混合數據湖的好處
在存儲大數據時,數據湖和數據倉庫都是既定術語,但是這兩個術語不是同義詞。數據湖是尚未確定用途的大量原始數據。另一方面,數據倉庫是用于特定目的的結構化過濾數據的存儲庫。
共同點
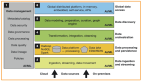
數據倉庫和數據湖代表了一個中央數據庫系統,可以在公司中用于分析目的。該系統從各種異構數據源中提取,收集和保存相關數據,并提供給下游系統。
數據倉庫可以分為四個子過程:
- 數據獲取:從各種數據存儲庫中獲取和提取數據。
- 數據存儲:包括長期歸檔在內的數據倉庫中的數據存儲。
- 數據提供:向下游系統提供所需的數據,提供數據集市。
- 數據評估:對數據庫存的分析和評估。
差異性
數據倉庫將經典的ETL流程與關系數據庫中的結構化數據結合使用,而數據湖則使用諸如ELT的范式和讀取模式以及經常使用的非結構化數據[2]。
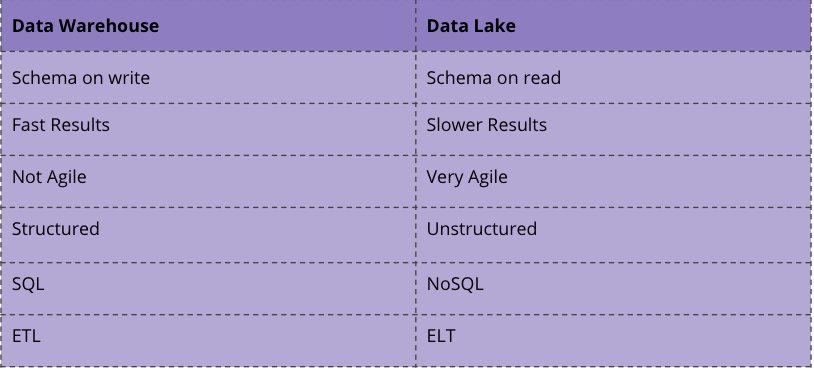
> Differences Data Warehouse vs. Lake
在上方,您可以看到主要區別。您使用的技術也完全不同。對于數據倉庫,您將使用SQL和關系數據庫,而對于數據湖,您可能將使用NoSQL或兩者的混合。
將兩者結合在混合數據湖中
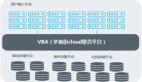
那么如何將這兩個概念結合起來?在下圖中,您可以從高角度查看架構。
該過程是將非結構化和未轉換的數據加載到數據湖中。從這里,一方面可以將數據用于ML和Data Science任務。另一方面,數據也可以轉換為結構化形式并加載到數據倉庫中。從這里,可以實現通過數據集市和(自助服務)BI工具進行的經典數據倉庫分發。
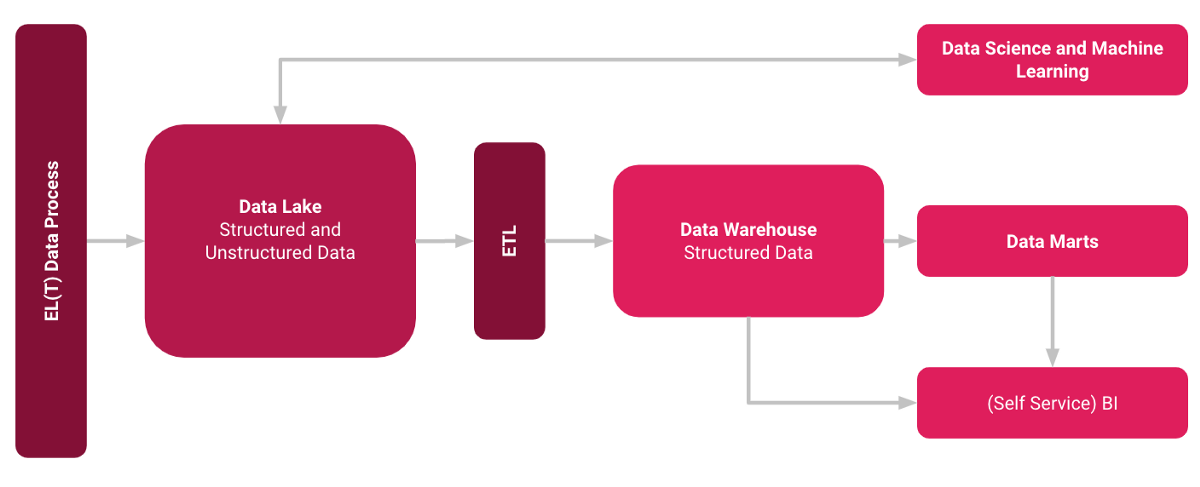
> Hybrid Data Lake Concept — Image from Author
可以用于此體系結構的主要技術例如:
- 通過talend,Google Dataflow,AWS Data Pipeline進行ELT / ETL流程
- 通過Data Lake-HDFS,AWS Athena和S3,Google Cloud Storage
- 數據倉庫通過-Google BigQuery,AWS Redshift,Snowflake
注意:諸如Google的BiqQuery或AWS Redshift之類的技術通常被視為數據倉庫技術與數據湖技術之間的混合體,因為它們通常已經具有NoSQL的某些特征。
結論
本文介紹了如何使用混合數據湖。數據湖使您的公司能夠靈活地以數據形式捕獲業務運營的各個方面,同時保持傳統數據倉庫的生命周期。
原文鏈接:https://towardsdatascience.com/what-is-a-hybrid-data-lake-b7ef2c3cce0c