成功識別日志中的數據泄漏漏洞并對其進行緩解
我會在本文介紹我是如何與r2c的另一位開發人員成功識別日志中的數據泄漏,從而修復了該漏洞并徹底杜絕其今后的再發生,整個過程只需幾個小時就可以完成了。
作為一名開發人員和工程經理,我一直癡迷于尋找一種可以不需要安全團隊完全參與,即可快速解決整個涉及組織安全漏洞的方法。
為什么要這么做呢?好處有很多:
- 可以快速解決組織出現的安全漏洞。在實踐過程中,該方法可以大大加快安全防御的速度,以至于我們可以在識別出漏洞后的幾分鐘內建立起安全的防護措施,如果是走組織流程,則安全漏洞則會持續數天或數周。
- 當開發人員可以輕松地自行解決安全漏洞時,它可以使安全團隊騰出精力來專注于整個組織的“全局”安全性。我希望安全工程師考慮如何選擇框架、設置工具、幫助實現安全體系結構,以及構建深度防御,而不是找到我在本文所述的XSS漏洞。
我將以上過程稱為“self-service DevSec。
接下來,我將介紹我們在日常開發工作過程中遇到的一個安全漏洞。我將討論我們如何發現此漏洞的,以及如何在短短幾個小時內修復整個安全漏洞,并使用Semgrep防止該漏洞再次發生。Semgrep是一個開源工具,用于使用熟悉的語法進行輕量級靜態分析。
上個月,我正在與r2c的另一位工程師Clara McCreery一起調試Flask Web應用驗證流程。就像許多工程師面臨著令人困惑的調試問題一樣,我們的第一步就是將Web應用程序放入調試日志記錄。
具體來說,我們想知道數據庫操作的情況,因此我們將ORM(在本例中,我們使用SQLAlchemy)設置為INFO級別的日志記錄,方法如下:
- logging.getLogger("sqlalchemy.engine.base.Engine").setLevel(logging.INFO)
這會將SQLAlchemy配置為記錄所有SQL語句以及傳遞的參數,讓我們看一下我們看到的一些輸出結果:
- INFO:werkzeug:127.0.0.1 - - [25/Sep/2020 11:50:01] "POST /api/auth/authenticate HTTP/1.1" 200 -
- INFO:sqlalchemy.engine.base.Engine:BEGIN (implicit)
- INFO:sqlalchemy.engine.base.Engine:SELECT token.id AS token_id, token.token AS token_token, token.name AS token_name
- FROM token
- WHERE token.token = %(token_1)s
- LIMIT %(param_1)sINFO:sqlalchemy.engine.base.Engine:{'token_1': $2a$10$KVsyW1jjKn.pvkVi3w9Rn.1mwnZFd7F2SFveGDG8flIhbe.MoJH4G, 'param_1': 1}
我們絕對不應該記錄令牌,即使已安全地對其進行哈希處理。在此示例中,處于講解的目的,實際令牌值已更改。
首先要制定一個計劃
至此,我們已經確定了一個安全漏洞,并且希望在保留檢查日志能力的同時修復此漏洞。具體步驟如下:
- 緩解當前的安全漏洞;
- 尋找一個永久的解決方案,以備不時之需。永久的解決方案意味著對我們的系統進行深層次的改變。理想情況下,該解決方案是在整個組織中自動化和無縫的。
- 添加一種機制來強制我們的解決方案在整個組織范圍內使用。
接下來,我將指導你完成每個步驟。需要注意的是,我們能夠在幾個小時內完成整個流程,而無需與安全團隊合作。
緩解當前的安全漏洞
這里的緩解措施非常簡單,因為我們已經知道了漏洞的根本原因,為此可以快速還原日志記錄的更改過程。然后,我們可以對日志進行快速審核,以確保僅泄漏了開發測試令牌。
永久解決方案
那我們如何防止SQLAlchemy記錄敏感數據?
第一步是閱讀文檔。快速搜索“引擎日志中的sqlalchemy隱藏參數”將我們鏈接到SQLAlchemy Engine文檔。稍后進行詳細閱讀,這樣我們就發現了hide_parameters標志,該標志防止日志記錄框架在日志或異常中發出任何參數。
雖然這肯定可以防止發現的安全漏洞,但對我們來說信息量太小了,因為我們想知道例如數據庫ID等信息,以便進行調試。
真正的解決方案
然后,我們檢查了相關的SQLAlchemy源代碼,相關代碼在sqlalchemy / engine / base.py中:
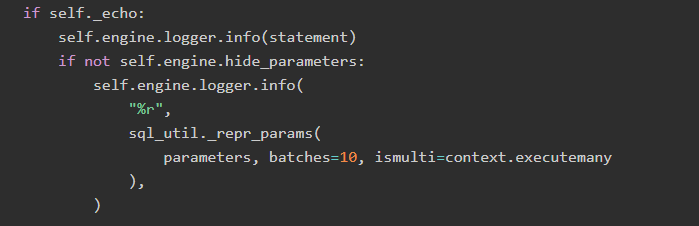
sql_util._repr_params依次運行:
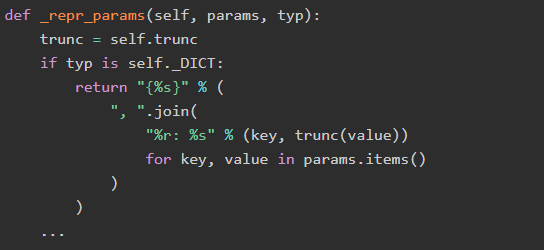
通過研究trunc,我們發現它通過將參數的repr截斷為最大字符數來轉換參數值,這意味著我們應該重寫參數對象的repr方法以防止敏感日志記錄。
此時,我們像優秀的工程師一樣,使用了一條懶惰的策略,因為我發現的這個GitHub漏洞,Mike Bayer已經發布了一個很好的解決方案,所以我就進行了一些復制,關鍵代碼如下:
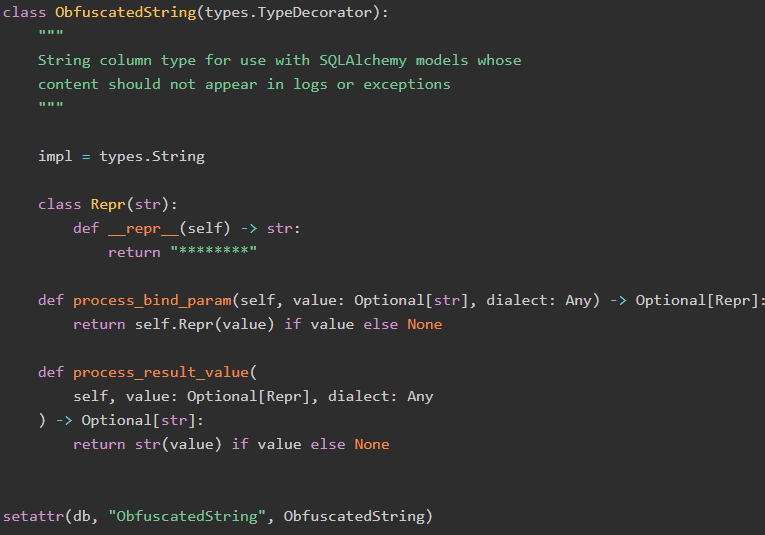
這段代碼的作用是什么?你可以發現它用新的ObfuscatedString.Repr參數替換了我們原來的str參數。登錄時或發出異常消息時,該字符串將替換為我們的********。由于參數仍然被綁定為原始字符串(通過impl = types.String),因此仍然插入和從數據庫中選擇正確的值。
要使用這個新的字段類型,我們設置令牌的字段類型如下:

然后,我們重新啟用INFO日志記錄,并檢查我們是否正確混淆了文本:
- INFO:werkzeug:127.0.0.1 - - [25/Sep/2020 13:48:55] "GET /api/agent/deployments/1/policies HTTP/1.1" 200 -
- INFO:sqlalchemy.engine.base.Engine:BEGIN (implicit)
- INFO:sqlalchemy.engine.base.Engine:SELECT token.id AS token_id, token.token AS token_token, token.name AS token_name
- FROM token
- WHERE token.token = %(token_1)s
- LIMIT %(param_1)s
- INFO:sqlalchemy.engine.base.Engine:{'token_1': ********, 'param_1': 1}
為了完整起見,我們還在開發數據庫控制臺中驗證了是否存儲和檢索了正確的值。
執行過程
應該說,我們已經暫時解決了安全漏洞,以便可以重新調試原始的身份驗證漏洞。但要徹底修復整個漏洞。我們將如何做?
以下有一些想法,我相信我們都曾經遇到過:
- 在安全審查中阻止對SQLAlchemy模型的所有提交。
- 為所有開發人員舉辦年度安全培訓,包括記錄敏感數據的漏洞。
- 每周審核日志。
- 向你的SAST供應商提出漏洞,要求他們添加檢查以捕獲敏感記錄的數據。
如果要從這篇博客文章中得出一個中心結論的話,那就是:這些都不是理想的解決方案,原因如下:
- 阻止提交會在開發過程中引入不必要的拖延,降低開發速度,并會分散安全團隊的注意力。
- 安全培訓是安全計劃的重要組成部分,也是讓開發人員意識到不斷發展的安全威脅的必要條件,但是人類的記憶力很差,我們可能會忘記幾個月甚至幾天前聽到的事情。
- 定期審核(例如阻止提交)會給幾乎肯定是超負荷的安全團隊帶來沉重的工作量;
- 你的SAST提供商當然會歡迎你的建議,但是你會依賴他們的軟件發布周期,并且可能幾個月都看不到可用的檢查。此外,如果你的漏洞是特定于某個領域的,則實施廣泛地檢查甚至沒有意義。
幸運的是,Semgrep為我們提供了一個簡單的解決方案:在代碼中定義一個不變量,并在每次CI運行時使用Semgrep掃描對其進行強制執行。
在r2c中,我們使用GitHub操作在每個合并請求上運行Semgrep。我們使用由Semgrep .dev管理的管理策略、規則字段表和通知設置來定義Semgrep應該運行哪些檢查。
為了保證我們的代碼不會再出現問題,我訪問了semgrep.dev/editor并編寫了一個快速規則來檢測潛在的不安全日志SQLAlchemy字段。
這是Semgrep的YAML定義語言中的規則定義:
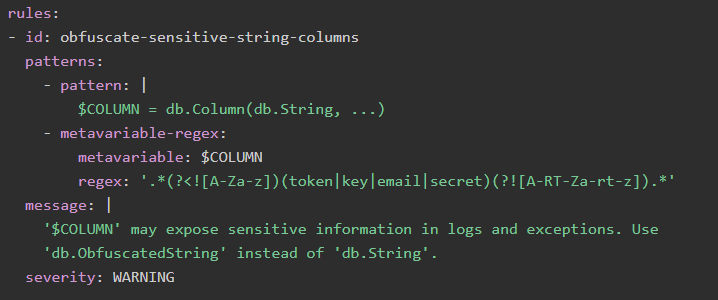
這個規則有什么作用?詳細解釋如下:
- id:我們為規則提供了一個簡潔的描述性ID,以便任何在編輯器或CI輸出中看到它的開發人員都可以輕松參考。
- patterns:這由兩部分組成:
- pattern:此表達式告訴Semgrep如何在我們的代碼庫(在此示例中,我們的SQLAlchemy實例稱為db)中查找具有String字段類型的任何SQLAlchemy ORM字段定義,它還將字段名稱綁定到名為COLUMN的元變量。
- metavvariable -regex:這個表達式告訴Semgrep只有在字段metavariable包含單詞片段(如token、email、key或secret)時才報告匹配。正則表達式包含了很多細節聲明,以防止我們匹配不相關的單詞,如keyboard。
- message:當Semgrep匹配我們的模式時,我們希望確保我們解釋檢測到的漏洞是什么,為什么它是一個漏洞,以及如何修復它。這些信息將有助于開發人員獨立解決漏洞,而不會造成混亂或不必要的誤讀。
- severity:你可以自定義你領域中任何漏洞的嚴重程度。
然后快速地按下“部署到策略”按鈕,就可以保證所有的web應用程序都得到了保護。
通過我們的VS Code擴展將Semgrep集成到編程工作流中的開發人員也會開始在他們的IDE中產生效果。
請注意,此解決方案是有意迭代的:我們可能會發現更多字段名稱被標識為敏感字段,或者還希望包含db.Text類型。幸運的是,這是一個快速修訂,并根據需要重新部署。
總結
在這篇文章中,我演示了你作為一名開發人員或管理人員如何使用輕量級靜態分析(如Semgrep)來幫助在代碼中強制執行不變量。
在r2c中,我們習慣性地使用Semgrep來防止自己重復犯錯誤:意外地使調試器處于提交狀態?有一條規則可以防止這種情況發生。當我們發現導入某個庫會減慢程序的初始化速度時,我們編寫了一條規則來確保它被延遲加載。
本文翻譯自:https://r2c.dev/blog/2020/fixing-leaky-logs-how-to-find-a-bug-and-ensure-it-never-returns/