提高代碼逼格的利器:宏定義-從入門到放棄
- 一、前言
- 二、預(yù)處理器的操作
- 三、宏擴(kuò)展
- 四、符號:# 與 ##
- 五、可變參數(shù)的處理
- 六、奇思妙想的宏
- 七、總結(jié)
一、前言
一直以來,我都有這樣一種感覺:當(dāng)我學(xué)習(xí)一個新領(lǐng)域的知識時,如果其中的某個知識點(diǎn)在剛開始接觸時,我感覺比較難懂、不好理解,那么以后不論我花多長時間去研究這個知識點(diǎn),心里會一直認(rèn)為該知識點(diǎn)比較難,也就是說第一印象特別的重要。
就比如 C 語言中的宏定義,好像跟我犯沖一樣,我一直覺得宏定義是 C 語言中最難的部分,就好比有有些小伙伴一直覺得指針是 C 語言中最難的部分一樣。
宏的本質(zhì)就是代碼生成器,在預(yù)處理器的支持下實現(xiàn)代碼的動態(tài)生成,具體的操作通過條件編譯和宏擴(kuò)展來實現(xiàn)。我們先在心中建立這么一個基本的概念,然后通過實際的描述和代碼來深入的體會:如何駕馭宏定義。
所以,今天我們就來把宏定義所有的知識點(diǎn)進(jìn)行匯總、深挖,希望經(jīng)過這篇文章,我能夠擺脫心理的這個魔障。看完這篇總結(jié)文章后,我相信你也一定能夠?qū)甓x有一個總體、全局的把握。
二、預(yù)處理器的操作
1. 宏的生效環(huán)節(jié):預(yù)處理
一個 C 程序在編譯的時候,從源文件開始到最后生成二進(jìn)制可執(zhí)行文件,一共經(jīng)歷 4 個階段:
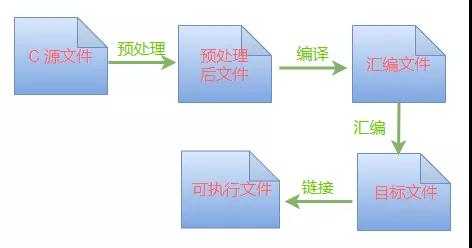
我們今天討論的內(nèi)容就是在第一個環(huán)節(jié):預(yù)處理,由預(yù)處理器來完成這個階段的工作,包括下面這 4 項工作:
- 文件引入(#include);
- 條件編譯(#if..#elif..#endif);
- 宏擴(kuò)展(macro expansions);
- 行控制(line control)。
2. 條件編譯
一般情況下,C 語言文件中的每一行代碼都是要被編譯的,但是有時候出于對程序代碼優(yōu)化的考慮,希望只對其中的一部分代碼進(jìn)行編譯,此時就需要在程序中加上條件,讓編譯器只對滿足條件的代碼進(jìn)行編譯,將不滿足條件的代碼舍棄,這就是條件編譯。
簡單的說:就是預(yù)處理器根據(jù)我們設(shè)置的條件,對代碼進(jìn)行動態(tài)的處理,把有效的代碼輸出到一個中間文件,然后送給編譯器進(jìn)行編譯。
條件編譯基本上在所有的項目代碼中都被使用到,例如:當(dāng)你需要考慮下面的幾種情況時,就一定會使用條件編譯:
需要把程序編譯成不同平臺下的可執(zhí)行程序;
同一套代碼需要運(yùn)行在同一平臺上的不同功能產(chǎn)品上;
在程序中存在著一些測試目的的代碼,不想污染產(chǎn)品級的代碼,需要屏蔽掉。
這里舉 3 個例子,在代碼中經(jīng)常看到的關(guān)于條件編譯:
示例1:用來區(qū)分 C 和 C++ 代碼
- #ifdef __cplusplus
- extern "C" {
- #endif
- void hello();
- #ifdef __cplusplus
- }
- #endif
這樣的代碼幾乎在每個開源庫中都可能見到,主要的目的就是 C 和 C++ 混合編程,具體來說就是:
如果使用 gcc 來編譯,那么宏 __cplusplus 將不存在,其中的 extern "C" 將會被忽略;
如果使用 g++ 來編譯,那么宏 __cplusplus 就存在,其中的 extern "C" 就發(fā)生作用,編譯出來的函數(shù)名 hello 就不會被 g++ 編譯器改寫,因此就可以被 C 代碼來調(diào)用;
示例2:用來區(qū)分不同的平臺
- #if defined(linux) || defined(__linux) || defined(__linux__)
- sleep(1000 * 1000); // 調(diào)用 Linux 平臺下的庫函數(shù)
- #elif defined(WIN32) || defined(_WIN32)
- Sleep(1000 * 1000); // 調(diào)用 Windows 平臺下的庫函數(shù)(第一個字母是大寫)
- #endif
那么,這些 linux, __linux, __linux__, WIN32, _WIN32 是從哪里來的呢?我們可以認(rèn)為是編譯目標(biāo)平臺(操作系統(tǒng))為我們預(yù)先準(zhǔn)備好的。
示例3:在編寫 Windows 平臺下的動態(tài)庫時,聲明導(dǎo)出和導(dǎo)入函數(shù)
- #if defined(linux) || defined(__linux) || defined(__linux__)
- #define LIBA_API
- #else
- #ifdef LIBA_STATIC
- #define LIBA_API
- #else
- #ifdef LIBA_API_EXPORTS
- #define LIBA_API __declspec(dllexport)
- #else
- #define LIBA_API __declspec(dllimport)
- #endif
- #endif
- #endif
- // 函數(shù)聲明
- LIBA_API void hello();
這段代碼是直接從我之前在 B 站錄制的一個小視頻里的示例拿過來的,當(dāng)時主要是演示如何如何在 Linux 平臺下使用 make 和 cmake 構(gòu)建工具來編譯,后來又小伙伴讓我在 Windows 平臺下也用 make 和 cmake 來構(gòu)建,所以就寫了上面這段宏定義。
- 在使用 MSVC 編譯動態(tài)庫時,需要在編譯選項(Makefle 或者 CMakeLists.txt)中定義宏 LIBA_API_EXPORTS,那么導(dǎo)出函數(shù) hello 的最前面的宏 LIBA_API 就會被替換成:__declspec(dllexport),表示導(dǎo)出操作;
- 在編譯應(yīng)用程序的時候,使用動態(tài)庫,需要 include 動態(tài)庫的頭文件,此時在編譯選項中不需要定義宏 LIBA_API_EXPORTS,那么 hello 函數(shù)最前面的 LIBA_API 就會被替換成 __declspec(dllimport),表示導(dǎo)入操作;
- 補(bǔ)充一點(diǎn):如果使用靜態(tài)庫,編譯選項中不需要任何宏定義,那么宏 LIBA_API 就為空。
3. 平臺預(yù)定義的宏
上面已經(jīng)看到了,目標(biāo)平臺會為我們預(yù)先定義好一些宏,方便我們在程序中使用。除了上面的操作系統(tǒng)相關(guān)宏,還有另一類宏定義,在日志系統(tǒng)中被廣泛的使用:
- FILE:當(dāng)前源代碼文件名;
- LINE:當(dāng)前源代碼的行號;
- FUNCTION:當(dāng)前執(zhí)行的函數(shù)名;
- DATE:編譯日期;
- TIME:編譯時間;
例如:
- printf("file name: %s, function name = %s, current line:%d \n", __FILE__, __FUNCTION__, __LINE__);
三、宏擴(kuò)展
所謂的宏擴(kuò)展就是代碼替換,這部分內(nèi)容也是我想表達(dá)的主要內(nèi)容。宏擴(kuò)展最大的好處有如下幾點(diǎn):
- 減少重復(fù)的代碼;
- 完成一些通過 C 語法無法實現(xiàn)的功能(字符串拼接);
- 動態(tài)定義數(shù)據(jù)類型,實現(xiàn)類似 C++ 中模板的功能;
- 程序更容易理解、修改(例如:數(shù)字、字符串常亮);
我們在寫代碼的時候,所有使用宏名稱的地方,都可以理解為一個占位符。在編譯程序的預(yù)處理環(huán)節(jié),這些宏名將會被替換成宏定義中的那些代碼段,注意:僅僅是單純的文本替換。
1. 最常見的宏
為了方便后面的描述,先來看幾個常見的宏定義:
(1) 數(shù)據(jù)類型的定義
- #ifndef BOOL
- typedef char BOOL;
- #endif
- #ifndef TRUE
- #define TRUE
- #endif
- #ifndef FALSE
- #define FALSE
- #endif
在數(shù)據(jù)類型定義中,需要注意的一點(diǎn)是:如果你的程序需要用不同平臺下的編譯器來編譯,那么你要去查一下所使用的編譯器對這些宏定義控制的數(shù)據(jù)類型是否已經(jīng)定義了。例如:在 gcc 中沒有 BOOL 類型,但是在 MSVC 中,把 BOOL 類型定義為 int 型。
(2) 獲取最大、最小值
- #define MAX(a, b) (((a) > (b)) ? (a) : (b))
- #define MIN(a, b) (((a) < (b)) ? (a) : (b))
(3) 計算數(shù)組中的元素個數(shù)
- #define ARRAY_SIZE(x) (sizeof(x) / sizeof((x)[0]))
(4) 位操作
- #define BIT_MASK(x) (1 << (x))
- #define BIT_GET(x, y) (((x) >> (y)) & 0x01u)
- #define BIT_SET(x, y) ((x) | (1 << (y)))
- #define BIT_CLR(x, y) ((x) & (~(1 << (y))))
- #define BIT_INVERT(x, y) ((x) ^ (1 << (y)))
2. 與函數(shù)的區(qū)別
從上面這幾個宏來看,所有的這些操作都可以通過函數(shù)來實現(xiàn),那么他們各有什么優(yōu)缺點(diǎn)呢?
通過函數(shù)來實現(xiàn):
- 形參的類型需要確定,調(diào)用時對參數(shù)進(jìn)行檢查;
- 調(diào)用函數(shù)時需要額外的開銷:操作函數(shù)棧中的形參、返回值等;
通過宏來實現(xiàn):
- 不需要檢查參數(shù),更靈活的傳參;
- 直接對宏進(jìn)行代碼擴(kuò)展,執(zhí)行時不需要函數(shù)調(diào)用;
- 如果同一個宏在多處調(diào)用,會增加代碼體積;
還是舉一個例子來說明比較好,就拿上面的比較大小來說吧:
(1) 使用宏來實現(xiàn)
- #define MAX(a, b) (((a) > (b)) ? (a) : (b))
- int main()
- {
- printf("max: %d \n", MAX(1, 2));
- }
(2) 使用函數(shù)來實現(xiàn)
- int max(int a, int b)
- {
- if (a > b)
- return a;
- return b;
- }
- int main()
- {
- printf("max: %d \n", max(1, 2));
- }
除了函數(shù)調(diào)用的開銷,其它看起來沒有差別。這里比較的是 2 個整型數(shù)據(jù),那么如果還需要比較 2 個浮點(diǎn)型數(shù)據(jù)呢?
- 使用宏來調(diào)用:MAX(1.1, 2.2);一切 OK;
- 使用函數(shù)調(diào)用:max(1.1, 2.2); 編譯報錯:類型不匹配。
此時,使用宏來實現(xiàn)的優(yōu)勢就體現(xiàn)出來了:因為宏中沒有類型的概念,調(diào)用者傳入任何數(shù)據(jù)類型都可以,然后在后面的比較操作中,大于或小于操作都是利用了 C 語言本身的語法來執(zhí)行。
如果使用函數(shù)來實現(xiàn),那么就必須再定義一個用來操作浮點(diǎn)型的函數(shù),以后還有可能比較:char 型、long 型數(shù)據(jù)等等。
在 C++ 中,這樣的操作可以通過參數(shù)模板來實現(xiàn),所謂的模板也是一種代碼動態(tài)生成機(jī)制。當(dāng)定義了一個函數(shù)模板后,根據(jù)調(diào)用者的實參,來動態(tài)產(chǎn)生多個函數(shù)。例如定義下面這個函數(shù)模板:
- template<typename T> T max(T a, T b){
- if (a > b)
- return a;
- return b;
- }
- max(1, 2); // 實參是整型
- max(1.1, 2,2); // 實參是浮點(diǎn)型
當(dāng)編譯器看到 max(1, 2) 時,就會動態(tài)生成一個函數(shù) int max(int a, int b) { ... };
當(dāng)編譯器看到 max(1.1, 2.2) 時,又會動態(tài)生成另一個函數(shù) float max(float a, float b) { ... }。
所以,從代碼的動態(tài)生成角度看,宏定義和 C++ 中的模板參數(shù)有點(diǎn)神似,只不過宏定義僅僅是代碼擴(kuò)展而已。
下面這個例子也比較不錯,利用宏的類型無關(guān),來動態(tài)生成結(jié)構(gòu)體:
- #define VEC(T) \
- struct vector_##T { \
- T *data; \
- size_t size; \
- };
- int main()
- {
- VEC(int) vec_1 = { .data = NULL, .size = 0 };
- VEC(float) vec_2 = { .data = NULL, .size = 0 };
- }
這個例子中用到了 ##,下面會解釋這個知識點(diǎn)。在前面的例子中,宏的參數(shù)傳遞的都是一些變量,而這里傳遞的宏參數(shù)是數(shù)據(jù)類型,通過宏的類型無關(guān)性,達(dá)到了“動態(tài)”創(chuàng)建結(jié)構(gòu)體的目的:
- struct vector_int {
- int *data;
- size_t size;
- }
- struct vector_float {
- float *data;
- size_t size;
- }
這里有一個陷阱需要注意:傳遞的數(shù)據(jù)類型中不能有空格,如果這樣使用:VEC(long long),那替換之后得到:
- struct vector_long long { // 語法錯誤
- long long *data;
- size_t size;
- }
四、符號:# 與 ##
這兩個符號在編程中的作用也是非常巧妙,夸張的說一句:在任何框架性代碼中,都能見到它們的身影!作用如下:
- #:把參數(shù)轉(zhuǎn)換成字符串;
- ##:連接參數(shù)。
1. #: 字符串化
直接看最簡單的例子:
- #define STR(x) #x
- printf("string of 123: %s \n", STR(123));
傳入的是一個數(shù)字 123,輸出的結(jié)果是字符串 “123”,這就是字符串化。
2. ##:參數(shù)連接
把宏中的參數(shù)按照字符進(jìn)行拼接,從而得到一個新的標(biāo)識符,例如:
- #define MAKE_VAR(name, no) name##no
- int main(void)
- {
- int MAKE_VAR(a, 1) = 1;
- int MAKE_VAR(b, 2) = 2;
- printf("a1 = %d \n", a1);
- printf("b2 = %d \n", b2);
- return 0;
- }
當(dāng)調(diào)用宏 MAKE_VAR(a, 1) 后,符號 ## 把兩側(cè)的 name 和 no 首先替換為 a 和 1,然后連接得到 a1。然后在調(diào)用語句中前面的 int 數(shù)據(jù)類型就說明了 a1 是一個整型數(shù)據(jù),最后初始化為 1。
五、可變參數(shù)的處理
1. 參數(shù)名的定義和使用
宏定義的參數(shù)個數(shù)可以是不確定的,就像調(diào)用 printf 打印函數(shù)一樣,在定義的時候,可以使用三個點(diǎn)(...)來表示可變參數(shù),也可以在三個點(diǎn)的前面加上可變參數(shù)的名稱。
如果使用三個點(diǎn)(...)來接收可變參數(shù),那么在使用的時候就需要使用 VA_ARGS 來表示可變參數(shù),如下:
- #define debug1(...) printf(__VA_ARGS__)
- debug1("this is debug1: %d \n", 1);
如果在三個點(diǎn)(...)的前面加上了一個參數(shù)名,那么在使用時就一定要使用這個參數(shù)名,而不能使用 VA_ARGS 來表示可變參數(shù),如下:
- #define debug2(args...) printf(args)
- debug1("this is debug2: %d \n", 2);
2. 可變參數(shù)個數(shù)為零的處理
看一下這個宏:
- #define debug3(format, ...) printf(format, __VA_ARGS__)
- debug3("this is debug4: %d \n", 4);
編譯、執(zhí)行都沒有問題。但是如果這樣來使用宏:
- debug3("hello \n");
編譯的時候,會出現(xiàn)錯誤: error: expected expression before ‘)’ token。為什么呢?
看一下宏擴(kuò)展之后的代碼(__VA_ARGS__為空):
- printf("hello \n",);
看出問題了吧?在格式化字符串的后面多了一個逗號!為了解決問題,預(yù)處理器給我們提供了一個方法:通過 ## 符號把這個多余的逗號給自動刪掉。于是宏定義改成下面這樣就沒有問題了。
- #define debug3(format, ...) printf(format, ##__VA_ARGS__)
類似的,如果自己定義了可變參數(shù)的名字,也在前面加上 ##,如下:
- #define debug4(format, args...) printf(format, ##args)
六、奇思妙想的宏
宏擴(kuò)展的本質(zhì)就是文本替換,但是一旦加上可變參數(shù)(__VA_ARGS__)和 ## 的連接功能,就能夠變化出無窮的想象力。
我一直堅信,模仿是成為高手的第一步,只有見多識廣、多看、多學(xué)習(xí)別人是怎么來使用宏的,然后拿來為己所用,按照“先僵化-再優(yōu)化-最后固化”這個步驟來訓(xùn)練,總有一天你也能成為高手。
這里我們就來看幾個利用宏定義的巧妙實現(xiàn)。
1. 日志功能
在代碼中添加日志功能,幾乎是每個產(chǎn)品的標(biāo)配了,一般見到最普遍的是下面這樣的用法:
- #ifdef DEBUG
- #define LOG(...) printf(__VA_ARGS__)
- #else
- #define LOG(...)
- #endif
- int main()
- {
- LOG("name = %s, age = %d \n", "zhangsan", 20);
- return 0;
- }
在編譯的時候,如果需要輸出日志功能就傳入宏定義 DEBUG,這樣就能打印輸出調(diào)試信息,當(dāng)然實際的產(chǎn)品中需要寫入到文件中。如果不需要打印語句,通過把打印日志信息那條語句定義為空語句來達(dá)到目的。
換個思路,我們還可以通過條件判斷語句來控制打印信息,如下:
- #ifdef DEBUG
- #define debug if(1)
- #else
- #define debug if(0)
- #endif
- int main()
- {
- debug {
- printf("name = %s, age = %d \n", "zhangsan", 20);
- }
- return 0;
- }
這樣控制日志信息的看到的不多,但是也能達(dá)到目的,放在這里只是給大家開闊一下思路。
2. 利用宏來迭代每個參數(shù)
- #define first(x, ...) #x
- #define rest(x, ...) #__VA_ARGS__
- #define destructive(...) \
- do { \
- printf("first is: %s\n", first(__VA_ARGS__)); \
- printf("rest are: %s\n", rest(__VA_ARGS__)); \
- } while (0)
- int main(void)
- {
- destructive(1, 2, 3);
- return 0;
- }
主要的思想就是:每次把可變參數(shù) VA_ARGS 中的第一個參數(shù)給分離出來,然后把后面的參數(shù)再遞歸處理,這樣就可以分離出每一個參數(shù)了。我記得侯杰老師在 C++ 的視屏中,利用可變參數(shù)模板這個語法,也實現(xiàn)了類似的功能。
剛才在有道筆記中居然找到了侯杰老師演示的代碼,熟悉 C++ 的小伙伴可以研究下下面這段代碼:
- // 遞歸的最后一次調(diào)用
- void myprint()
- {
- }
- template <typename T, typename... Types>
- void myprint(const T &first, const Types&... args)
- {
- std::cout << first << std::endl;
- std::cout << "remain args size = " << sizeof...(args) << std::endl;
- // 把其他參數(shù)遞歸調(diào)用
- myprint(args...);
- }
- int main()
- {
- myprint("aaa", 7.5, 100);
- return 0;
- }
3. 動態(tài)的調(diào)用不同的函數(shù)
- // 普通的枚舉類型
- enum {
- ERR_One,
- ERR_Two,
- ERR_Three
- };
- // 利用 ## 的拼接功能,動態(tài)產(chǎn)生 case 中的比較值,以及函數(shù)名。
- #define TEST(no) \
- case ERR_##no: \
- Func_##no(); \
- break;
- void Func_One()
- {
- printf("this is Func_One \n");
- }
- void Func_Two()
- {
- printf("this is Func_Two \n");
- }
- void Func_Three()
- {
- printf("this is Func_Three \n");
- }
- int main()
- {
- int c = ERR_Two;
- switch (c) {
- TEST(One);
- TEST(Two);
- TEST(Three);
- };
- return 0;
- }
在這個例子中,核心在于 TEST 宏定義,通過 ## 拼接功能,構(gòu)造出 case 分支的比較目標(biāo),然后動態(tài)拼接得到對應(yīng)的函數(shù),最后調(diào)用這個函數(shù)。
4. 動態(tài)創(chuàng)建錯誤編碼與對應(yīng)的錯誤字符串
這也是一個非常巧妙的例子,利用了 #(字符串化) 和 ##(拼接) 這 2 個功能來動態(tài)生成錯誤編碼碼和相應(yīng)的錯誤字符串:
- #define MY_ERRORS \
- E(TOO_SMALL) \
- E(TOO_BIG) \
- E(INVALID_VARS)
- #define E(e) Error_## e,
- typedef enum {
- MY_ERRORS
- } MyEnums;
- #undef E
- #define E(e) #e,
- const char *ErrorStrings[] = {
- MY_ERRORS
- };
- #undef E
- int main()
- {
- printf("%d - %s \n", Error_TOO_SMALL, ErrorStrings[0]);
- printf("%d - %s \n", Error_TOO_BIG, ErrorStrings[1]);
- printf("%d - %s \n", Error_INVALID_VARS, ErrorStrings[2]);
- return 0;
- }
我們把宏展開之后,得到一個枚舉類型和一個字符串常量數(shù)組:
- typedef enum {
- Error_TOO_SMALL,
- Error_TOO_BIG,
- Error_INVALID_VARS,
- } MyEnums;
- const char *ErrorStrings[] = {
- "TOO_SMALL",
- "TOO_BIG",
- "INVALID_VARS",
- };
宏擴(kuò)展之后的代碼是不是很簡單啊。編譯、執(zhí)行結(jié)果如下:
- 0 - TOO_SMALL
- 1 - TOO_BIG
- 2 - INVALID_VARS
七、總結(jié)
有些人對宏愛之要死,多到濫用的程度;而有些人對宏恨之入骨,甚至用上了邪惡(evil)這個詞!其實宏對于 C 來說,就像菜刀對于廚師和歹徒一樣:用的好,可以讓代碼結(jié)構(gòu)簡潔、后期維護(hù)特別方便;用的不好,就會引入晦澀的語法、難以調(diào)試的 Bug。
對于我們開發(fā)人員來說,只要在程序的執(zhí)行效率、代碼的可維護(hù)性上做好平衡就可以了。
本文轉(zhuǎn)載自微信公眾號「 IOT物聯(lián)網(wǎng)小鎮(zhèn)」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系 IOT物聯(lián)網(wǎng)小鎮(zhèn)公眾號。