沒想到,日志還能這么分析!
本文轉載自微信公眾號「小林coding」,作者小林coding。轉載本文請聯系小林coding公眾號。
很多時候,我們觀察程序是否如期運行,或者是否有錯誤,最直接的方式就是看運行日志,當然要想從日志快速查到我們想要的信息,前提是程序打印的日志要精煉、精準。
但日志涵蓋的信息遠不止于此,比如對于 nginx 的 access.log 日志,我們可以根據日志信息分析用戶行為。
什么用戶行為呢?比如分析出哪個頁面訪問次數(PV)最多,訪問人數(UV)最多,以及哪天訪問量最多,哪個請求訪問最多等等。
這次,將用一個大概幾萬條記錄的 nginx 日志文件作為案例,一起來看看如何分析出「用戶信息」。
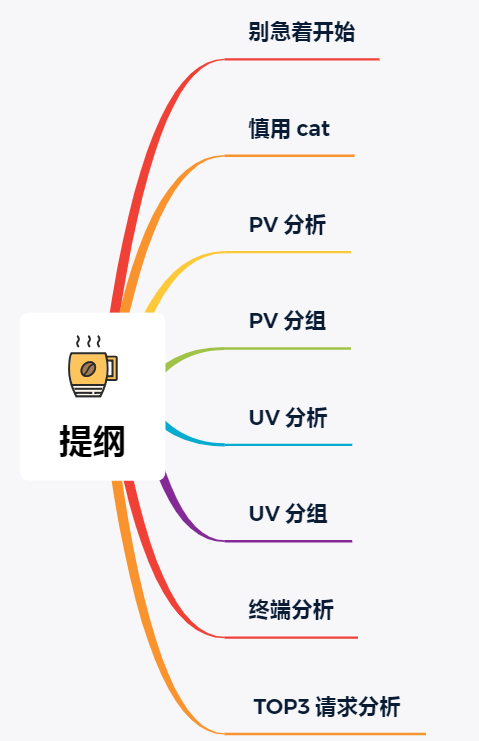
別急著開始
當我們要分析日志的時候,先用 ls -lh 命令查看日志文件的大小,如果日志文件大小非常大,最好不要在線上環境做。
比如我下面這個日志就 6.5M,不算大,在線上環境分析問題不大。

如果日志文件數據量太大,你直接一個 cat 命令一執行,是會影響線上環境,加重服務器的負載,嚴重的話,可能導致服務器無響應。
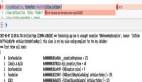
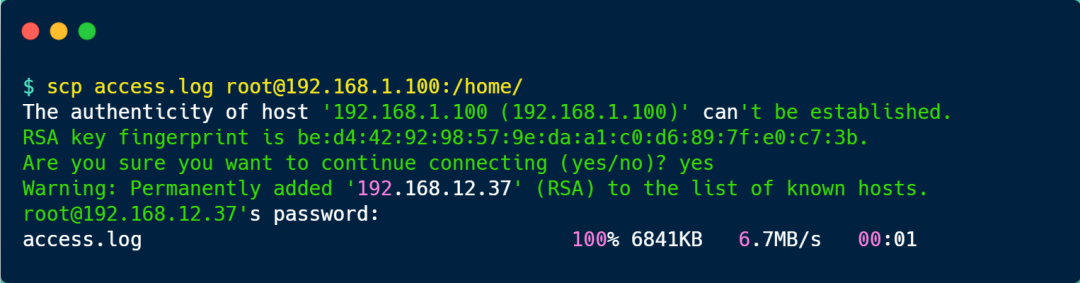
當發現日志很大的時候,我們可以使用 scp 命令將文件傳輸到閑置的服務器再分析,scp 命令使用方式如下圖:
慎用 cat
大家都知道 cat 命令是用來查看文件內容的,但是日志文件數據量有多少,它就讀多少,很顯然不適用大文件。
對于大文件,我們應該養成好習慣,用 less 命令去讀文件里的內容,因為 less 并不會加載整個文件,而是按需加載,先是輸出一小頁的內容,當你要往下看的時候,才會繼續加載。
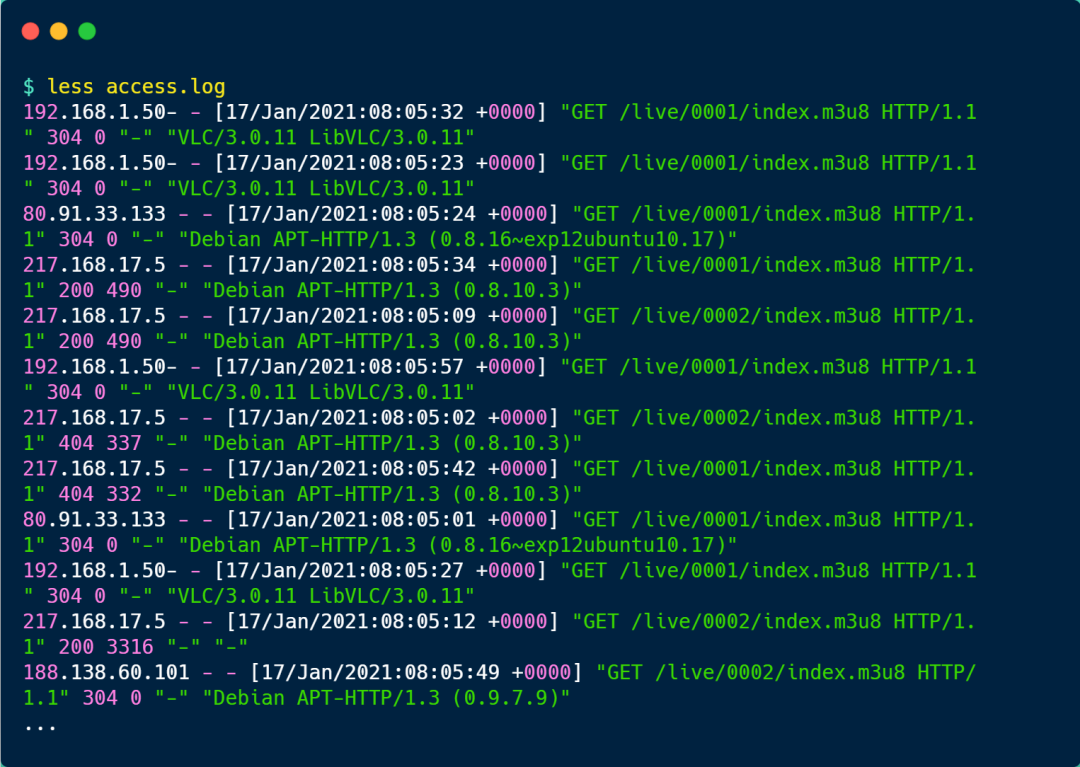
可以發現,nginx 的 access.log 日志每一行是一次用戶訪問的記錄,從左到右分別包含如下信息:
- 客戶端的 IP 地址;
- 訪問時間;
- HTTP 請求的方法、路徑、協議版本、協議版本、返回的狀態碼;
- User Agent,一般是客戶端使用的操作系統以及版本、瀏覽器及版本等;
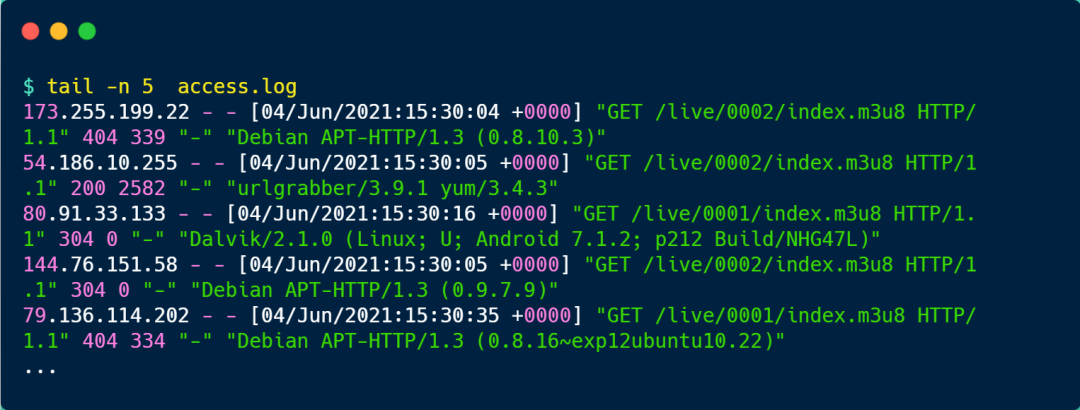
不過,有時候我們想看日志最新部分的內容,可以使用 tail 命令,比如當你想查看倒數 5 行的內容,你可以使用這樣的命令:
如果你想實時看日志打印的內容,你可以使用 tail -f 命令,這樣你看日志的時候,就會是阻塞狀態,有新日志輸出的時候,就會實時顯示出來。
PV 分析
PV 的全稱叫 Page View,用戶訪問一個頁面就是一次 PV,比如大多數博客平臺,點擊一次頁面,閱讀量就加 1,所以說 PV 的數量并不代表真實的用戶數量,只是個點擊量。
對于 nginx 的 acess.log 日志文件來說,分析 PV 還是比較容易的,既然日志里的內容是訪問記錄,那有多少條日志記錄就有多少 PV。
我們直接使用 wc -l 命令,就可以查看整體的 PV 了,如下圖一共有 49903 條 PV。

PV 分組
nginx 的 acess.log 日志文件有訪問時間的信息,因此我們可以根據訪問時間進行分組,比如按天分組,查看每天的總 PV,這樣可以得到更加直觀的數據。
要按時間分組,首先我們先「訪問時間」過濾出來,這里可以使用 awk 命令來處理,awk 是一個處理文本的利器。
awk 命令默認是以「空格」為分隔符,由于訪問時間在日志里的第 4 列,因此可以使用 awk '{print $4}' access.log 命令把訪問時間的信息過濾出來,結果如下:

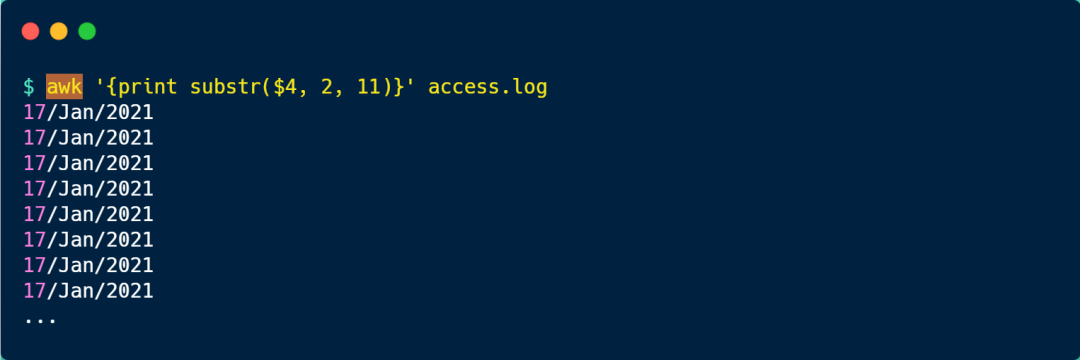
上面的信息還包含了時分秒,如果只想顯示年月日的信息,可以使用 awk 的substr 函數,從第 2 個字符開始,截取 11 個字符。
接著,我們可以使用 sort 對日期進行排序,然后使用 uniq -c 進行統計,于是按天分組的 PV 就出來了。
可以看到,每天的 PV 量大概在 2000-2800:
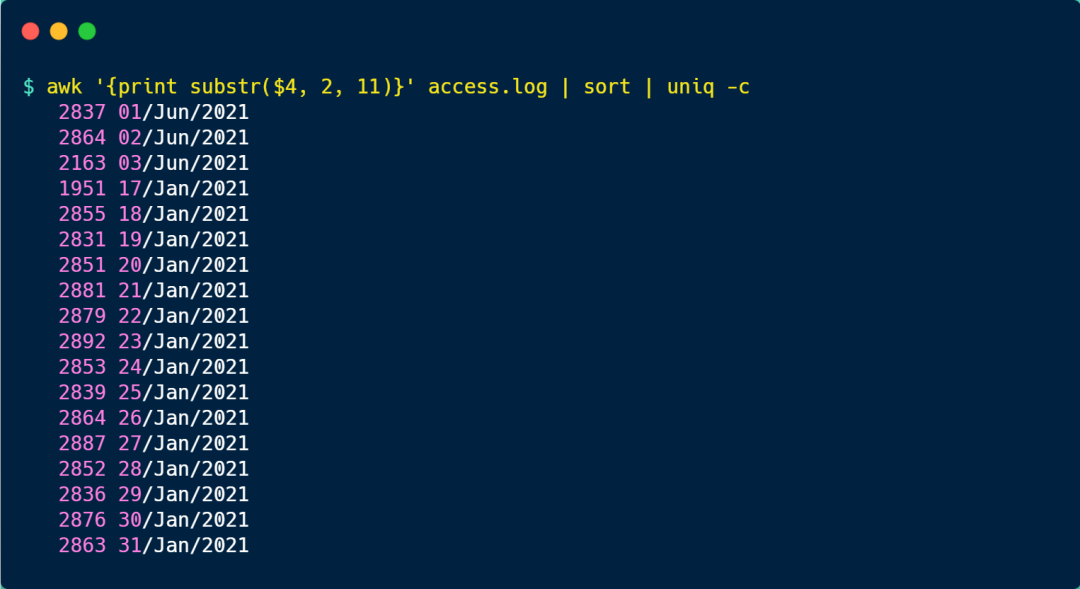
注意,使用 uniq -c 命令前,先要進行 sort 排序,因為 uniq 去重的原理是比較相鄰的行,然后除去第二行和該行的后續副本,因此在使用 uniq 命令之前,請使用 sort 命令使所有重復行相鄰。
UV 分析
UV 的全稱是 Uniq Visitor,它代表訪問人數,比如公眾號的閱讀量就是以 UV 統計的,不管單個用戶點擊了多少次,最終只算 1 次閱讀量。
access.log 日志里雖然沒有用戶的身份信息,但是我們可以用「客戶端 IP 地址」來近似統計 UV。

該命令的輸出結果是 2589,也就說明 UV 的量為 2589。上圖中,從左到右的命令意思如下:
- awk '{print $1}' access.log,取日志的第 1 列內容,客戶端的 IP 地址正是第 1 列;
- sort,對信息排序;
- uniq,去除重復的記錄;
- wc -l,查看記錄條數;
UV 分組
假設我們按天來分組分析每天的 UV 數量,這種情況就稍微比較復雜,需要比較多的命令來實現。
既然要按天統計 UV,那就得把「日期 + IP地址」過濾出來,并去重,命令如下:
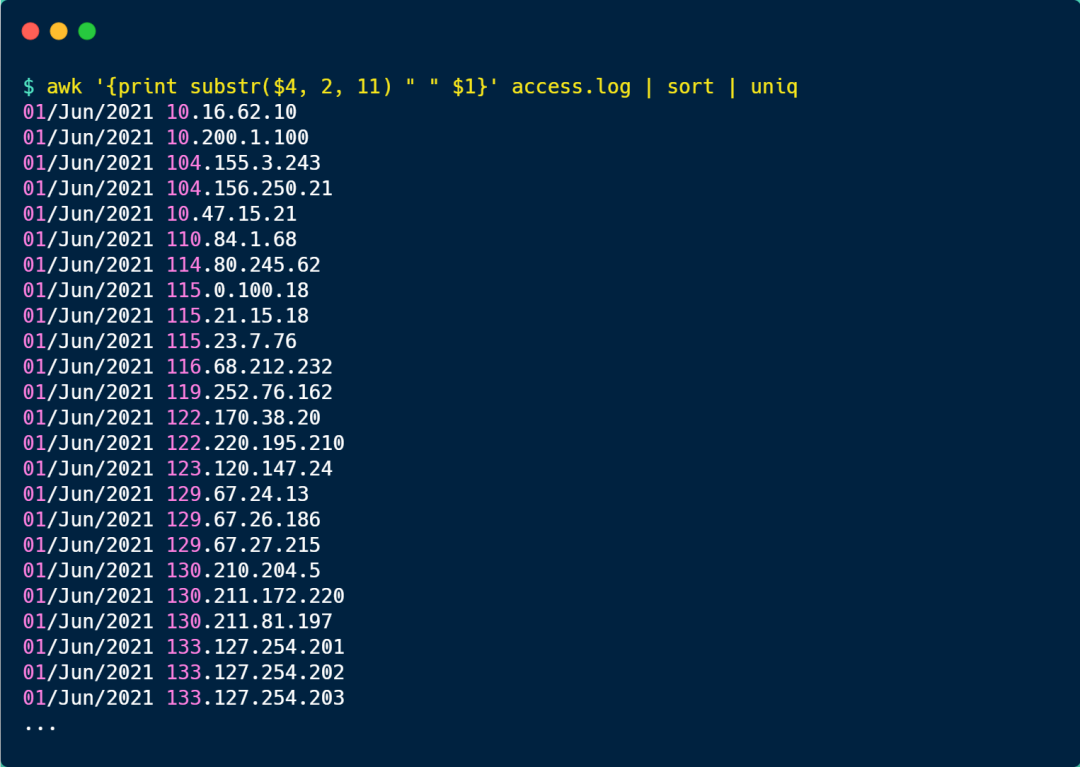
具體分析如下:
- 第一次 ack 是將第 4 列的日期和第 1 列的客戶端 IP 地址過濾出來,并用空格拼接起來;
- 然后 sort 對第一次 ack 輸出的內容進行排序;
- 接著用 uniq 去除重復的記錄,也就說日期 +IP 相同的行就只保留一個;
上面只是把 UV 的數據列了出來,但是并沒有統計出次數。
如果需要對當天的 UV 統計,在上面的命令再拼接 awk '{uv[$1]++;next}END{for (ip in uv) print ip, uv[ip]}' 命令就可以了,結果如下圖:
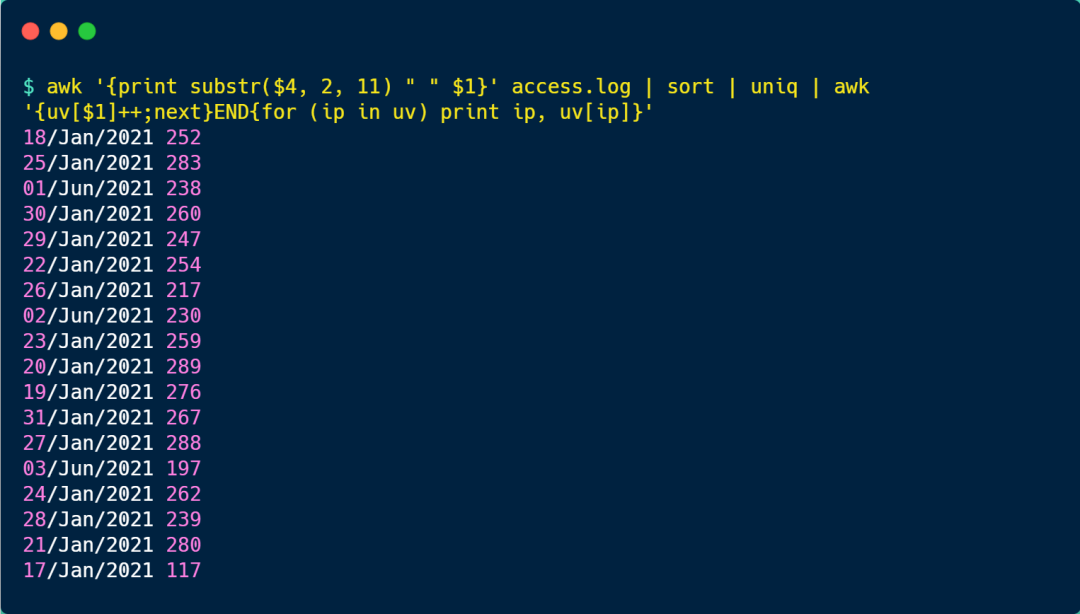
awk 本身是「逐行」進行處理的,當執行完一行后,我們可以用 next 關鍵字來告訴 awk 跳轉到下一行,把下一行作為輸入。
對每一行輸入,awk 會根據第 1 列的字符串(也就是日期)進行累加,這樣相同日期的 ip 地址,就會累加起來,作為當天的 uv 數量。
之后的 END 關鍵字代表一個觸發器,就是當前面的輸入全部完成后,才會執行 END {} 中的語句,END 的語句是通過 foreach 遍歷 uv 中所有的 key,打印出按天分組的 uv 數量。
終端分析
nginx 的 access.log 日志最末尾關于 User Agent 的信息,主要是客戶端訪問服務器使用的工具,可能是手機、瀏覽器等。
因此,我們可以利用這一信息來分析有哪些終端訪問了服務器。
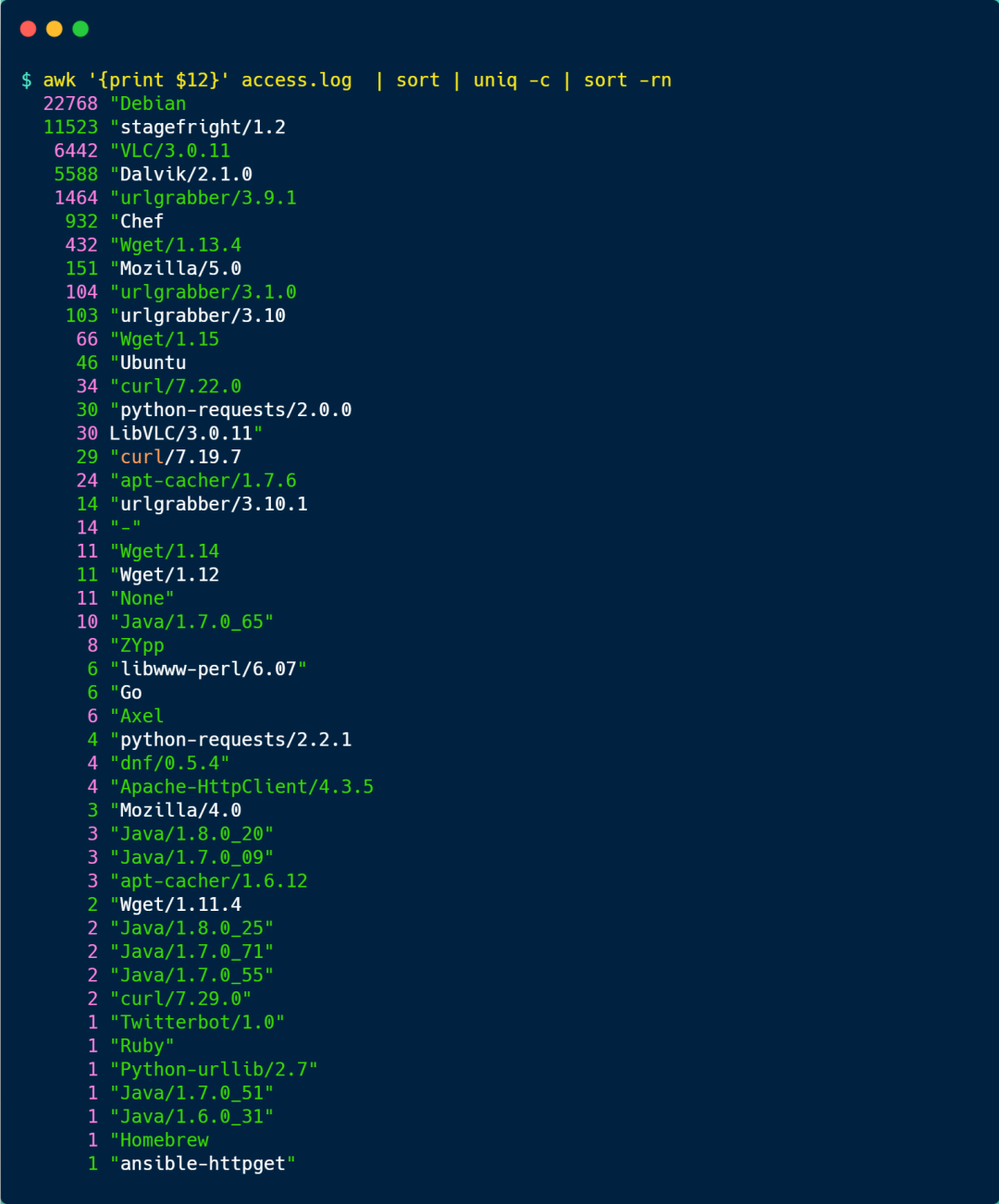
User Agent 的信息在日志里的第 12 列,因此我們先使用 awk 過濾出第 12 列的內容后,進行 sort 排序,再用 uniq -c 去重并統計,最后再使用 sort -rn(r 表示逆向排序, n 表示按數值排序) 對統計的結果排序,結果如下圖:
分析 TOP3 的請求
access.log 日志中,第 7 列是客戶端請求的路徑,先使用 awk 過濾出第 7 列的內容后,進行 sort 排序,再用 uniq -c 去重并統計,然后再使用 sort -rn 對統計的結果排序,最后使用 head -n 3 分析 TOP3 的請求,結果如下圖:

原文鏈接:https://mp.weixin.qq.com/s/c1QXIeYR0zRrzTXWxFNxCw