













需要知識的后深度學習時代,如何高效自動構建知識圖譜?
日常生活中,我們經常遇到以下兩種信息展現方式:

二者展示的信息量是差不多的,但右邊這種看起來更加直觀。而且,隨著文本篇幅的增長,這種優勢會體現得更加明顯。
和人一樣,機器也更加擅長利用右圖所示的數據。但矛盾之處在于,互聯網等數據平臺存儲的大多是左圖所示的數據。要把左圖轉換成右圖,機器需要經歷一個「閱讀理解」的過程。
這個過程如何完成?這就要提到我們今天的主題——知識圖譜。
知識圖譜可以做什么?
知識圖譜的概念于 2012 年由 Google 提出,當時主要被用來提高其搜索引擎質量,改善用戶搜索體驗。隨著大數據時代的到來和人工智能技術的進步,知識圖譜的應用邊界被逐漸拓寬,越來越多的企業開始將知識圖譜技術融入其已經成型的數據分析業務,有的甚至使用知識圖譜作為其數據的基礎組織與存儲形式,成為其數據中臺的核心基建。
與谷歌類似,微軟將知識圖譜技術用于旗下必應(Bing)搜索引擎,優化搜索結果質量和交互式搜索體驗;LinkedIn 與 Facebook 利用知識圖譜挖掘其平臺上人、事、資訊等之間的相互關系,使得用戶更容易發現感興趣的內容、找到志同道合的朋友;eBay、亞馬遜等電商平臺使用知識圖譜為用戶和產品建立聯系,執行更精準的產品推薦;IBM 則專注于企業服務,其 IBM Watson Discovery 產品能夠幫助用戶根據自身的特殊需求快速構建自己的知識圖譜框架。
雖然知識圖譜的概念 2012 年才被提出,但其背后的思想本質上是上個世紀的語義網絡(Semantic Network)知識表達形式,即一個由節點(Point)和邊(Edge)組成的有向圖結構知識庫。其中,圖的節點代表現實世界中存在的“實體”,圖的邊則代表實體之間的“關系”。
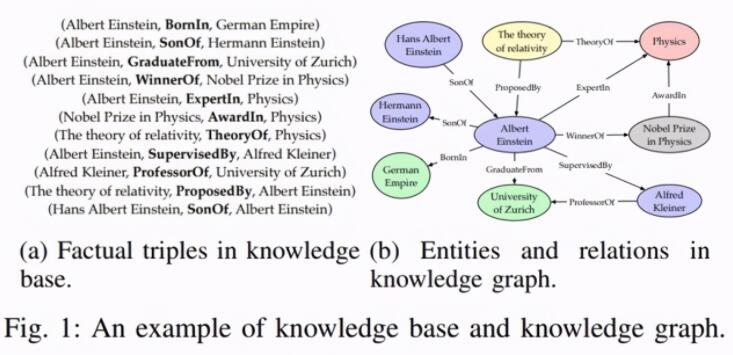
圖 1:傳統知識庫與知識圖譜示意圖 [1]
與傳統的數據存儲和計算方式相比,知識圖譜技術更加側重于對非結構化異構數據的收集和處理,更擅長對于關系的表達和計算,可以處理復雜多樣的關聯分析、挖掘到更多隱藏知識。與此同時,知識圖譜的數據結構與人工智能領域許多技術任務所基于的數據一脈相承(異質結構多關聯的大數據),可以為后續的機器學習和推理任務提供強有力的支持,幫助企業在智能搜索、智能問答、智能推薦、以及大數據分析這幾個方面提升性能。
智能搜索:傳統的搜索引擎依靠網頁之間的鏈接和權重進行搜索排序,而知識圖譜提供了實體的分類、屬性和關系的描述,從而可以直接對事物進行更精準的語義搜索。
智能問答:基于知識圖譜的智能問答是目前產業界問答系統的主要技術路線之一,即對于給定的自然語言問題,利用知識圖譜技術進行語義的解析、查詢、推理以得出答案。該技術常見于智能手機或音箱載體上的智能對話機器人,如 Siri、Google Assistant、Amazon Alexa、小愛同學、天貓精靈,以及微軟的小冰、小娜等,這些智能問答 agent 的背后都有相關企業各自積累的知識圖譜作為問答系統的支撐。
智能推薦:基于知識圖譜的推薦能更好將用戶與被推薦項目之間的各種相互聯系考慮進來,可以增強數據的語義信息、挖掘隱藏的關聯信息,進一步提高推薦的準確度。
大數據分析:基于知識圖譜中實體的關聯信息和推理,我們能挖掘出傳統數據分析較難得到的隱含信息,該優勢在存在大量異構信息的數據集中更為顯著。基于知識圖譜的大數據關聯分析在金融風控、反欺詐乃至安防等應用場景中都有很好的效果。
近年來,知識圖譜的諸多優勢和應用前景使得面向特定領域的知識圖譜構建在行業應用中得到推廣,產生了如醫療知識圖譜、金融知識圖譜、電商圖譜等不同的垂直行業的知識圖譜形態。

圖 2:行業知識圖譜應用一覽 [2]
如何構建知識圖譜?
一般來說,構建一個知識圖譜通常會經歷知識獲取、知識表示與建模、知識融合、知識存儲,以及構建完成后的知識查詢和推理幾大要素:
知識獲取:從不同來源、不同結構的數據中抽取知識(實體、關系以及屬性等信息),這是知識圖譜構建的核心與前提條件。
知識表示與建模:為知識制定統一的數據架構(data schema),將獲取到的知識依照統一的數據結構存儲并形成知識庫,這是知識圖譜正式構建的第一步,影響著后續的知識融合、存儲以及查詢推理可以使用的方法與效果。
知識融合:將不同源的知識以統一的框架規范進行驗證、消歧、加工等異構數據整合工作,這是知識圖譜更新與合并的必經之路,為不同知識圖譜間的交互融合提供可能性。
知識存儲:依據數據量的大小、數據特征以及應用需求的不同,選取合適的存儲模式,將獲取到的數據存儲起來,形成知識圖譜。
知識查詢與推理:基于構建完成的知識圖譜進行查詢,或者進一步推理挖掘出隱藏知識來豐富、擴展知識圖譜,這是知識圖譜構建的最終目的,與知識獲取共同影響著知識圖譜的應用場景和范圍。
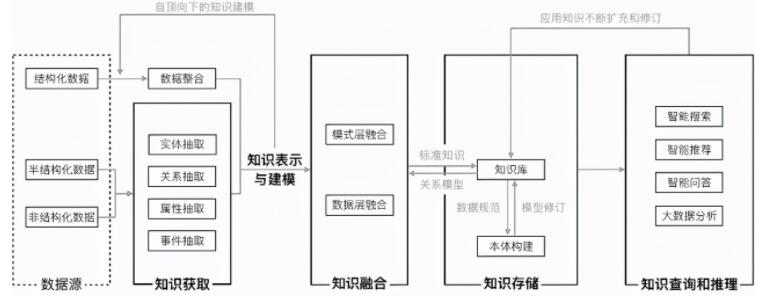
圖 3:知識圖譜構建的要素與示例流程
在執行正式的知識獲取步驟之前,通常會首先確認知識的建模表示方式,主要的方式有兩種:
先為知識圖譜設計數據模式(data schema),再依據設計好的數據模式進行有針對性的數據抽取,這是自頂向下(top-down)的數據建模方法,一般適用于數據相對集中、知識結構相對確定的垂直領域行業知識圖譜;
先進行數據的收集和整理,再根據數據內容總結、歸納其特點,提煉框架,逐步形成確定的數據模式,這是自底向上(bottom-up)的數據建模方法,一般適用于與涉及海量數據、內容繁雜且架構不清晰的公共領域通用知識圖譜。
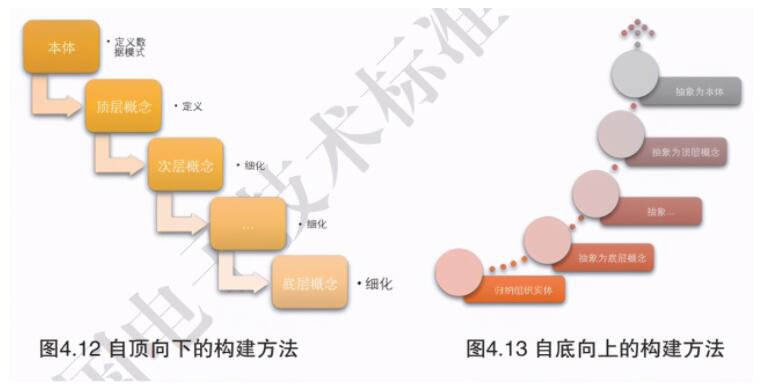
圖 4:知識圖譜數據建模方法 [3]
知識圖譜構建的核心技術、局限與發展方向
知識獲取是構建知識圖譜的核心與前提條件,也是自動構建知識圖譜最關鍵的影響要素和重點研究領域。除了純人工的知識輸入之外,目前的知識獲取主要是指針對結構化數據(如關系型數據庫)、半結構化數據(如詞典、百科類標記清晰的網頁數據)、或者非結構化數據(如聲音、圖像和文字語料數據)這三類不同結構的知識進行的自動或半自動抽取。
對于結構和半結構化的數據,通常只需要簡單的預處理和映射即可以作為后續數據分析系統的輸入,相關技術已經比較成熟。而非結構化數據通常需要借助自然語言處理、信息抽取、乃至深度學習的技術來幫助提取有效信息,這也是目前知識抽取技術的主要難點和研究方向,包含實體抽取、關系抽取和事件抽取三個重要的子技術任務。
實體抽取:主要是指命名實體識別(Named Entity Recognition, NER)任務,即從純文本中自動識別并提出特定類別的命名實體,如人物、組織、地點、時間、金額等。實體抽取是知識抽取中最基礎的步驟,早期主要是通過人工編寫規則的方式進行抽取,但規則不易總結、成本高且移植性差,目前主要是作為補充方法使用。在這之后,實體抽取多采用基于特征的統計方法,使用如隱馬爾可夫(HMM)和條件隨機場(CRF)等模型,將實體抽取當做序列標注問題進行預測標注。而近年來,隨著深度學習的發展,目前較流行的方法是將統計方法與深度神經網絡相結合,使用如長短期記憶網絡(LSTM)自動提取特征,再結合 CRF 模型標注提取實體,自動化程度更高,適用范圍更廣。
關系抽取:指從文本中識別抽取實體之間的關系,抽取結果常使用 SPO 結構(即主謂賓結構)的三元組來表示。與實體抽取類似,早期主要使用基于模板的方法(觸發詞模板、依存句法分析模板等),近年來開始發展出半自動的基于監督學習的方法(CNN、RNN 等)和純自動的基于弱監督學習的方法(遠程監督、Boostrapping 等)。目前在關系抽取任務上取得最佳表現的模型大多融入了注意力機制,如 Attention CNNs 模型和 Attention BLSTM 模型等。
事件抽取:指識別文本中目標事件的信息,并以結構化的形式呈現。例如從投融資新聞中定位融資公司、融資金額、投資企業等信息;或是從恐怖襲擊事件的新聞報道中識別提取出襲擊發生的時間、地點和受害人信息等。事件抽取同時涉及到實體和關系抽取的相關技術。從宏觀的事件抽取思路上來看,事件抽取的方法可分為流水線抽取和聯合抽取兩大類方法。流水線抽取的思路是將事件抽取任務進一步分解為事件識別、元素抽取、屬性分類等一條流水線上的多個子任務,分別使用相應的機器學習分類器實現,這是目前事件抽取的主流方法。聯合抽取則主要是采用基于概率圖的模型進行聯合建模,或基于深度學習的方法(如基于注意力機制的序列標注模型),將事件的多個元素作為一個整體共同識別并提取。
移動互聯網、云計算、以及物聯網等技術的快速發展開啟了一個大規模生產、分析和應用數據的大數據時代。然而,互聯網上只有少數的結構或半結構化的數據知識可方便直接地被機器解析。對于非結構化數據的知識抽取尚達不到完全取代人工的準確度要求,而依靠人工編輯的知識圖譜構建有著高成本、低效率的問題。根據德國 Mannheim 大學的研究者估算 [5],手動創建一個三元組(即一條記錄)的成本在 2 到 6 美元之間。那么,使用純人工的方式構建一個大型知識圖譜的總成本就會在數百萬到數十億美元之間。相比較而言,自動創建知識圖譜的成本可以降低 15 到 250 倍左右,即一個三元組需要 1 美分到 15 美分左右的成本。因此,如何應用自動化知識抽取技術,在廣泛的自由文本信息中自動且準確地提取高質量、結構化知識,將成為知識圖譜構建的重要突破點。
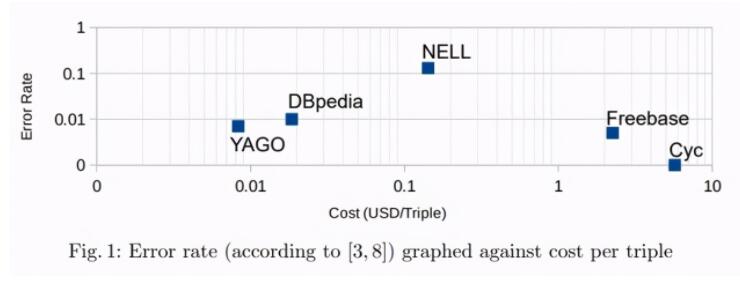
圖 5:每個三元組成本與錯誤率之間的關系示意 [5]
前沿的知識圖譜自動構建技術
知識獲取是知識圖譜自動構建的核心,而非結構化知識又是知識獲取里面最需要攻克的技術難點。近年來,深度學習和相關自然語言處理技術的迅猛發展使得非結構化數據的自動知識抽取少人化、乃至無人化成為了可能。與傳統方法相比,深度學習方法減少了對外部工具的依賴,能構建端到端的系統直接進行實體識別、關系抽取等任務,簡單高效。
在深度學習的基礎上,艾倫人工智能實驗室和微軟的研究人員結合自然語言處理領域較為成功的預訓練語言模型,提出了自動知識圖譜構建模型 COMET(COMmonsEnse Transformers)[8]。該模型可以根據已有常識庫中的自然語言內容自動生成豐富多樣的常識描述,在 Atomic 和 ConcepNet 兩個經典常識圖譜上都取得了接近人類表現的高精度,證明了此類方法在常識知識圖譜自動構建和補全方面替代傳統方法的可行性。
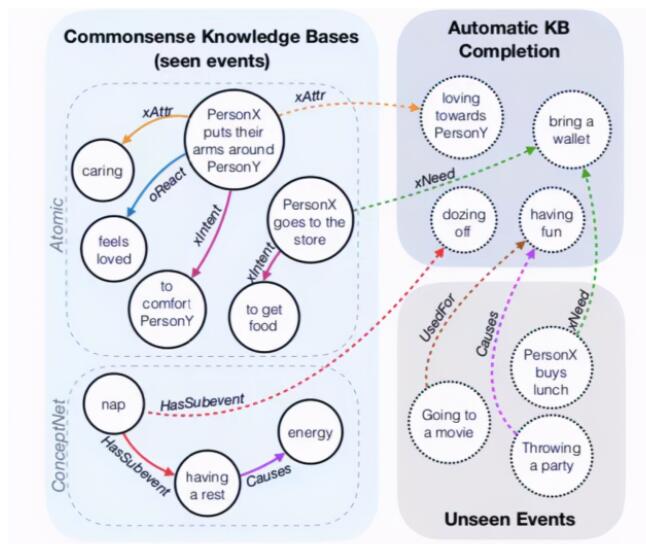
圖 6:COMET 從一個已有知識圖譜中學習(實線),并生成新的節點和邊(虛線) [8]
另一方面,IJCAI 2020 上一篇來自明略科學院知識工程實驗室的論文另辟蹊徑,從傳統的基于文本的知識圖譜生成進一步擴展到了基于語音生成知識圖譜。其 HAO-Graph 系統 [9] 設計并實現了實時的語音圖譜生成架構,并且能夠根據演講者的主題變化在不同的圖譜之間切換。
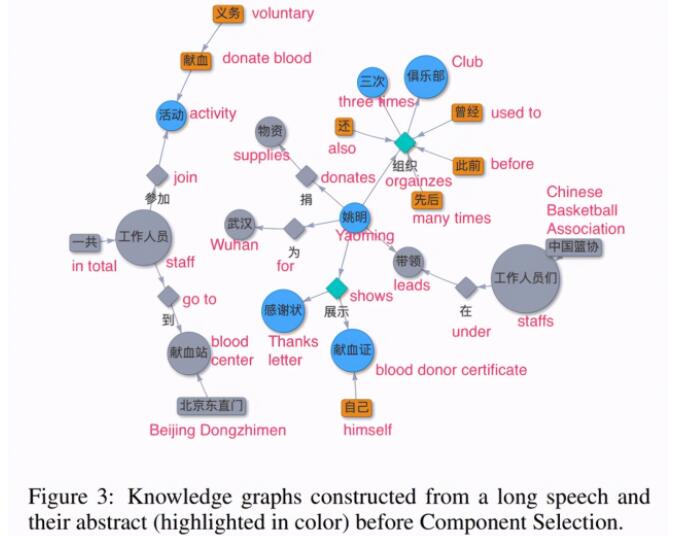
圖 7:結合摘要從一長段語音演講中提取出的知識圖譜示例 [10]
HAO-Graph 基于明略科技的 HAO 智能技術,是已知的首個公開發布的從語音中構建知識圖譜的系統,實現了中文文本和語音知識圖譜的實時生成和可視化。與此同時,明略科技在最近的 WAIC 2020 上還進一步開放了其 Text2KG API 接口,幫助相關從業人員進行知識圖譜底層的數據收集、標注、抽取、以及關聯等相關任務,避免了大量的重復工作,節省開發者的時間。
在深度學習發展進入瓶頸的時期,結合知識成為了下一步人工智能技術突破的關鍵,而知識圖譜必然是核心驅動力之一。我們期待這一技術在未來有更大、更廣的應用。
參考
[1] A Survey on Knowledge Graphs: Representation, Acquisition and Applications
[2] 知識圖譜發展報告(2018)
[3] 知識圖譜標準化白皮書(2019)
[4] 人工智能之知識圖譜(2019)
[5] How much is a Triple?
[6] 67 億美金搞個圖,創建知識圖譜的成本有多高你知道嗎?
[7] A Survey of Deep Learning Methods for Relation Extraction
[8] COMET : Commonsense Transformers for Automatic Knowledge Graph Construction
[9] AI2 等提出自動知識圖譜構建模型 COMET,接近人類表現
[10] A Speech-to-Knowledge-Graph Construction System

























