













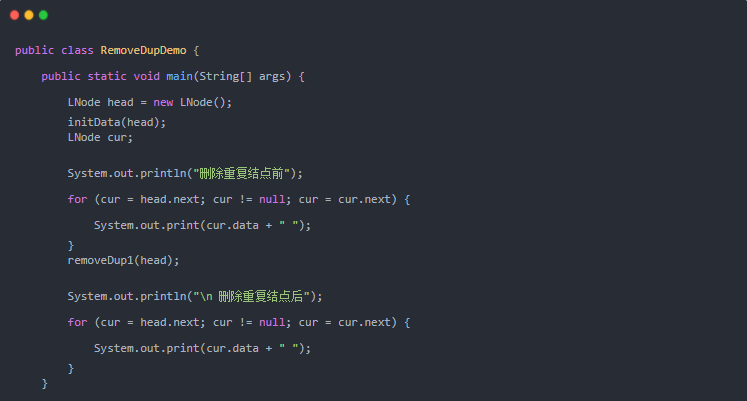
如何從無序鏈表中移除重復項?有幾種方式?
一位小伙伴來問一道谷歌的筆試題,關于單鏈表操作的,問到底有多少種解決方案,今天我們就來聊聊。
題目的大致意思是:
假設存在一個無序單鏈表,將重復結點去除后,并保原順序。
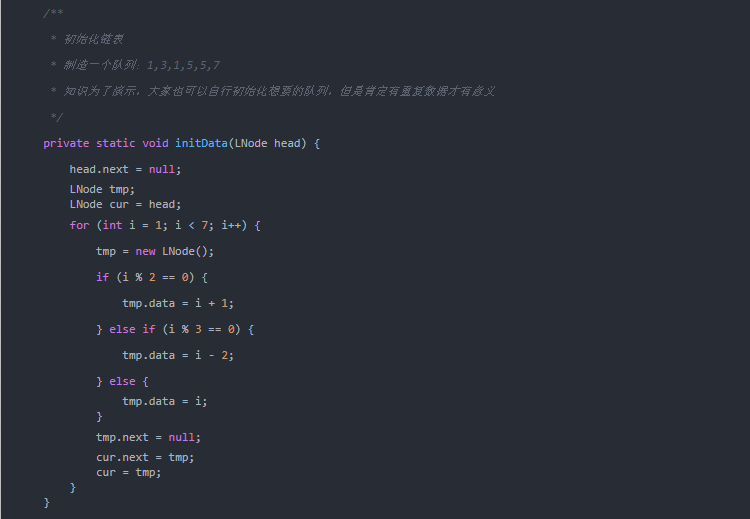
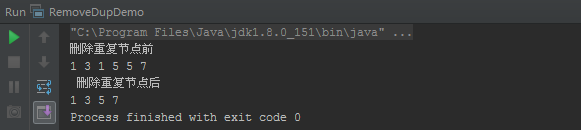
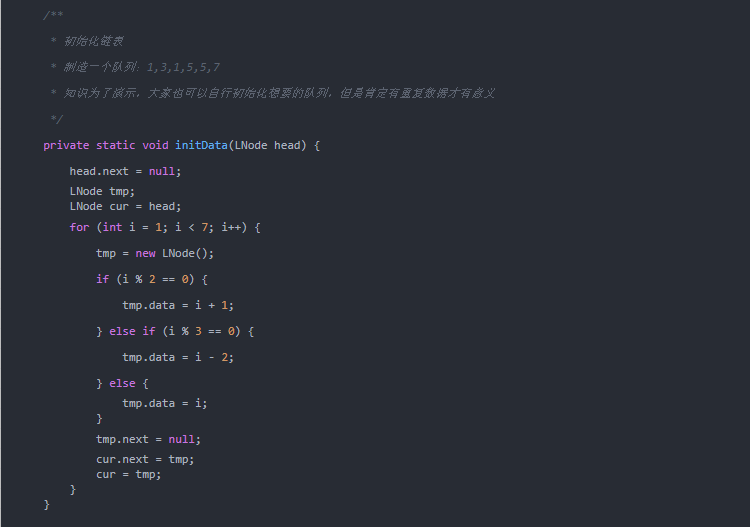
去重前:1→3→1→5→5→7
去重后:1→3→5→7
順序刪除
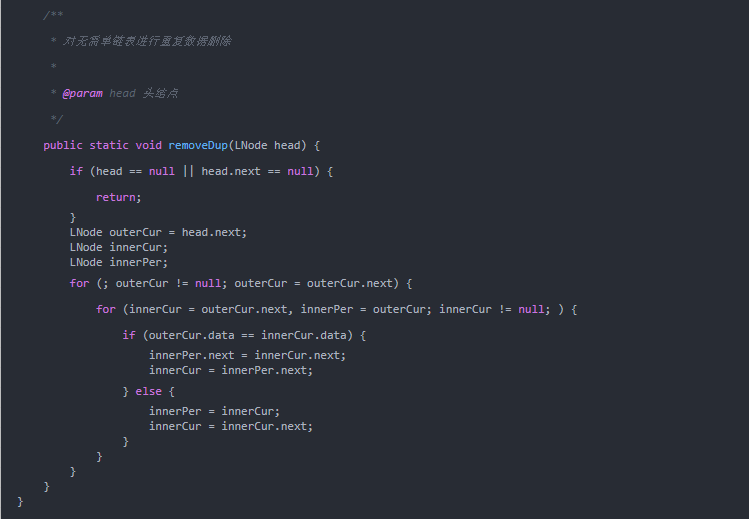
通過雙重循環直接在鏈表上執行刪除操作。外層循環用一個指針從第一個結點開始遍歷整個鏈表,然后內層循環用另外一個指針遍歷其余結點,將與外層循環遍歷到的指針所指結點的數據域相同的結點刪除,如下圖所示。
假設外層循環從outerCur開始遍歷,當內層循環指針innerCur遍歷到上圖實線所示的位置(outerCur.data==innerCur.data)時,此時需要把innerCur指向的結點刪除。
具體步驟如下:
- 用tmp記錄待刪除的結點的地址。
- 為了能夠在刪除tmp結點后繼續遍歷鏈表中其余的結點,使innerCur指針指向它的后繼結點:innerCur=innerCur.next。
- 從鏈表中刪除tmp結點。
實現代碼如下:
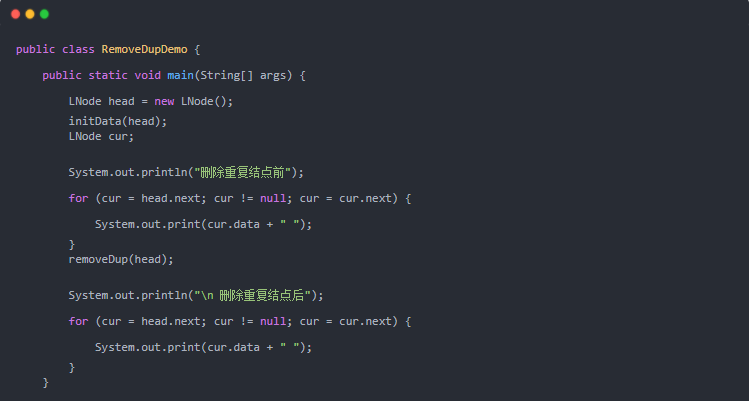
運行結果:
算法性能分析
由于這種方法采用雙重循環對鏈表進行遍歷,因此,時間復雜度為O(N^2)。其中,N為鏈表的長度。在遍歷鏈表的過程中,使用了常量個額外的指針變量來保存當前遍歷的結點、前驅結點和被刪除的結點,因此,空間復雜度為O(1)。
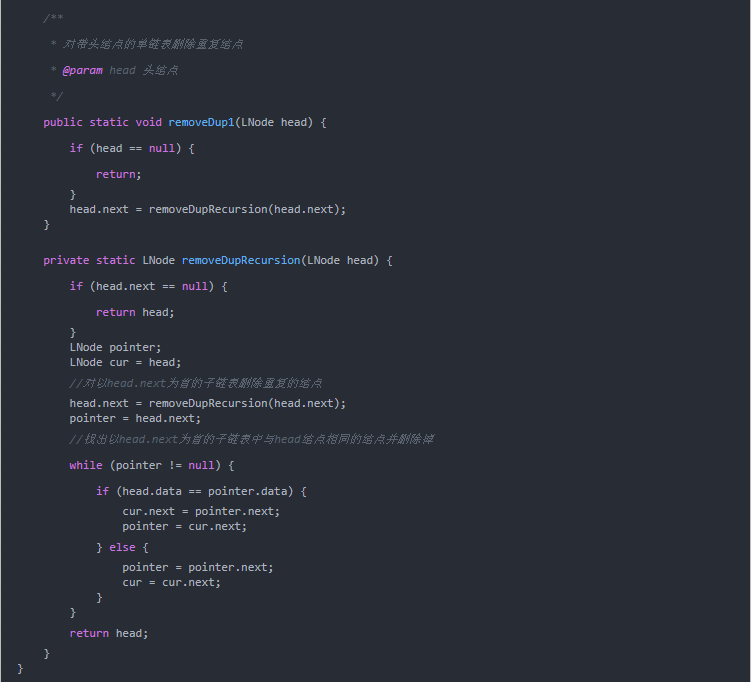
遞歸法
主要思路為:對于結點cur,首先遞歸地刪除以cur.next為首的子鏈表中重復的結點,接著從以cur.next為首的子鏈表中找出與cur有著相同數據域的結點并刪除。
實現代碼如下:
算法性能分析
這種方法與方法一類似,從本質上而言,由于這種方法需要對鏈表進行雙重遍歷,因此,時間復雜度為O(N^2)。其中,N為鏈表的長度。由于遞歸法會增加許多額外的函數調用,因此,從理論上講,該方法效率比前面的方法低。
空間換時間
通常情況下,為了降低時間復雜度,往往在條件允許的情況下,通過使用輔助空間實現。
具體而言,主要思路如下。
- 建立一個HashSet,HashSet中的內容為已經遍歷過的結點內容,并將其初始化為空。
- 從頭開始遍歷鏈表中的所以結點,存在以下兩種可能性:
- 如果結點內容已經在HashSet中,則刪除此結點,繼續向后遍歷。
- 如果結點內容不在HashSet中,則保留此結點,將此結點內容添加到HashSet中,繼續向后遍歷。
「引申:如何從有序鏈表中移除重復項?」
如鏈表:1,3、5、5、7、7、8、9
去重后:1,3、5、7、8、9
分析與解答
上述介紹的方法也適用于鏈表有序的情況,但是由于以上方法沒有充分利用到鏈表有序這個條件,因此,算法的性能肯定不是最優的。本題中,由于鏈表具有有序性,因此,不需要對鏈表進行兩次遍歷。所以,有如下思路:用cur 指向鏈表第一個結點,此時需要分為以下兩種情況討論。
- 如果cur.data==cur.next.data,那么刪除cur.next結點。
- 如果cur.data!=cur.next.data,那么cur=cur.next,繼續遍歷其余結點。
總結
對于無序單鏈表中,想要刪除其中重復的結點(多個重復結點保留一個)。刪除辦法有按照順序刪除、使用遞歸方式刪除以及可以使用空間換時間(HashSet中元素的唯一性)。
最近有讀者想要分布式的項目,還有想要商城的,還有想要springboot,springcloud,k8s等等,這次直接分享幾乎涵蓋了我們java程序員的大部分技術桟,可以說真的非常全面了。強烈建議大家都上手做一做,而且以后肯定用的上。























