GitHub超級火!任意爬取,超全開源爬蟲工具箱

最近國內一位開發者在 GitHub 上開源了個集眾多數據源于一身的爬蟲工具箱——InfoSpider,一不小心就火了!!!
現在一般網站都有反爬蟲機制,對于愛爬蟲的朋友來說,想爬蟲些數據,做下數據分析。是越來越難了。不過最近我們,發現一個超寶藏的爬蟲工具箱。
這個爬蟲工具箱有多火呢?
開源沒幾天就登上GitHub周榜第四,標星1.3K,累計分支 172 個。同時作者已經開源了所有的項目代碼及使用文檔,并且在B站上還有使用視頻講解。
項目代碼:
https://github.com/kangvcar/InfoSpider
項目使用文檔:
https://infospider.vercel.app
項目視頻演示:
https://www.bilibili.com/video/BV14f4y1R7oF/
在這樣一個信息爆炸的時代,每個人都有很多個賬號,賬號一多就會出現這么一個情況:個人數據分散在各種各樣的公司之間,就會形成數據孤島,多維數據無法融合,這個項目可以幫你將多維數據進行融合并對個人數據進行分析,這樣你就可以更直觀、深入了解自己的信息。
InfoSpider 是一個集眾多數據源于一身的爬蟲工具箱,旨在安全快捷的幫助用戶拿回自己的數據,工具代碼開源,流程透明,并提供數據分析功能,基于用戶數據生成圖表文件。
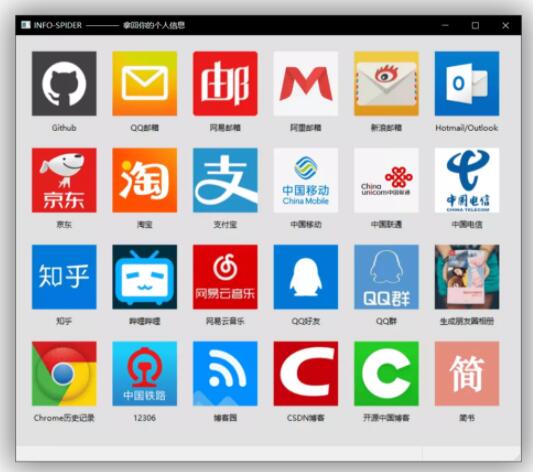
目前支持數據源包括GitHub、QQ郵箱、網易郵箱、阿里郵箱、新浪郵箱、Hotmail郵箱、Outlook郵箱、京東、淘寶、支付寶、中國移動、中國聯通、中國電信、知乎、嗶哩嗶哩、網易云音樂、QQ好友、QQ群、生成朋友圈相冊、瀏覽器瀏覽歷史、12306、博客園、CSDN博客、開源中國博客、簡書。
根據創建者介紹,InfoSpider 具有以下特性:
- 安全可靠:本項目為開源項目,代碼簡潔,所有源碼可見,本地運行,安全可靠。
- 使用簡單:提供 GUI 界面,只需點擊所需獲取的數據源并根據提示操作即可。
- 結構清晰:本項目的所有數據源相互獨立,可移植性高,所有爬蟲腳本在項目的 Spiders 文件下。
- 數據源豐富:本項目目前支持多達24+個數據源,持續更新。
- 數據格式統一:爬取的所有數據都將存儲為json格式,方便后期數據分析。
- 個人數據豐富:本項目將盡可能多地為你爬取個人數據,后期數據處理可根據需要刪減。
- 數據分析:本項目提供個人數據的可視化分析,目前僅部分支持。
InfoSpider使用起來也非常簡單,你只需要安裝python3和Chrome瀏覽器,運行 python3 main.py,在打開的窗口點擊數據源按鈕, 根據提示選擇數據保存路徑,接著輸入賬號密碼,就會自動爬取數據,根據下載的目錄就可以查看爬下來的數據。
依賴安裝
- 安裝python3和Chrome瀏覽器
- 安裝與Chrome瀏覽器相同版本的驅動
- 安裝依賴庫 ./install_deps.sh (Windows下只需pip install -r requirements.txt)
工具運行
- 進入 tools 目錄
- 運行 python3 main.py
- 在打開的窗口點擊數據源按鈕, 根據提示選擇數據保存路徑
- 彈出的瀏覽器輸入用戶密碼后會自動開始爬取數據, 爬取完成瀏覽器會自動關閉
在對應的目錄下可以查看下載下來的數據(xxx.json), 數據分析圖表(xxx.html)
作者認為該項目的最大潛力在于能把多維數據進行融合并對個人數據進行分析,是個人數據效益最大化。
當然如果你想自己去練習和學習爬蟲,作者也開源了所有的爬取代碼,非常適合實戰。

舉個例子,比如爬取taobao的:
- import json
- import random
- import time
- import sys
- import os
- import requests
- import numpy as np
- import math
- from lxml import etree
- from pyquery import PyQuery as pq
- from selenium import webdriver
- from selenium.webdriver import ChromeOptions
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support import expected_conditions as EC
- from selenium.webdriver.support.wait import WebDriverWait
- from selenium.webdriver import ChromeOptions, ActionChains
- from tkinter.filedialog import askdirectory
- from tqdm import trange
- def ease_out_quad(x):
- return 1 - (1 - x) * (1 - x)
- def ease_out_quart(x):
- return 1 - pow(1 - x, 4)
- def ease_out_expo(x):
- if x == 1:
- return 1
- else:
- return 1 - pow(2, -10 * x)
- def get_tracks(distance, seconds, ease_func):
- tracks = [0]
- offsets = [0]
- for t in np.arange(0.0, seconds, 0.1):
- ease = globals()[ease_func]
- offset = round(ease(t / seconds) * distance)
- tracks.append(offset - offsets[-1])
- offsets.append(offset)
- return offsets, tracks
- def drag_and_drop(browser, offset=26.5):
- knob = browser.find_element_by_id('nc_1_n1z')
- offsets, tracks = get_tracks(offset, 12, 'ease_out_expo')
- ActionChains(browser).click_and_hold(knob).perform()
- for x in tracks:
- ActionChains(browser).move_by_offset(x, 0).perform()
- ActionChains(browser).pause(0.5).release().perform()
- def gen_session(cookie):
- session = requests.session()
- cookie_dict = {}
- list = cookie.split(';')
- for i in list:
- try:
- cookie_dict[i.split('=')[0]] = i.split('=')[1]
- except IndexError:
- cookie_dict[''] = i
- requests.utils.add_dict_to_cookiejar(session.cookies, cookie_dict)
- return session
- class TaobaoSpider(object):
- def __init__(self, cookies_list):
- self.path = askdirectory(title='選擇信息保存文件夾')
- if str(self.path) == "":
- sys.exit(1)
- self.headers = {
- 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
- }
- option = ChromeOptions()
- option.add_experimental_option('excludeSwitches', ['enable-automation'])
- option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加載圖片,加快訪問速度
- option.add_argument('--headless')
- self.driver = webdriver.Chrome(options=option)
- self.driver.get('https://i.taobao.com/my_taobao.htm')
- for i in cookies_list:
- self.driver.add_cookie(cookie_dict=i)
- self.driver.get('https://i.taobao.com/my_taobao.htm')
- self.wait = WebDriverWait(self.driver, 20) # 超時時長為10s
- # 模擬向下滑動瀏覽
- def swipe_down(self, second):
- for i in range(int(second / 0.1)):
- # 根據i的值,模擬上下滑動
- if (i % 2 == 0):
- js = "var q=document.documentElement.scrollTop=" + str(300 + 400 * i)
- else:
- js = "var q=document.documentElement.scrollTop=" + str(200 * i)
- self.driver.execute_script(js)
- time.sleep(0.1)
- js = "var q=document.documentElement.scrollTop=100000"
- self.driver.execute_script(js)
- time.sleep(0.1)
- # 爬取淘寶 我已買到的寶貝商品數據, pn 定義爬取多少頁數據
- def crawl_good_buy_data(self, pn=3):
- # 對我已買到的寶貝商品數據進行爬蟲
- self.driver.get("https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm")
- # 遍歷所有頁數
- for page in trange(1, pn):
- data_list = []
- # 等待該頁面全部已買到的寶貝商品數據加載完畢
- good_total = self.wait.until(
- EC.presence_of_element_located((By.CSS_SELECTOR, '#tp-bought-root > div.js-order-container')))
- # 獲取本頁面源代碼
- html = self.driver.page_source
- # pq模塊解析網頁源代碼
- doc = pq(html)
- # # 存儲該頁已經買到的寶貝數據
- good_items = doc('#tp-bought-root .js-order-container').items()
- # 遍歷該頁的所有寶貝
- for item in good_items:
- # 商品購買時間、訂單號
- good_time_and_id = item.find('.bought-wrapper-mod__head-info-cell___29cDO').text().replace('\n', "").replace('\r', "")
- # 商家名稱
- # good_merchant = item.find('.seller-mod__container___1w0Cx').text().replace('\n', "").replace('\r', "")
- good_merchant = item.find('.bought-wrapper-mod__seller-container___3dAK3').text().replace('\n', "").replace('\r', "")
- # 商品名稱
- # good_name = item.find('.sol-mod__no-br___1PwLO').text().replace('\n', "").replace('\r', "")
- good_name = item.find('.sol-mod__no-br___3Ev-2').text().replace('\n', "").replace('\r', "")
- # 商品價格
- good_price = item.find('.price-mod__price___cYafX').text().replace('\n', "").replace('\r', "")
- # 只列出商品購買時間、訂單號、商家名稱、商品名稱
- # 其余的請自己實踐獲取
- data_list.append(good_time_and_id)
- data_list.append(good_merchant)
- data_list.append(good_name)
- data_list.append(good_price)
- #print(good_time_and_id, good_merchant, good_name)
- #file_path = os.path.join(os.path.dirname(__file__) + '/user_orders.json')
- # file_path = "../Spiders/taobao/user_orders.json"
- json_str = json.dumps(data_list)
- with open(self.path + os.sep + 'user_orders.json', 'a') as f:
- f.write(json_str)
- # print('\n\n')
- # 大部分人被檢測為機器人就是因為進一步模擬人工操作
- # 模擬人工向下瀏覽商品,即進行模擬下滑操作,防止被識別出是機器人
- # 隨機滑動延時時間
- swipe_time = random.randint(1, 3)
- self.swipe_down(swipe_time)
- # 等待下一頁按鈕 出現
- good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.pagination-next')))
- good_total.click()
- time.sleep(2)
- # while 1:
- # time.sleep(0.2)
- # try:
- # good_total = self.driver.find_element_by_xpath('//li[@title="下一頁"]')
- # break
- # except:
- # continue
- # # 點擊下一頁按鈕
- # while 1:
- # time.sleep(2)
- # try:
- # good_total.click()
- # break
- # except Exception:
- # pass
- # 收藏寶貝 傳入爬幾頁 默認三頁 https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow=60
- def get_choucang_item(self, page=3):
- url = 'https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow={}'
- pn = 0
- json_list = []
- for i in trange(page):
- self.driver.get(url.format(pn))
- pn += 30
- html_str = self.driver.page_source
- if html_str == '':
- break
- if '登錄' in html_str:
- raise Exception('登錄')
- obj_list = etree.HTML(html_str).xpath('//li')
- for obj in obj_list:
- item = {}
- item['title'] = ''.join([i.strip() for i in obj.xpath('./div[@class="img-item-title"]//text()')])
- item['url'] = ''.join([i.strip() for i in obj.xpath('./div[@class="img-item-title"]/a/@href')])
- item['price'] = ''.join([i.strip() for i in obj.xpath('./div[@class="price-container"]//text()')])
- if item['price'] == '':
- item['price'] = '失效'
- json_list.append(item)
- # file_path = os.path.join(os.path.dirname(__file__) + '/shoucang_item.json')
- json_str = json.dumps(json_list)
- with open(self.path + os.sep + 'shoucang_item.json', 'w') as f:
- f.write(json_str)
- # 瀏覽足跡 傳入爬幾頁 默認三頁 https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow=60
- def get_footmark_item(self, page=3):
- url = 'https://www.taobao.com/markets/footmark/tbfoot'
- self.driver.get(url)
- pn = 0
- item_num = 0
- json_list = []
- for i in trange(page):
- html_str = self.driver.page_source
- obj_list = etree.HTML(html_str).xpath('//div[@class="item-list J_redsList"]/div')[item_num:]
- for obj in obj_list:
- item_num += 1
- item = {}
- item['date'] = ''.join([i.strip() for i in obj.xpath('./@data-date')])
- item['url'] = ''.join([i.strip() for i in obj.xpath('./a/@href')])
- item['name'] = ''.join([i.strip() for i in obj.xpath('.//div[@class="title"]//text()')])
- item['price'] = ''.join([i.strip() for i in obj.xpath('.//div[@class="price-box"]//text()')])
- json_list.append(item)
- self.driver.execute_script('window.scrollTo(0,1000000)')
- # file_path = os.path.join(os.path.dirname(__file__) + '/footmark_item.json')
- json_str = json.dumps(json_list)
- with open(self.path + os.sep + 'footmark_item.json', 'w') as f:
- f.write(json_str)
- # 地址
- def get_addr(self):
- url = 'https://member1.taobao.com/member/fresh/deliver_address.htm'
- self.driver.get(url)
- html_str = self.driver.page_source
- obj_list = etree.HTML(html_str).xpath('//tbody[@class="next-table-body"]/tr')
- data_list = []
- for obj in obj_list:
- item = {}
- item['name'] = obj.xpath('.//td[1]//text()')
- item['area'] = obj.xpath('.//td[2]//text()')
- item['detail_area'] = obj.xpath('.//td[3]//text()')
- item['youbian'] = obj.xpath('.//td[4]//text()')
- item['mobile'] = obj.xpath('.//td[5]//text()')
- data_list.append(item)
- # file_path = os.path.join(os.path.dirname(__file__) + '/addr.json')
- json_str = json.dumps(data_list)
- with open(self.path + os.sep + 'address.json', 'w') as f:
- f.write(json_str)
- if __name__ == '__main__':
- # pass
- cookie_list = json.loads(open('taobao_cookies.json', 'r').read())
- t = TaobaoSpider(cookie_list)
- t.get_orders()
- # t.crawl_good_buy_data()
- # t.get_addr()
- # t.get_choucang_item()
- # t.get_footmark_item()
這么優秀的倉庫,大家多多給倉庫創建者 star 支持呀!