多中心容災實踐:如何實現真正的異地多活?
在異地多活的實現上,數據能夠在三個及以上中心間進行雙向同步,才是解決真正異地多活的核心技術所在。本文基于三中心且跨海外的場景,分享一種多中心容災架構及實現方式,介紹幾種分布式ID生成算法,以及在數據同步上最終一致性的實現過程。
一、背景
為什么稱之為真正的異地多活?異地多活已經不是什么新鮮詞,但似乎一直都沒有實現真正意義上的異地多活。一般有兩種形式:一種是應用部署在同城兩地或多地,數據庫一寫多讀(主要是為了保證數據一致性),當主寫庫掛掉,再切換到備庫上;另一種是單元化服務,各個單元的數據并不是全量數據,一個單元掛掉,并不能切換到其他單元。目前還能看到雙中心的形式,兩個中心都是全量數據,但雙跟多還是有很大差距的,這里其實主要受限于數據同步能力,數據能夠在3個及以上中心間進行雙向同步,才是解決真正異地多活的核心技術所在。
提到數據同步,這里不得不提一下DTS(Data Transmission Service),最初阿里的DTS并沒有雙向同步的能力,后來有了云上版本后,也只限于兩個數據庫之間的雙向同步,做不到A<->B<->C這種形式,所以我們自研了數據同步組件,雖然不想重復造輪子,但也是沒辦法,后面會介紹一些實現細節。
再談談為什么要做多中心容災,以我所在的CDN&視頻云團隊為例,首先是海外業務的需要,為了能夠讓海外用戶就近訪問我們的服務,我們需要提供一個海外中心。但大多數業務還都是以國內為主的,所以國內要建雙中心,防止核心庫掛掉整個管控就都掛掉了。同時海外的環境比較復雜,一旦海外中心掛掉了,還可以用國內中心頂上。國內的雙中心還有個非常大的好處是可以通過一些路由策略,分散單中心系統的壓力。這種三個中心且跨海外的場景,應該是目前異地多活最難實現的了。
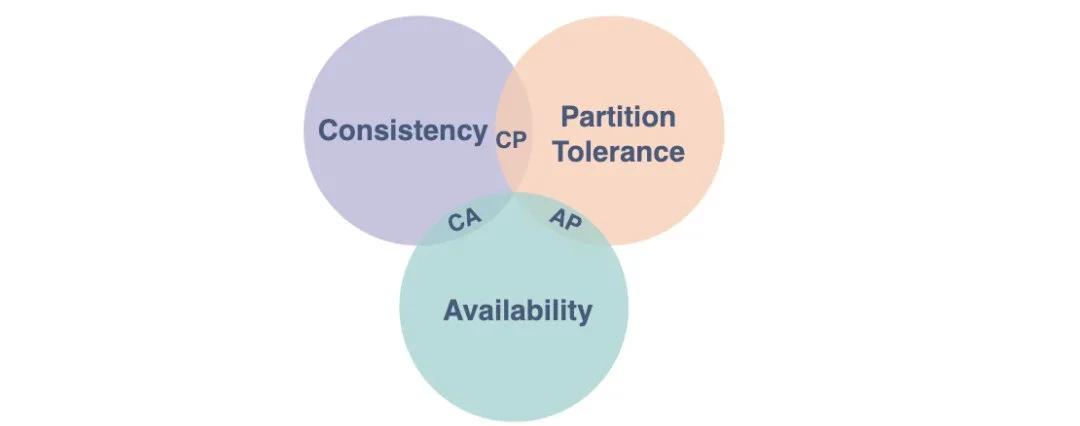
二、系統CAP
面對這種全球性跨地域的分布式系統,我們不得不談到CAP理論,為了能夠多中心全量數據提供服務,Partition tolerance(分區容錯性)是必須要解決的,但是根據CAP的理論,Consistency(一致性)和Availability(可用性)就只能滿足一個。對于線上應用,可用性自不用說了,那面對這樣一個問題,最終一致性是最好的選擇。
三、設計原則
1.數據分區
選擇一個數據維度來做數據切片,進而實現業務可以分開部署在不同的數據中心。主鍵需要設計成分布式ID形式,這樣當進行數據同步時,不會造成主鍵沖突。
下面介紹幾個分布式ID生成算法。
SnowFlake算法
1)算法說明
- +--------------------------------------------------------------------------+
- | 1 Bit Unused | 41 Bit Timestamp | 10 Bit NodeId | 12 Bit Sequence Id |
- +--------------------------------------------------------------------------+
- 最高位是符號位,始終為0,不可用。
- 41位的時間序列,精確到毫秒級,41位的長度可以使用69年。時間位還有一個很重要的作用是可以根據時間進行排序。
- 10位的機器標識,10位的長度最多支持部署1024個節點。
- 12位的計數序列號,序列號即一系列的自增ID,可以支持同一節點同一毫秒生成多個ID序號,12位的計數序列號支持每個節點每毫秒產生4096個ID序號。
2)算法總結
優點:
- 完全是一個無狀態機,無網絡調用,高效可靠。
缺點:
- 依賴機器時鐘,如果時鐘錯誤比如時鐘回撥,可能會產生重復Id。
- 容量存在局限性,41位的長度可以使用69年,一般夠用。
- 并發局限性,每毫秒單機最大產生4096個Id。
- 只適用于int64類型的Id分配,int32位Id無法使用。
3)適用場景
一般的非Web應用程序的int64類型的Id都可以使用。
為什么說非Web應用,Web應用為什么不可以用呢,因為JavaScript支持的最大整型就是53位,超過這個位數,JavaScript將丟失精度。
RainDrop算法
1)算法說明
為了解決JavaScript丟失精度問題,由Snowflake算法改造而來的53位的分布式Id生成算法。
- +--------------------------------------------------------------------------+
- | 11 Bit Unused | 32 Bit Timestamp | 7 Bit NodeId | 14 Bit Sequence Id |
- +--------------------------------------------------------------------------+
- 最高11位是符號位,始終為0,不可用,解決JavaScript的精度丟失。
- 32位的時間序列,精確到秒級,32位的長度可以使用136年。
- 7位的機器標識,7位的長度最多支持部署128個節點。
- 14位的計數序列號,序列號即一系列的自增Id,可以支持同一節點同一秒生成多個Id,14位的計數序列號支持每個節點每秒單機產生16384個Id。
2)算法總結
優點:
- 完全是一個無狀態機,無網絡調用,高效可靠。
缺點:
- 依賴機器時鐘,如果時鐘錯誤比如時鐘不同步、時鐘回撥,會產生重復Id。
- 容量存在局限性,32位的長度可以使用136年,一般夠用。
- 并發局限性,低于snowflake。
- 只適用于int64類型的Id分配,int32位Id無法使用。
3)適用場景
一般的Web應用程序的int64類型的Id都基本夠用。
分區獨立分配算法
1)算法說明
通過將Id分段分配給不同單元獨立管理。同一個單元的不同機器再通過共享redis進行單元內的集中分配。
相當于每個單元預先分配了一批Id,然后再由各個單元內進行集中式分配。
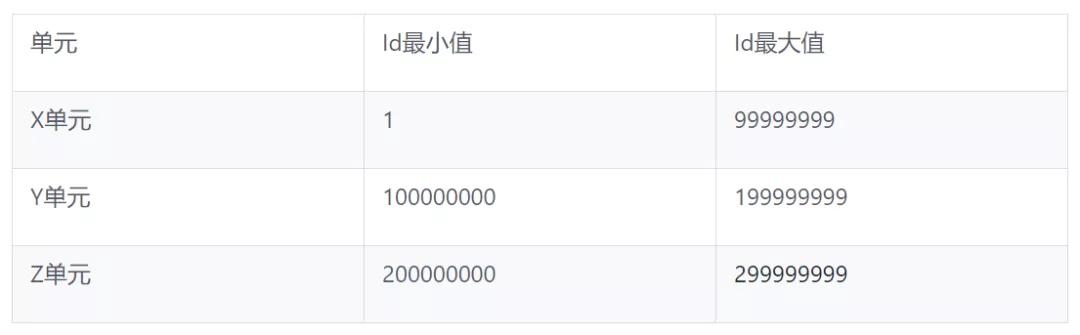
比如int32的范圍從-2147483648到2147483647,Id使用范圍[1,2100000000),前兩位表示region,則每個region支持100000000(一億)個資源,即Id組成格式可以表示為[0-20][0-99999999]。
即int32位可以支持20個單元,每個單元支持一億個Id。
2)算法總結
優點:
- 區域之間無狀態,無網絡調用,具備可靠唯一性
缺點:
- 分區容量存在局限性,需要預先評估業務容量。
- 從Id中無法判斷生成的先后順序。
3)適用場景
適用于int32類型的Id分配,單個區域內容量上限可評估的業務使用。
集中式分配算法
1)算法說明
集中式可以是Redis,也可以是ZooKeeper,也可以利用數據庫的自增Id集中分配。
2)算法總結
優點:
- 全局遞增
- 可靠的唯一性Id
- 無容量和并發量限制
缺點:
- 增加了系統復雜性,需要強依賴中心服務。
3)適用場景
具備可靠的中心服務的場景可以選用,其他int32類型無法使用分區獨立分配的業務場景。
總結
每一種分配算法都有各自的適用場景,需要根據業務需求選擇合適的分配算法。主要需要考慮幾個因素:
- Id類型是int64還是int32。
- 業務容量以及并發量需求。
- 是否需要與JavaScript交互。
2.中心封閉
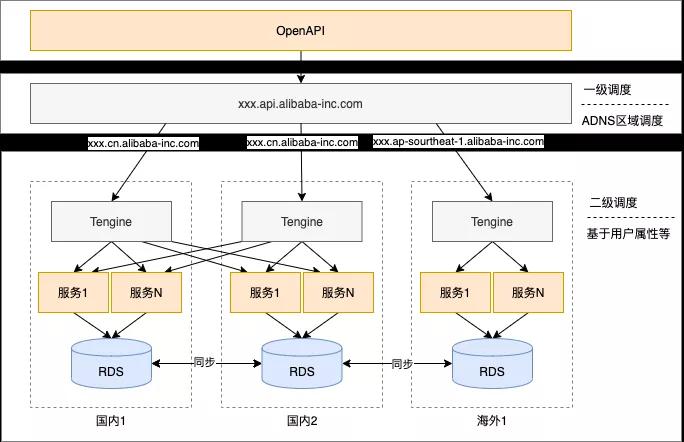
盡量讓調用發生在本中心,盡量避免跨數據中心的調用,一方面為了用戶體驗,本地調用RT更短,另一方面防止同一個數據在兩個中心同時寫入造成數據沖突覆蓋。一般可以選擇一種或多種路由方式,如ADNS根據地域路由,通過Tengine根據用戶屬性路由,或者通過sidecar方式進行路由,具體實現方式這里就不展開說了。
3.最終一致性
前面兩種其實就是為了最終一致性做鋪墊,因為數據同步是犧牲了一部分實時的性能,所以我們需要做數據分區,做中心封閉,這樣才能保證用戶請求的及時響應和數據的實時準確性。
前面提到了由于DTS支持的并不是很完善,所以我基于DRC(一個阿里內部數據訂閱組件,類似canal)自己實現了數據同步的能力,下面介紹一下實現一致性的過程,中間也走了一些彎路。
順序接收DRC消息
為了保證對于DRC消息順序的接收,首先想到的是采用單機消費的方式,而單機帶來的問題是數據傳輸效率慢。針對這個問題,涉及到并發的能力。大家可能會想到基于表級別的并發,但是如果單表數據變更大,同樣有性能瓶頸。這里我們實現了主鍵級別的并發能力,也就是說在同一主鍵上,我們嚴格保序,不同主鍵之間可以并發同步,將并發能力又提高了N個數量級。
同時單機消費的第二個問題就是單點。所以我們要實現Failover。這里我們采用Raft協議進行多機選主以及對主的請求。當單機掛掉之后,其余的機器會自動選出新的Leader執行同步任務。
消息跨單元傳輸
為了很好的支持跨單元數據同步,我們采用了MNS(阿里云消息服務),MNS本身是個分布式的組件,無法滿足消息的順序性。起初為了保證強一致性,我采用消息染色與還原的方式,具體實現見下圖:
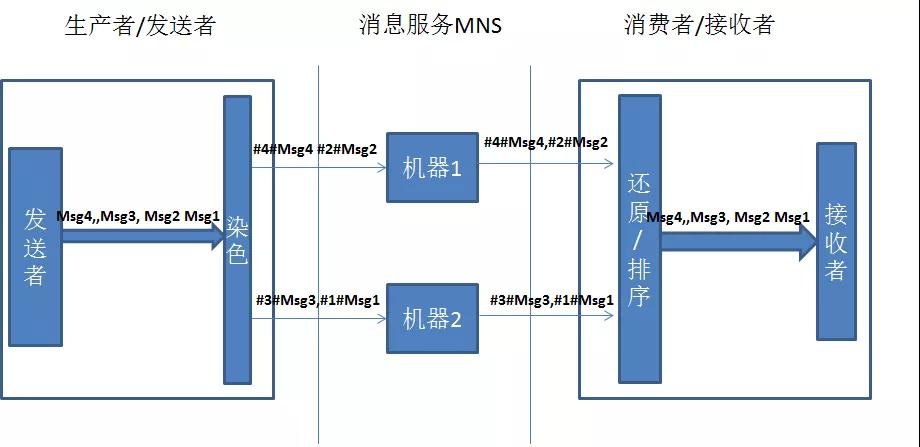
通過實踐我們發現,這種客戶端排序并不可靠,我們的系統不可能無限去等待一個消息的,這里涉及到最終一致性的問題,在第3點中繼續探討。其實對于順序消息,RocketMQ是有順序消息的,但是RocketMQ目前還沒有實現跨單元的能力,而單純的就數據同步而言,我們只要保證最終一致性就可以了,沒有必要為了保證強一致性而犧牲性能。同時MNS消息如果沒有消費成功,消息是不會丟掉的,只有我們去顯示的刪除消息,消息才會丟,所以最終這個消息一定會到來。
最終一致性
既然MNS無法保證強順序,而我們做的是數據同步,只要能夠保證最終一致性就可以了。2012年CAP理論提出者Eric Brewer撰文回顧CAP時也提到,C和A并不是完全互斥,建議大家使用CRDT來保障一致性。CRDT(Conflict-Free Replicated Data Type)是各種基礎數據結構最終一致算法的理論總結,能根據一定的規則自動合并,解決沖突,達到強最終一致的效果。通過查閱相關資料,我們了解到CRDT要求我們在數據同步的時候要滿足交換律、結合律和冪等律。如果操作本身滿足以上三律,merge操作僅需要對update操作進行回放即可,這種形式稱為op-based CRDT,如果操作本身不滿足,而通過附帶額外元信息能夠讓操作滿足以上三律,這種形式稱為state-based CRDT。
通過DRC的拆解,數據庫操作有三種:insert、update、delete,這三種操作不管哪兩種操作都是不能滿足交換律的,會產生沖突,所以我們在并發級別(主鍵)加上額外信息,這里我們采用序號,也就是2中提到的染色的過程,這個過程是保留的。而主鍵之間是并發的,沒有順序而言。當接收消息的時候我們并不保證強順序,采用LWW(Last Write Wins)的方式,也就是說我們執行當前的SQL而放棄前面的SQL,這樣我們就不用考慮交換的問題。同時我們會根據消息的唯一性(實例+單元+數據庫+MD5(SQL))對每個消息做冪等,保證每個SQL都不會重復執行。而對于結合律,我們需要對每個操作單獨分析。
1)insert
insert是不滿足結合律的,可能會有主鍵沖突,我們把insert語句變更insert ignore,而收到insert操作說明之前并不存在這樣一條記錄,或者前面有delete操作。而delete操作可能還沒有到。這時insert ignore操作返回結果是0,但這次的insert數據可能跟已有的記錄內容并不一致,所以這里我們將這個insert操作轉換為update 操作再執行一次。
2)update
update操作天然滿足結合律。但是這里又要考慮一種特殊情況,那就是執行結果為0。這說明此語句之前一定存在一個insert語句,但這個語句我們還沒有收到。這時我們需要利用這條語句中的數據將update語句轉成insert再重新執行一次。
3)delete
delete也是天然滿足結合律的,而無論之前都有什么操作,只要執行就好了。
在insert和update操作里面,都有一個轉換的過程,而這里有個前提,那就是從DRC拿到的變更數據每一條都是全字段的。可能有人會說這里的轉換可以用replace into替換,為什么沒有使用replace into呢,首先由于順序錯亂的情況畢竟是少數,而且我們并不單純復制數據,同時也是在復制操作,而對于DRC來說,replace into操作會被解析為update或insert。這樣無法保證消息唯一性,也無法做到防循環廣播,所以并不推薦。我們看看下面的流程圖也許會更清晰些:

四、容災架構
根據上面的介紹,我們來看下多中心容災架構的形態,這里用了兩級調度來保證中心封閉,同時利用自研的同步組件進行多中心雙向同步。我們還可以制定一些快恢策略,例如快速摘掉一個中心。同時還有一些細節需要考慮,例如在摘掉一個中心的過程中,在摘掉的中心數據還沒有同步到其他中心的過程中,應該禁掉寫操作,防止短時間出現雙寫的情況,由于我們同步的時間都是毫秒級的,所以影響很小。
五、結束語
架構需要不斷的演進,到底哪種更適合你還需要具體來看,上述的多中心架構及實現方式歡迎大家來討論。
我們的數據同步組件hera-dts已在BU內部進行使用,數據同步的邏輯還是比較復雜的,尤其是實現雙向同步,其中涉及到斷點續傳、Failover、防丟數據、防消息重發、雙向同步中防循環復制等非常多的細節問題。我們的同步組件也是經歷了一段時間的優化才達到穩定的版本。