一文看懂人工智能發展的這些年
這幾年隨著AI的浪潮席卷而來,各行各業陸續上演著AI取代人類工作的戲碼,好像凡事只要套上AI再困難的事情都能解決,所以究竟AI到底是什么?今天就讓我用一篇文章帶你快速了解這人類長久以來的夢想技術——AI。
一個有趣的問題和游戲
AI全名Artificial Intelligence,通常翻譯為人工智慧或人工智能,是人類長久以來的夢想技術,早在1950年天才斜杠科學家艾倫圖靈就在他的論文《計算機與智能》中第一次提到一個有趣的問題“機器能思考嗎?”從此開啟了AI這個新領域,也引發了人們對AI的無限想象。
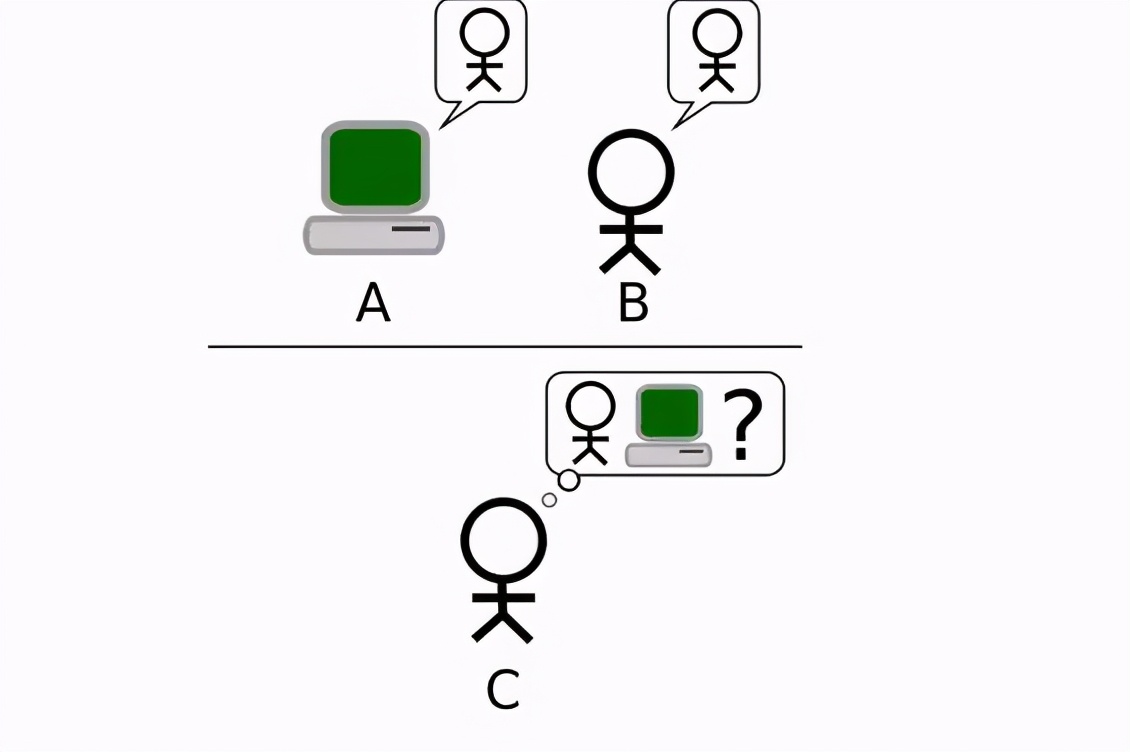
根據圖靈的想法,要判斷一臺機器能不能思考,必須通過一個所謂的模仿游戲,由于這個游戲太過經典而被后人稱為圖靈測試,在這個測試當中由一個發問人C同時對不同房間內的機器A與人類B持續發問,只要C無法分辨AB誰是計算機誰是人類,我們就可以宣稱房間內的機器是一臺能思考的機器。
從窮舉到分類
從那之后人們花了很長一段時間研發,試圖制造出能通過圖靈測試的機器或算法,在1997年,當時最先進的IBM深藍計算機擊敗西洋棋世界冠軍,盡管看似很厲害,殊不知這背后也只是讓計算機窮舉所有可能性,從中挑選最有利的步數去走而已,說穿了就跟GPS導航系統從已知的所有地圖路徑當中選擇最佳路徑沒什么兩樣。
然而面對無限多種可能性的現實世界,這樣的暴力窮舉法顯然無法套用到大多數更為復雜的現實情況,要把AI應用在日常生活當中,我們還是需要尋找更有效率的做法,而人類累積智慧的方式就是一個很好的參考方向。
人類的智慧,來自于經驗,也就是不斷地學習與記取教訓,在一次次的嘗試錯誤當中調整自我對外界的認知,如此一來當下一次遇到類似的狀況我們就能輕易利用過往的經驗來判斷與應對未知的未來,同時,為了大幅減少所需記憶和處理的內容,人們也很擅長把類似的東西分類貼標簽,把大量的信息歸納為少少的幾類,套用同樣的概念我們有沒有可能把經驗也就是歷史資料喂給機器去學習從而自動找出事件特征與結果之間的關聯模型,而變成一個能預測未來數值或者自動分類與決策的程序。
自動分類的方法
關于預測數值一個很直覺的想法就是找出事件特征與結果之間的數學線性關系,舉例來說,假設在某個地段有一間10平米的房子以10萬成交,另一間20平米的房子以20萬成交,根據這樣的信息我們就能合理推斷出成交價與坪數之間大約就是每平米10萬的關系,而當成交信息愈來愈多時,我們也能利用梯度下降之類的技巧找出一條最符合所有資料的回歸線,進而獲得一個用梯度下降數來預測房價的模型,這就是所謂的線性回歸法。
關于自動分類則有許多方法,在此我們列舉幾個有名的算法來感受一下:
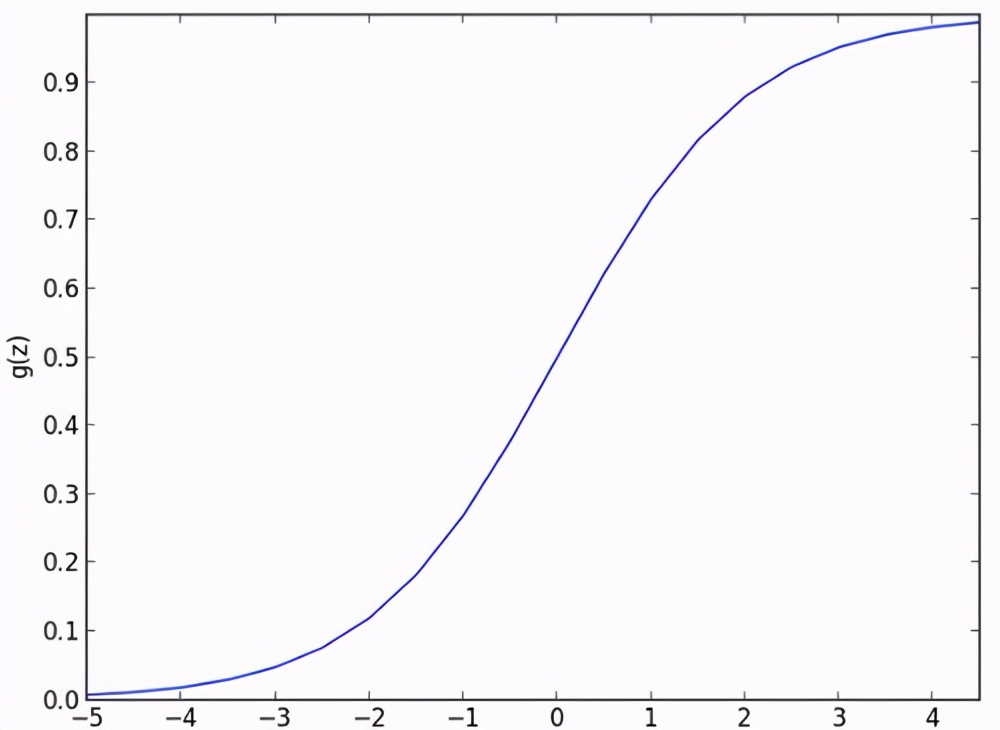
面對非此即彼的分類問題我們也可以把特征與結果之間的關聯投射回歸到一個0與1的邏輯曲線上,0代表其中一類,1代表另外一類,如此就利用類似的做法得到一個把任意數值對應到適當分類的模型,這就是所謂的邏輯回歸法。
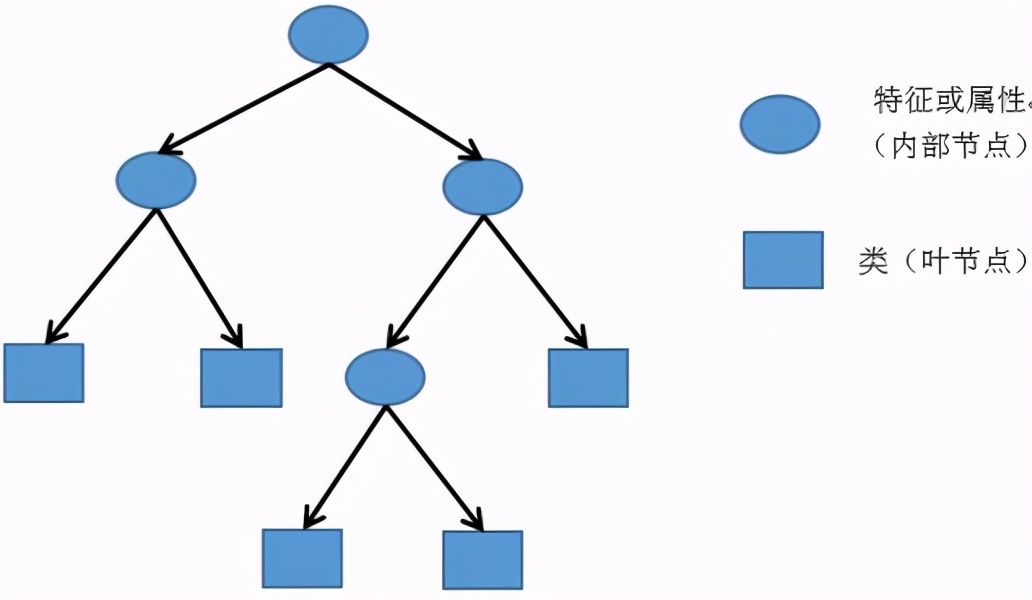
決策樹是利用特征與分類結果之間的關系,由歷史資料來建構出一棵充滿著“如果這樣就那樣”的決策樹,成為一個讓不同的特征落入對應的適當分類的模型。
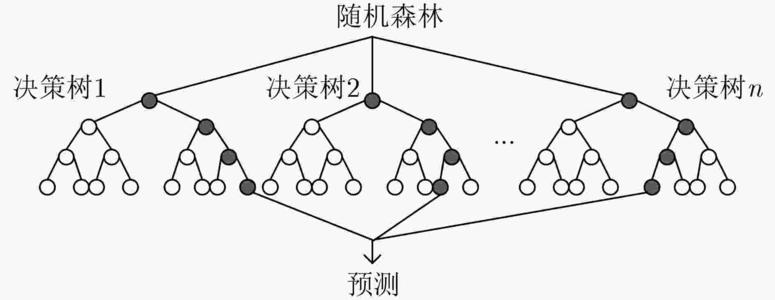
面對同樣的問題為了避免單一特征的重要性被過度放大而造成偏差,如果隨機挑選部分特征來建構多棵決策樹,最后再用投票的方式來決勝負,將會得出比單一決策樹更全面更正確的答案這就是隨機森林法。
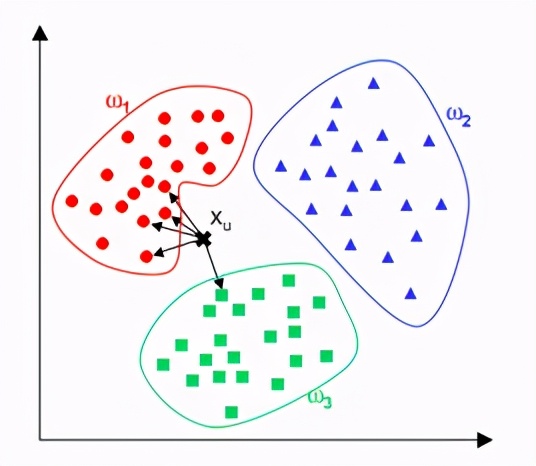
最近鄰居法簡稱KNN,是在現有歷史資料的基礎上對于想預測的新資料直接比對特征最接近的K筆歷史資料看他們分別屬于哪個分類,再以投票來決定新資料的所屬分類。
支持向量機簡稱SVM,試著在不同分類群體之間找出一條分隔線,使邊界距離最近的資料點越遠越好,以此來達到分類的目的。
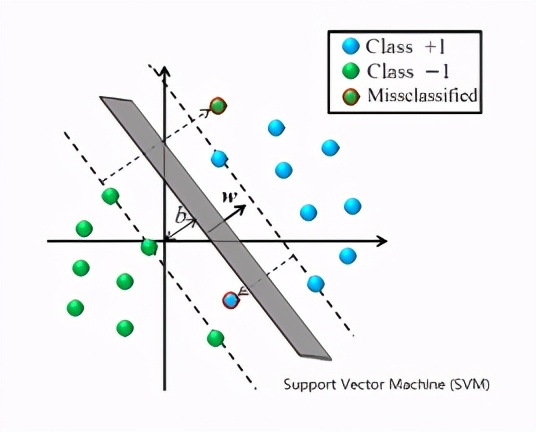
以上都是在歷史資料都有標準答案的情形下,試著找出符合特征與結果之間關聯性的模型,如此一來新資料就能套用相同的模型而得出適當的預測結果,那么如果我們手頭上的資料從來沒被分類過,還有辦法自動將他們分群嗎?有的:
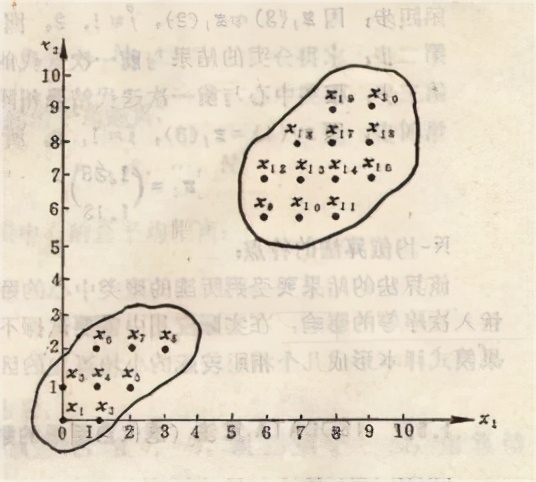
K-平均算法,先從所有資料當中隨機數選擇K個中心點,我們就能把個別資料依照最近的中心點分成K群,將每一群的平均值當成新的K個中心點再分成K群,以此類推最終資料將收斂至K個彼此相近的群體,以上都是在有歷史資料的情形下利用資料來建構模型的算法,那么如果沒有歷史資料呢?
強化學習
強化學習簡稱RL,概念上是在沒有歷史資料的情況下把模型直接丟到使用環境當中,透過一連串的動作來觀察環境狀態同時接受來自環境的獎勵或懲罰反饋來動態調整模型,如此一來在經過訓練之后模型就能自動做出能獲得最多獎勵的動作。
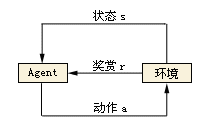
面對這么多琳瑯滿目的機器學習算法我們首先面臨的難題就是該套用哪一種算法,關于算法的挑選通常我們會依照用來訓練的歷史資料有沒有標準答案將算法分為兩大類,監督式學習或者非監督式學習,然后再依能達成的效果細分下去,至于沒有歷史資料的強化學習則獨立于這兩大類自成一格。
此外我們也需要考慮每個算法的特性與前提假設,除此之外,還有許多雜七雜八的因素,比如資料量的大小、模型效能與準確度之間的取舍等等,甚至有人將算法的選擇做成SOP讓人比較有方向可循,即便如此這樣子根據不同類型的問題見招拆招的方式似乎也只適用于這些相對單純的應用場景,難以套用到更高層次更復雜的應用上,難道機器學習就只能這樣了嗎?
AI進階——深度學習
在發展機器學習的同時擅長模仿的人類也把腦筋動到了模仿自己的大腦神經元上,人腦雖然只由簡單的腦神經元組成,卻能透過數百到數千億個神經元之間的相互連結來產生智慧,那么我們能不能用相同的概念讓機器去模擬這種普適性的一招打天下的機制而產生智慧呢?
這個想法開啟了類神經網絡這個領域進而演變為后來的深度學習,一個大腦神經元有許多樹突接收來自其他神經元的動作電位,這些外來動作電位在細胞內進行匯整,只要電位超過一個閥值就會觸發連鎖反應,將這個神經元的動作電位訊息透過軸突傳遞給后續的神經元。
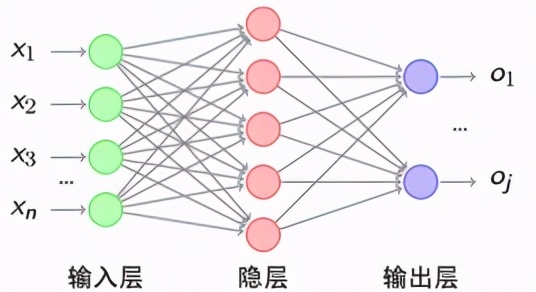
同理我們可以把大腦神經元的機制以數位邏輯的方式來模擬,我們稱之為感知器,其中包含m筆輸入*一個偏置,經過權重相乘并加總之后再通過一個激活函數來模擬大腦神經元的電位閾值機制,最終輸出這個節點被激活的程度,傳遞至下一層的感知器。
由于現實中要解決的難題大多不會有簡單的線性解,我們通常會選用非線性函數的激活函數,象是介于0與1之間的s形函數,介于-1與1之間的雙曲正切函數,最常被使用的線性整流函數或者其他變形。
而一旦我們把很多個感知器分層相互連接起來就形成一個深度學習的模型架構,要訓練這個模型就把資料一筆一筆喂進去先進行正向傳播,將得出的輸出結果與標準答案帶入損失函數,算出兩者之間的差異再以梯度下降之類的最佳化函數進行反向傳播,以減少差異為目標來調整每一個感知器里的權重,只要資料量夠多模型輸出與標準答案之間的差異就會在資料一筆一筆正向反向流入模型的自我修正當中逐漸收斂減小,一旦經由模型得出的答案與標準答案的差異小到某個可以接受的程度,就表示這個模型是訓練好的可用的模型。
這樣的概念看似簡單但要實現出來則需要大量的資料大量的運算能力以及夠簡單好用的軟件,也因此在2012年之后當這三個條件都滿足了深度學習才終于開花結果開始有了爆炸性的成長。
實際問題的解決
在計算機視覺領域我們可以使用卷積神經網絡CNN,先用小范圍的濾鏡來取得影像的邊緣、形狀等等特征,再把這些富有意義的特征連接到前面提到的深度學習模型,如此就能有效識別圖片或影像中的物體,透過這樣的方式計算機在影像識別的正確率上已經超越人類并持續進步當中。
在模仿影像或藝術風格方面則可以使用生成對抗網絡GAN,透過兩個深度學習模型相互抗衡由立志要成為模仿大師的生成模型產生假資料交由判別模型來判斷資料真假,一旦生成模型產生出來的假資料讓判別模型分不清真假就成功了,坊間一些變臉應用的app或是AI生成的畫作都是GAN的相關應用。
針對聲音或文字等等自然語言處理NLP,這類有順序性資料的處理傳統上可以使用遞歸神經網絡RNN把每次訓練的模型狀態傳遞至下一次訓練,以達到有順序性的短期記憶的功效,進階版本的長短期記憶神經網絡LSTM則用于改善RNN的長期記憶遞減效應,針對類似的問題后來有人提出另一套更有效率的解法稱為Transformer,概念上是使用注意力的機制讓模型直接針對重點部分進行處理,這樣的機制不只適用于自然語言處理,套用在計算機視覺領域上也有不錯的成果。
2020年擁有1750億模型參數的超巨大模型GPT-3已經能做到自動生成文章與程序碼或回答問題質量甚至還不輸人類,未來隨著模型參數個數再持續指數型成長這類模型的實際應用成效更是令人期待,而除了前面說的計算機視覺與自然語言處理這兩大領域之外,深度學習在各個領域也都有很驚人的成果。
2017年在不可能暴力窮舉的圍棋領域中結合深度學習與增強學習的AlphaGo以3:0擊敗世界第一圍棋士柯潔震驚全世界,等同宣告AI已經能透過快速自我學習在特定領域超越人類數千年以來的智慧累積,2020年AlphaGo的研發團隊DeepMind再度運用深度學習破解了困擾著生物學50年的蛋白質分子折疊問題
這將更實際地幫助人類理解疾病機制促進新藥開發幫助農業生產進而運用蛋白質來改善地球生態環境,更貼近生活的自動駕駛的發展更是不在話下,當前的自動駕駛技術隨著累積里程數持續增加而趨于成熟,肇事率也早已遠低于人類,同時AI在醫學領域某些科別的診斷正確率也已經達到優于人類的水平,至于無人商店與中國天網則早已不是那么新奇的話題了。
結語
這時,再回頭來看1950年圖靈的問題,機器能思考嗎?我們可能還是無法給出一個明確的答案,然而,當下的人類卻已經比當年擁有更多的技術累積成果更接近這個夢想并持續前進當中,當前的AI技術就像一個學習成長中的小孩,能看、能聽、能說,以及能針對特定問題做出精準、甚至跳脫框架、超越人類過往認知能力的判斷,然而一旦遇到復雜的哲學、情感、倫理道德等議題就還遠遠無法勝任。
總體而言人與機器各有所長,人類擅長思考與創新然而體力有限,也偶爾會犯點錯誤,機器則擅長記憶與運算,能針對特定問題給出穩定且高質量的答案而且24小時全年無休,因此在這波AI浪潮下理想策略應該是人與機器充分合作各取所長,人們可以把一些比較低階、重復性高、瑣碎、無趣的工作逐步外包給機器,與此同時釋出的人力將可以投入更多探索、研究、富有創造性、也較有趣的工作當中,如此一來人們將更有時間與精力去實現夢想去思考人生的意義,也更能專注在解決重要的問題上進而提升整體人類的層次。