轉崗大數據了,先用數據看看行情
數據來源:以某直聘平臺為數據來源,以“大數據”為關鍵詞,設置搜索條件為:杭州市規模在10000人以上的上市公司。由于平臺限制僅可顯示10頁,每頁30條招聘信息,除去個別無效記錄,最終獲取有效數據大概在280條招聘記錄。當然,由于這里僅獲取到了10頁數據而并非海量數據,所以樣本排序先后將對數據真實分布有一定影響。
分析目標:為了從多角度描述大數據崗位就業現狀,擬從以下幾個方面著手分析:
- 大數據崗位畫像,包括崗位類型分布,公司分布、區域分布、招聘學歷要求、工作經驗要求、薪資分布
- 主要技術棧,主要是利用招聘崗位標簽信息,分析大數據崗位招聘技能需求,并對頭部企業進行細分
- 影響薪資因素,包括分析各區域、各公司、各崗位類型以及各技能對應的薪資分布情況
- 薪酬福利情況,簡單分析大數據崗位整體福利詞云
注:因樣本數據隨機性以及分析結果主觀性,本文所屬觀點結論僅供參考!
01 數據獲取及清洗
Garbage in,garbage out!
選取某直聘平臺,按照目標崗位設置搜索條件,可以直接訪問10頁數據,以此為目標,分別爬取各招聘記錄的如下信息,且各字段信息直接從查詢首頁即可完整獲取,無需分別訪問各崗位詳情頁:
- 崗位title
- 地理區域
- 薪酬范圍
- 經驗要求
- 學歷要求
- 招聘公司
- 崗位標簽信息
- 崗位福利描述
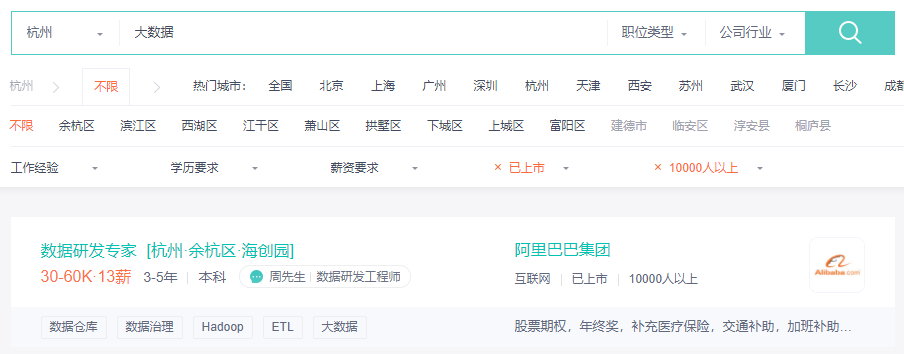
招聘信息搜索結果
這里直接爬取的字段相對較為整齊,多數字段均無需清洗處理,但為了后續分析需要,這里做以下4步處理:
- 過濾實習生招聘記錄,即通過薪酬范圍字段按天計算的記錄,抓取記錄中共2條;
- 將招聘公司統一為集團公司名稱,主要是阿里巴巴包括“阿里巴巴集團”、“阿里云”以及“阿里健康”等不同描述;網易包括“網易游戲”和“網易杭州”等子公司名稱;海康威視包括“杭州海康威視”和“海康威視武漢研發中心”兩個別稱。處理過程中統一將這些同一公司的不同名稱描述進行統一;
- 薪酬提取,不失一般性,將給定薪酬范圍上下限間的1/3分位數作為崗位薪酬,例如標定20-35K的薪酬范圍,最終按25K參與分析,實現薪酬字段的標簽向數值轉換;
- 崗位類型劃分:主要依據崗位title關鍵詞情況,區分開發(關鍵詞:開發、研發)、算法(關鍵詞:算法、挖掘、分析)、架構師(關鍵詞:架構)、產品(關鍵詞:產品)以及其他,共5種崗位類型。這一定程度上也涵蓋了大數據相關崗位的不同類別。
處理后的數據樣例如下:

02 大數據崗位畫像
畫像的本質的在于降維描述!
分別從6個維度描述杭州人員規模在萬人以上的上市公司招聘大數據相關崗位的招聘現狀,其中薪資采用直方圖刻畫,區域和學歷信息采用餅圖描述,而崗位類型、招聘公司TOP5以及經驗要求則采用橫向直方圖描述。結果如下所示:
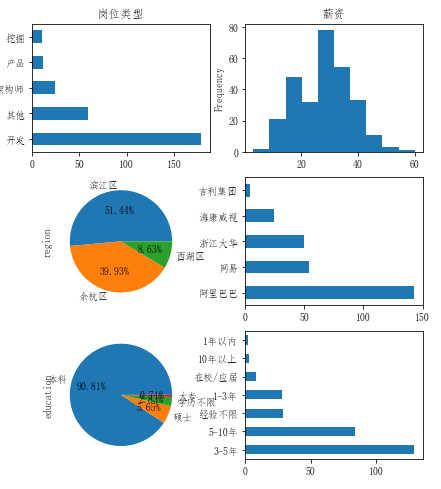
從中可以得出以下基本結論:
- 大數據崗位中,絕大部分崗位仍然是研發崗位,常規的研發崗位包括測試、前后端、數據倉庫管理等等;而算法、產品和架構則更傾向于開發崗位基礎之上的屬性,各崗位之間形成完整的數據采集、存儲、治理直至創造價值的完整閉環;
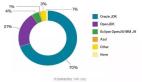
- 杭州市招聘大數據崗位的萬人以上上市公司中,主要集中在濱江區(以網易、海康威視、浙江大華和吉利集團為代表)、西湖區和余杭區(均以阿里巴巴為代表);
- 阿里巴巴以接近50%的比例毫無懸念的成為大數據崗位招聘龍頭企業,這既與其本身的人員規模體量直接相關,也與其業務生態圈有密切聯系,當然還可能是由于其運營得力,使得崗位搜索排名較為靠前;
- 大數據崗位的就業門檻要求并不高,絕大部分仍然是只要本科學歷即可;但對工作經驗往往有一定要求,尤其是要求具有3-5年以及5-10年工作經驗的大數據崗位居多;
- 薪資情況,整體位于20-40K之間,頂薪接近60K,也有10K以下低薪崗位;平均值28.3K,中位數27K。后續將對影響薪資因素重點分析。
03 崗位技術棧
大數據技術的核心是存儲和計算!
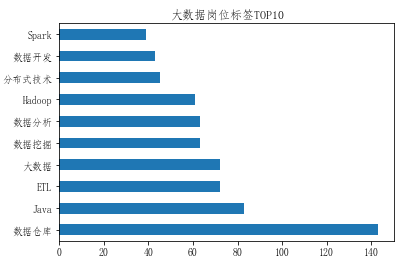
為了了解大數據崗位從業技能要求,對崗位招聘的標簽信息進行統計分析,得到全樣本崗位標簽TOP10如下,易見以下結論:大數據50%以上崗位都要求掌握數倉技能(數據存儲);大數據的核心語言是Java(當然這與阿里主用Java有一定關系,而抓取樣本中阿里的招聘記錄占大多數);大數據相關的核心環節是ETL(抽取Extract、轉換Transform、加載Load);大數據的核心技術棧仍然離不開Hadoop生態圈。
具體到幾個頭部公司,分別對其招聘崗位技能標簽進行分析,結果如下:
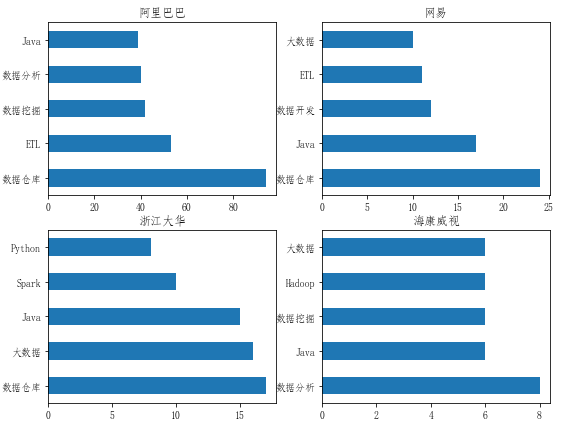
對比分析各公司大數據崗位的TOP5技能標簽,一定程度上可以管窺各企業的大數據技術棧信息,例如阿里巴巴和海康威視更注重數據分析與挖掘;浙江大華除了Java之外還較多的運用Python以及Spark;而無一例外的,Java都入選了各大公司的技術棧。
04 打工人的命根——薪資
不以薪資衡量崗位價值就是不講武德。
接下來分析打工人最為關心的因素:大數據崗位薪資情況。分別從公司、崗位類型、學歷、工作經驗以及技能標簽等5個維度,分別描繪崗位薪酬分布情況,結果如下圖所示。
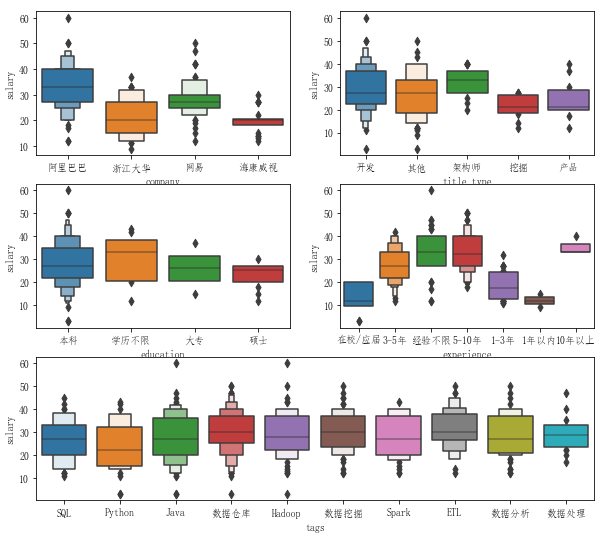
透過圖表,值得關注的幾個細節是:
- 公司層面,阿里和網易整體薪酬更高,不僅在于更具吸引力的平均薪酬,更在于具有更高的薪資天花板;
- 崗位屬性方面,研發崗和架構師則略勝一籌,近年火熱的算法崗(挖掘)則反而不夠突出,這可能與數據量不足有一定關系;
- 學歷層面,不同學歷間薪酬差距不大,但這并不等價于高學歷無用論,只能歸因于工作經驗的重要性;因為通過工作經驗來看,明顯工作年限要求更長的崗位具有更高的薪酬區間(經驗不限例外,因為這里的經驗不限通常并不意味著真的經驗不限,更不等價于零經驗)
- 技能標簽方面,整體來看差距不大,畢竟大廠的大數據崗位通常不會僅要求掌握相對單一或孤立的技術棧,而更多的是綜合能力和技術體系。
05 崗位福利
最后,以一張崗位福利詞云結束本篇分析,主要是依托jieba分詞和wordcloud庫,對崗位福利描述繪制詞云,得到如下結果:

基本都是互聯網公司的常規福利,只能說除了股票期權真的是毫無吸引力……