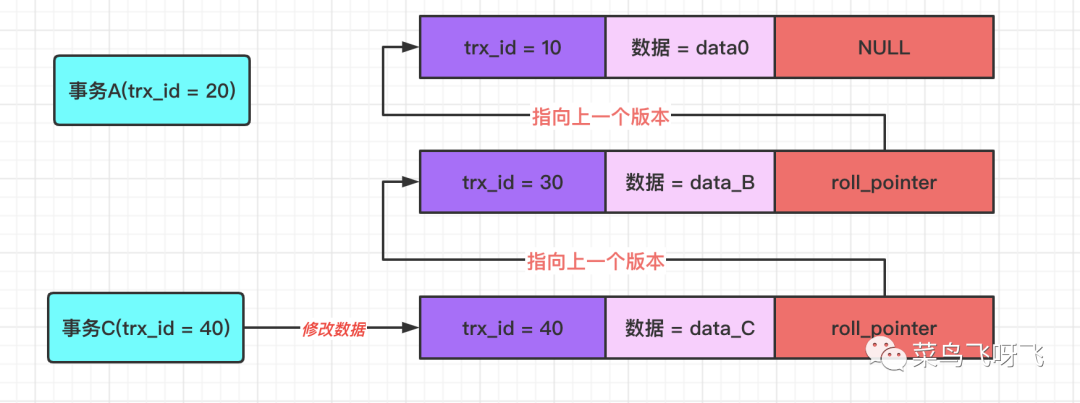
圖10
此時事務 A(trx_id=20)去讀取數據,那么在 undo log 版本鏈中,數據最新版本的事務 id 為 40,由于此時事務 A 的 ReadView 中的 max_trx_id=31,40 大于 31,這表示當前版本的數據時在事務 A 之后提交的,因此對于事務 A 肯定是不能讀取到的。所以此時事務 A 只能根據 roll_pointer 指針,沿著 undo log 版本向前找,結果發現上一個版本的 trx_id=30,自己還是不能讀取到,所以再繼續往前找,最終可以讀取到 trx_id=10 的版本數據,因此最終事務 A 只能讀取到 data0。
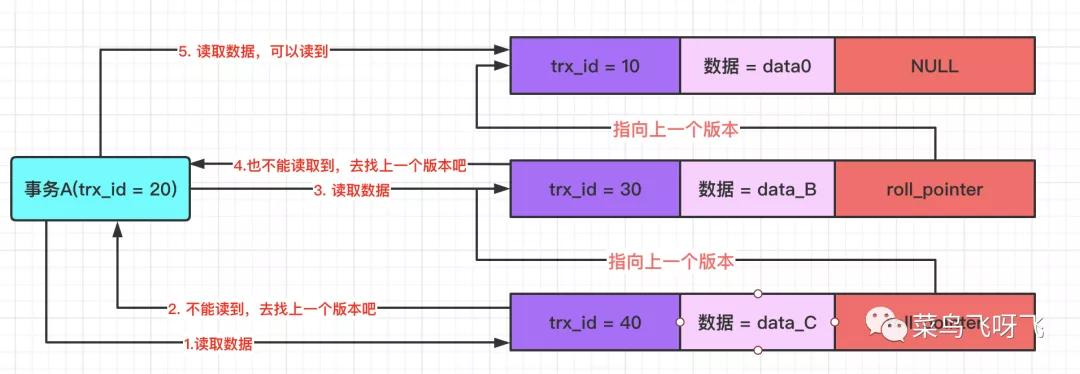
圖11
接著事務 A(trx_id=20)去修改數據,將數據修改為 data_A,那么就會記錄一條 undo log,示意圖如下:
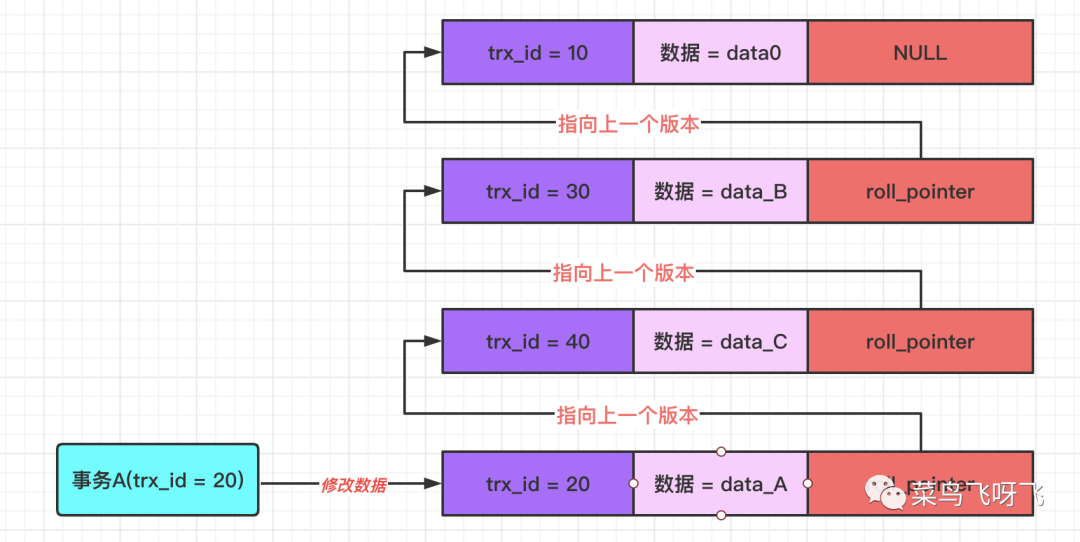
圖12
然后事務 A(trx_id=20)再去讀取數據,在 undo log 版本鏈中,數據最新版本的事務 id 為 20,事務 A 一對比,發現該版本的事務 id 與自己的事務 id 相等,這表示這個版本的數據就是自己修改的,既然是自己修改的,那就肯定能讀取到了,因此此時讀取到是 data_A。
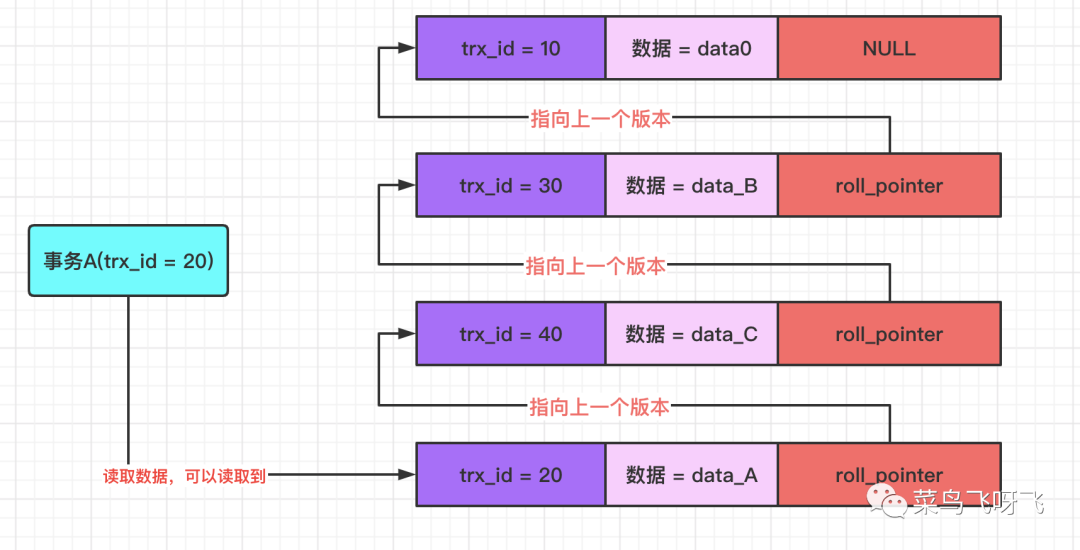
圖13
總結
總結一下,本文主要講解了 undo log 版本鏈是如何形成的,然后講解了 ReadView 的機制是什么,通過幾個例子,配合畫圖,詳細分析了 ReadView 結合 undo log 版本鏈是如何來實現讓當前事務讀取到哪一個版本的數據的,這也就是 MVCC 機制的核心實現原理。
但是到目前為止,只是分析了 ReadView 和 undo log 是如何來實現 MVCC 機制,如何控制事務怎么讀取數據,還沒有結合在具體的事務隔離級別下,MVCC 機制是如何工作的。


























