不要用arxiv鏈接了!引用更規(guī)范,華人博士創(chuàng)建了一個小工具
只需兩步,將文獻的 arXiv 信息轉換為正式來源信息。
伴隨著預印本平臺 arXiv 的廣泛使用,越來越多的研究者喜歡在寫論文參考文獻時直接使用 arXiv 信息。這看似非常方便,但也存在問題:這篇 arXiv 論文是否在 ACL、EMNLP、NAACL、ICLR 或 AAAI 等學術會議上發(fā)表過?
沒錯,在某些情況下,只引用 arXiv 信息顯得不那么準確,這種不準確的文獻條目甚至可能會違反某些會議的論文提交或 camera-ready 版本提交規(guī)則。
如何解決這一問題呢?最近,上交畢業(yè)生、南加州大學博士生林禹臣開發(fā)了一個簡單的 Python 工具——Rebiber,它能夠基于 ACL Anthology 和 DBLP 數(shù)據(jù)庫自動解決這一問題。
項目地址:https://github.com/yuchenlin/rebiber

下圖展示了 Rebiber 的使用示例:
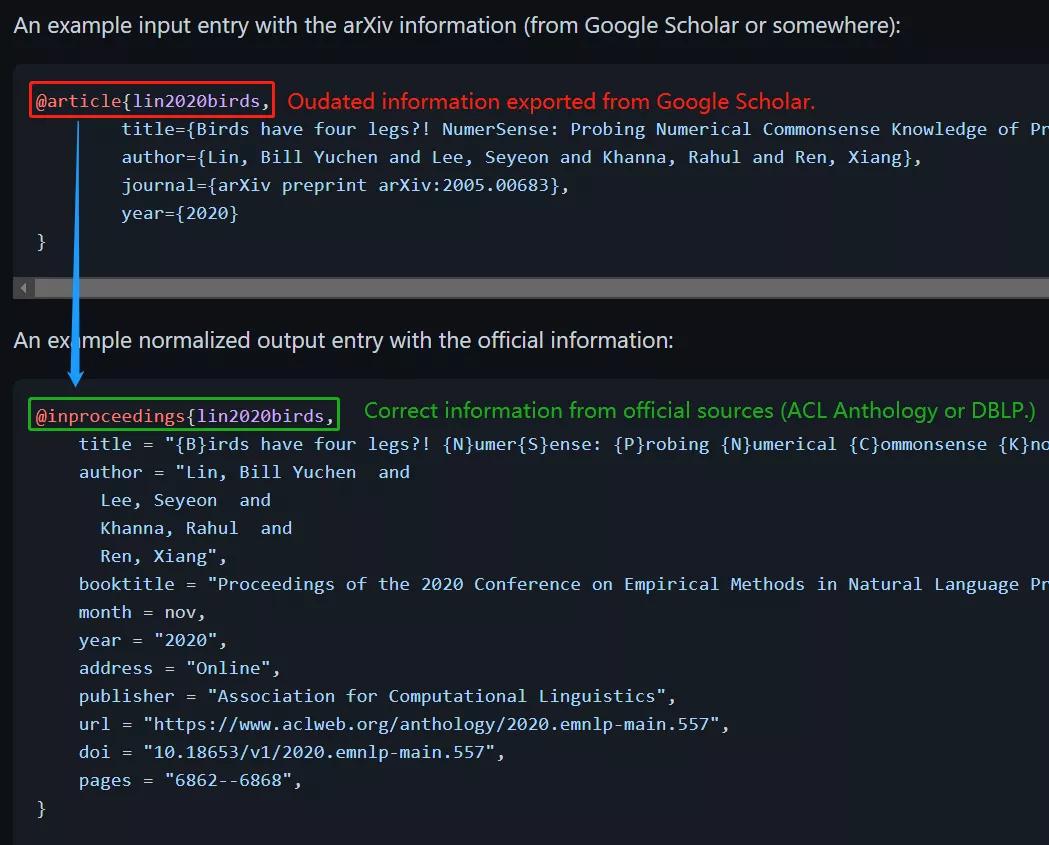
在該示例中,文章的原始信息來自 Google Scholar,僅包括標題、作者、期刊(arXiv)、年份。而事實上該論文已被 EMNLP 2020 接收,原始信息顯然不夠準確。
經過 Rebiber 轉換后,原始 arXiv 信息被轉換為來自正式來源的準確信息,包括標題、作者、年月、出版商、數(shù)字對象識別碼(doi)、網址等詳細內容。
Rebiber 支持的會議包括 ACL Anthology 涵蓋的會議,如 ACL、EMNLP、NAACL 及其 workshop,以及 DBLP 涵蓋的會議,如 ICLR 2020。
目前,Rebiber 支持的會議列表如下所示:
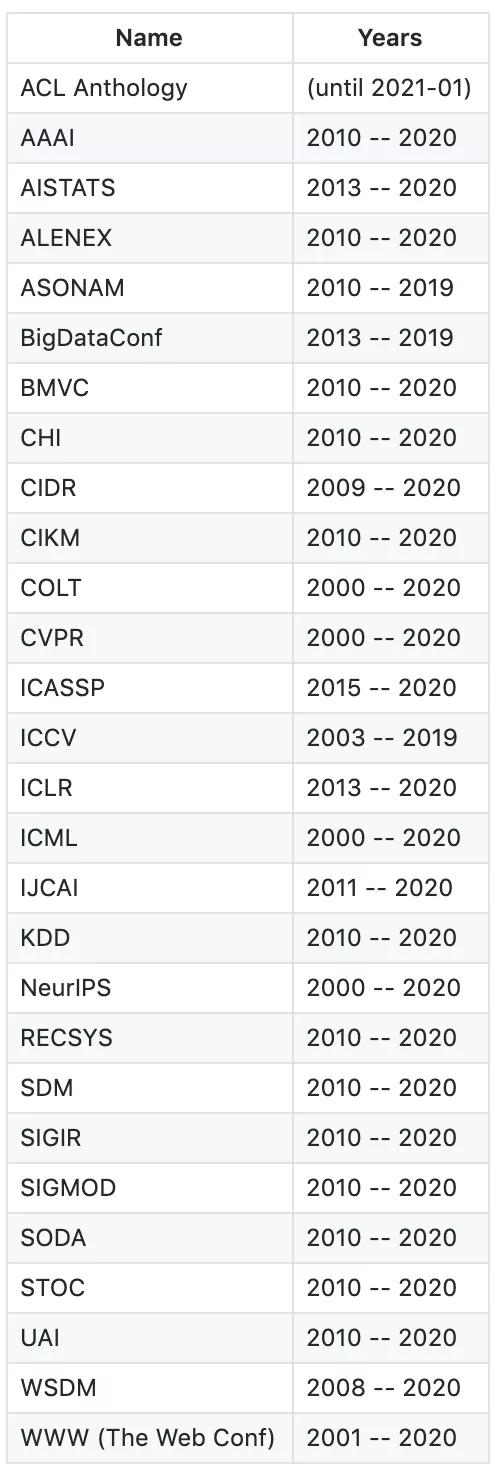
使用者還可以手動添加 DBLP 包含的任意會議:只需從 DBLP 中下載會議 bib 文件至 data 文件夾,然后將其轉換為 json 格式,再把路徑添加至 bib_list.txt 即可。
如何使用?
這款工具的使用也很簡單。
首先,運行以下命令行:
- git clone https://github.com/yuchenlin/rebiber.git
- pip install bibtexparser tqdm
- cd rebiber
然后,將文獻條目歸一化為正式格式:
- python normalize.py -i example_input.bib -o example_output.bib -l bib_list.txt
只需要簡單的操作,就可以將 arXiv 信息轉換為正式信息了。
項目作者簡介
項目作者林禹臣本科畢業(yè)于上海交通大學 IEEE 試點班,曾獲上海市優(yōu)秀本科生獎學金、上海交通大學優(yōu)異學士學位論文獎,現(xiàn)在南加州大學攻讀計算機科學博士學位,導師為南加州大學計算機科學學院助理教授、情報與知識發(fā)現(xiàn)(INK)研究實驗室主任任翔。
他曾在微軟亞洲研究院和谷歌 AI 有多段實習經歷,研究興趣包括構建能夠深度理解世界的神經符號系統(tǒng)、集成信息提取、知識圖譜、機器推理、圖神經網絡和模型魯棒性的技術。近期研究集中在利用常識推理推動自然語言處理(理解與生成)。多篇論文發(fā)表在 ICLR、AAAI、EMNLP、KDD、ACL 等學術會議上。