













2021年的機器學習生命周期
您實際上是如何完成一個機器學習項目的?有哪些工具可以幫助完成每一步?
> Photo by Tolga Ulkan on Unsplash
在這個時代,每個人都在學習機器學習(ML)。似乎每個收集數據的公司都在嘗試找出某種方式來使用AI和ML分析其業務并提供自動化解決方案。
到2027年,機器學習的市值預計將達到1170億美元—《財富》雜志
ML的大量涌入導致許多新手沒有正式的背景。令人高興的是,更多的人開始興奮并學習了這一領域,這很高興,但很顯然,將ML項目整合到生產環境中并不是一件容易的事。
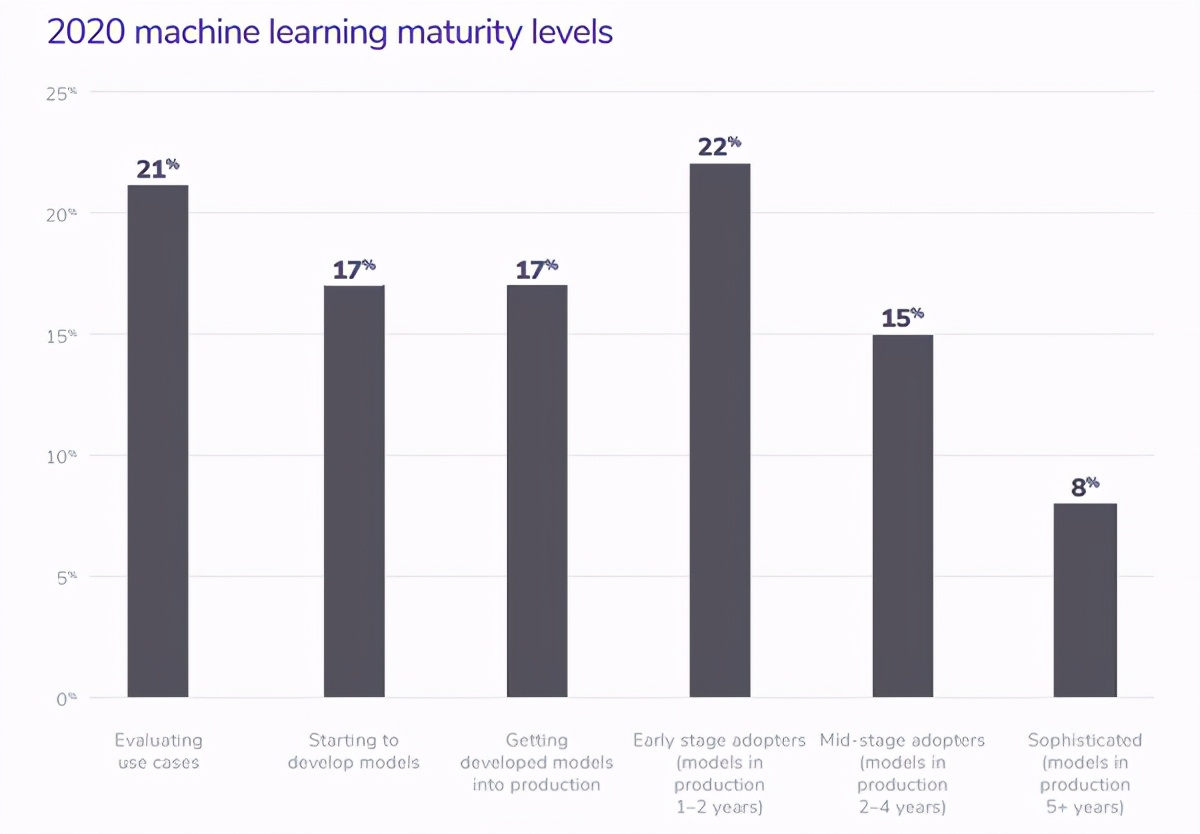
Image from the 2020 State of Enterprise ML by Algorithmia based on 750 businesses
55%的企業尚未將它們的ML模型投入生產— Algorithmia
如果您擁有訓練模型所必需的數據和計算資源,那么很多人似乎都認為ML項目非常簡單。他們再犯錯了。如果不部署模型,這種假設似乎會導致大量的時間和金錢成本。

> Naive assumption of the ML lifecycle (Image by author)
在本文中,我們將討論ML項目的生命周期實際上是什么樣的,以及一些有助于解決該問題的工具。
機器學習生命周期
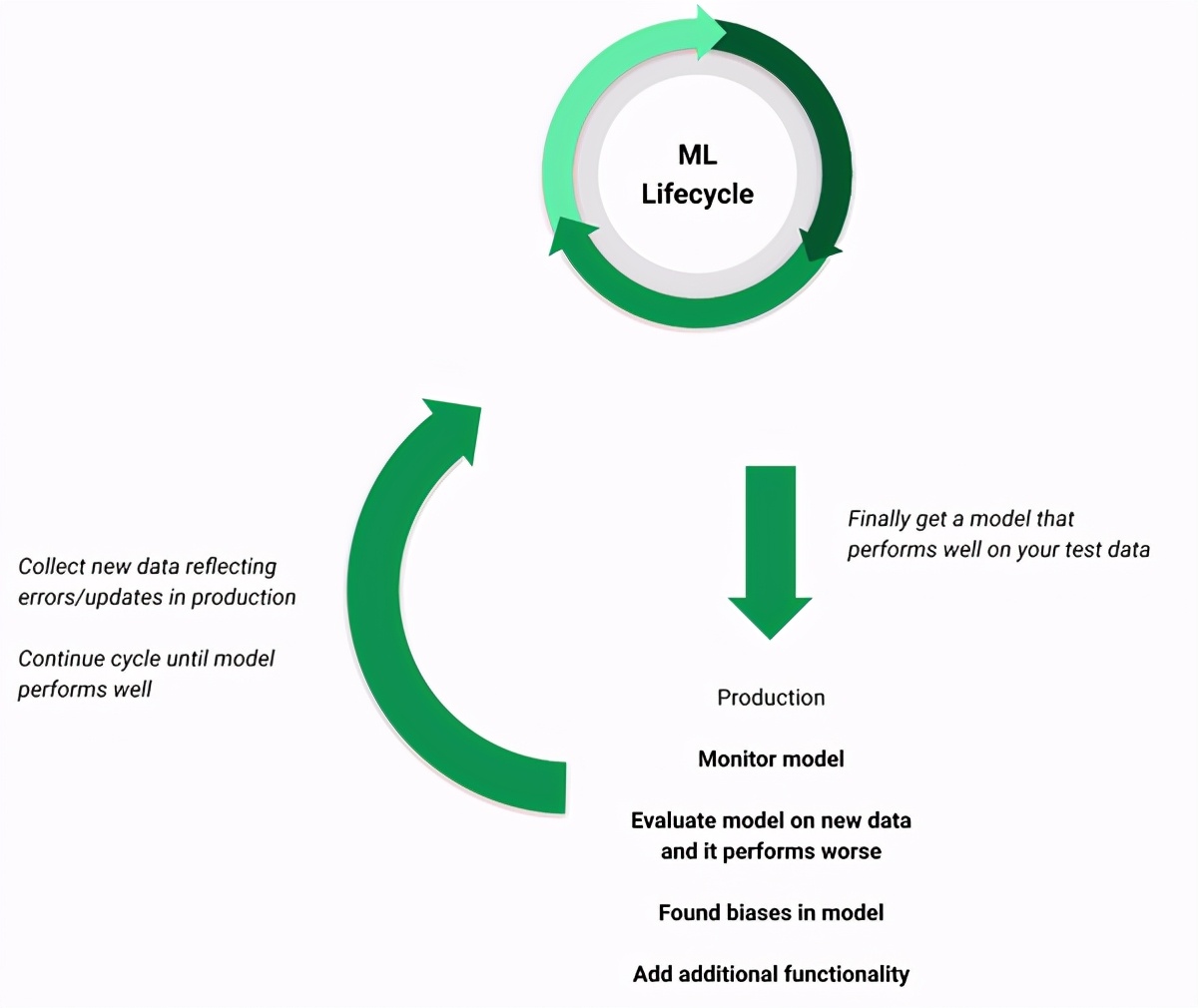
實際上,機器學習項目不是簡單明了的,它們是在改善數據,模型和評估之間進行的一個循環,從未真正完成。這個周期對于開發ML模型至關重要,因為它專注于使用模型結果和評估來完善數據集。高質量數據集是訓練高質量模型的最可靠方法。如此反復循環的速度決定了您的成本,幸運的是,有些工具可以在不犧牲質量的情況下幫助加快循環速度。
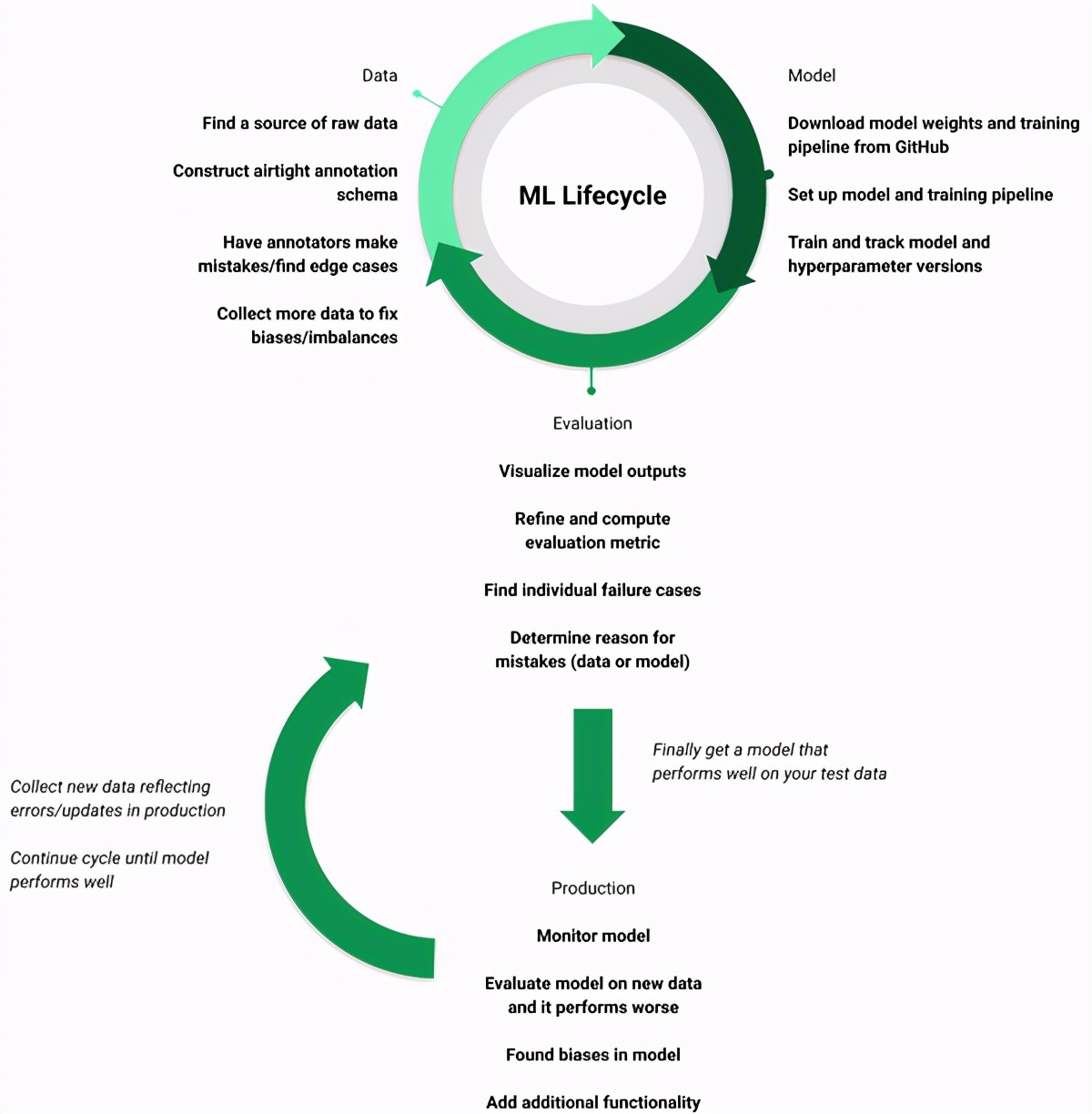
> A realistic example of ML lifecycle (Image by author)
與任何系統一樣,即使已部署的ML模型也需要監視,維護和更新。您不能只是部署ML模型而忘了它,而是期望它在其余時間中能夠像在現實世界中的測試集上一樣工作。當您發現模型中的偏差,添加新數據源,需要其他功能等時,部署在生產環境中的ML模型將需要更新。這使您重新回到數據,模型和評估周期。
截至2021年,深度學習在十多年來一直很重要,并幫助使ML成為市場的領先和中心。機器學習行業蓬勃發展,開發了無數產品來協助機器學習模型的創建。ML生命周期的每一步都有一些工具,您可以使用它們來加快流程,而不會成為沒有ML項目的公司之一。
下一節將深入探討ML生命周期的每個階段,并重點介紹流行的工具。
階段1:數據
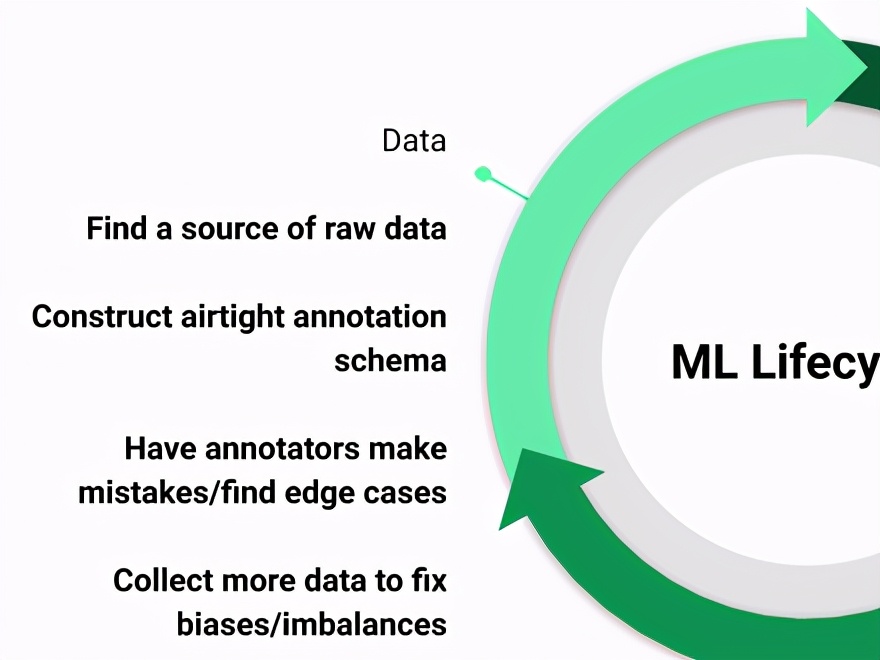
> Data in the ML lifecycle (Image by author)
雖然最終目標是建立高質量的模型,但是訓練一個好的模型的生命線在于傳遞的數據的數量,更重要的是質量。
ML生命周期中與數據相關的主要步驟是:
數據收集-無論質量如何,都收集盡可能多的原始數據最后,無論如何,僅注釋其中的一小部分,這是大部分成本的來源。當模型性能出現問題時,可以根據需要添加大量數據,這很有用。
- 公開數據集列表
定義注釋模式-這是生命周期數據階段最重要的部分之一,通常會被忽略。構造不佳的注釋架構將導致類和邊緣情況的模棱兩可,從而使訓練模型更加困難。
例如,對象檢測模型的性能在很大程度上取決于大小,位置,方向和截斷等屬性。因此,在注釋期間包括對象大小,密度和遮擋之類的屬性可以提供創建模型可以學習的高質量訓練數據集所需的關鍵元數據。
- Matplotlib,Plotly —繪制數據的屬性
- Tableau-更好地了解您的數據的分析平臺
數據注釋-注釋是一次又一次地執行幾個小時的相同任務的乏味過程,這就是為什么注釋服務是一項蓬勃發展的業務的原因。結果是注釋者可能會犯許多錯誤。盡管大多數注釋公司保證最大錯誤百分比(例如最大錯誤為2%),但更大的問題是注釋架構定義不正確,導致注釋者決定以不同的方式標記樣本。注釋公司的質量檢查團隊很難發現這一點,這是您需要檢查的事情。
- Scale, Labelbox, Prodigy—流行的注釋服務
- Mechanical Turk —眾包注釋平臺
- CVAT — DIY計算機視覺注釋
- Doccano — NLP特定注釋工具
- Centaur Labs —醫療數據標記服務
改善數據集和注釋-嘗試改善模型性能時,您可能會在這里花費大部分時間。如果您的模型正在學習但表現不佳,那么罪魁禍首幾乎總是一個訓練數據集,其中包含偏見和錯誤,這些偏見和錯誤正在為模型創建性能上限。改善模型通常涉及諸如硬樣本挖掘(添加與模型失敗的其他樣本相似的新訓練數據),基于模型學習到的偏差重新平衡數據集,更新注釋和模式以添加新標簽并優化現有標簽的方案。。
- DAGsHub —數據集版本控制
- FiftyOne —可視化數據集并發現錯誤
階段2:模型

> Models in the ML lifecycle (Image by author)
即使此過程的輸出是模型,理想情況下,您仍將在此循環中花費最少的時間。
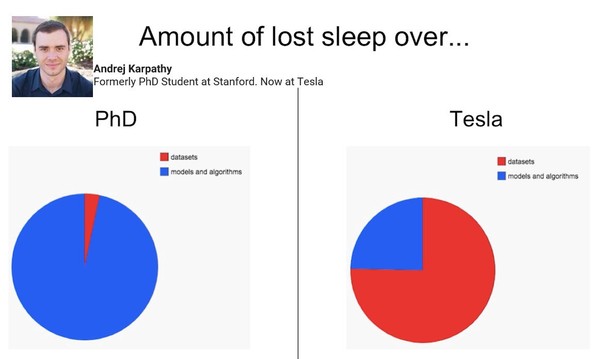
In industry, more time is spent on datasets than models. Credit to Andrej Karpathy
探索現有的預訓練模型-這里的目標是盡可能多地重用可用資源,以使自己最好地開始建模生產。如今,轉移學習是深度學習的核心租戶。您可能不會從頭開始創建模型,而是對在相關任務上預先訓練的現有模型進行微調。例如,如果要創建遮罩檢測模型,則可能會從GitHub下載預訓練的面部檢測模型,因為這是更受歡迎的話題,需要做更多的工作。
- FiftyOne 模型動物園—只需一行代碼即可下載并運行模型
- TensorFlow Hub —訓練有素的機器學習模型的存儲庫
- modelzoo.co —針對各種任務和庫的預訓練深度學習模型
構建訓練循環-您的數據可能會與用于預訓練模型的數據有所不同。對于圖像數據集,在為模型設置訓練管道時需要考慮輸入分辨率和對象大小之類的東西。您還需要修改模型的輸出結構,以匹配標簽的類和結構。PyTorch閃電提供了一種簡單的方法,可以用有限的代碼擴大模型訓練的規模。
- Scikit Learn —構建和可視化經典ML系統
- PyTorch,PyTorch Lightning,TensorFlow,TRAX —流行的深度學習Python庫
- Sagemaker —在Sagemaker IDE中構建和訓練ML系統
實驗跟蹤-這整個周期可能需要多次迭代。您最終將訓練許多不同的模型,因此在跟蹤模型的不同版本以及對其進行訓練的超參數和數據時要一絲不茍,將大大有助于保持事物的組織性。
階段3:評估
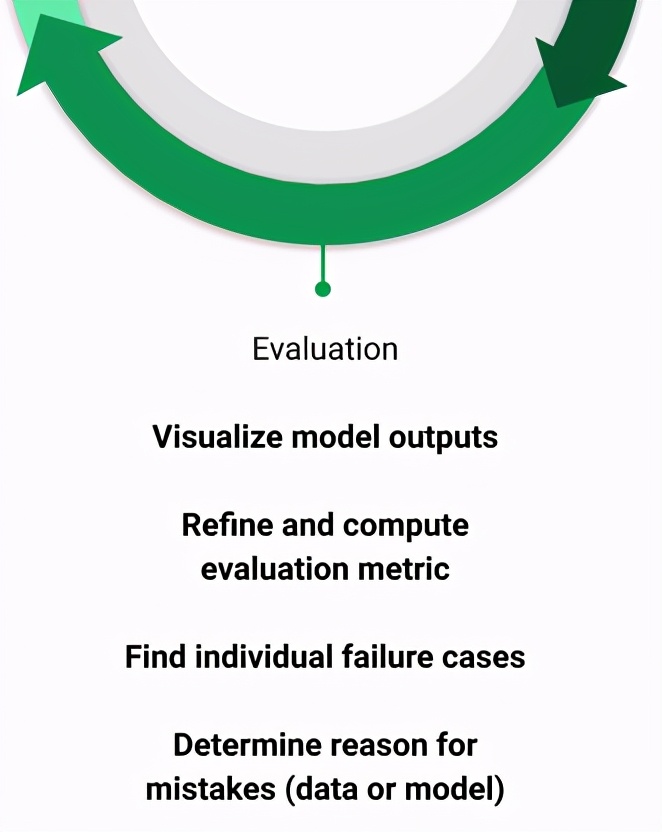
> Evaluation in the ML lifecycle (Image by author)
設法獲得學習了訓練數據的模型后,就該開始挖掘并查看其在新數據上的表現如何。
評估ML模型的關鍵步驟:
可視化模型輸出-擁有訓練有素的模型后,您需要立即在幾個樣本上運行它并查看輸出。這是在對整個測試集進行評估之前,找出培訓/評估管道中是否存在任何錯誤的最佳方法。它還將顯示是否存在任何明顯的錯誤,例如您的兩個類的標簽錯誤。
- OpenCV,Numpy,Matplotlib —編寫自定義可視化腳本
- FiftyOne —在圖像和視頻上可視化計算機視覺任務的輸出
選擇正確的指標-提出一個或幾個指標可以幫助比較模型的整體性能。為了確保您選擇適合您任務的最佳模型,應開發符合最終目標的指標。當您發現要跟蹤的其他重要品質時,還應該更新指標。例如,如果要開始跟蹤對象檢測模型在小對象上的性能,請對包圍盒<0.05作為對象之一的對象使用mAP。
盡管這些總體數據集指標可用于比較多個模型的性能,但它們很少有助于理解如何提高模型的性能。
- Scikit學習-提供通用指標
- Python,Numpy-開發自定義指標
查看故障案例-模型所做的一切都基于對其進行訓練的數據。因此,假設它能夠學習某些東西,如果它的性能比您預期的要差,則需要查看數據。查看模型運行良好的情況可能很有用,但是查看模型正確預測的假陽性和假陰性至關重要。在仔細研究了這些樣本之后,您將開始看到模型中的故障模式。
例如,下圖顯示了來自“打開圖像”數據集的樣本,一個假陽性顯示為后輪。事實證明,這種誤報是缺少注釋。驗證數據集中的所有車輪注釋并修復其他類似的錯誤可以幫助改善模型在車輪上的性能。
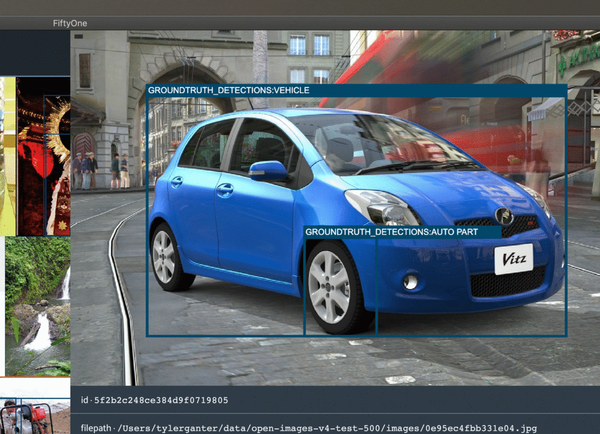
> Image credit to Tyler Ganter (source)
- FiftyOne, Aquarium, Scale Nucleus—調試數據集以發現錯誤
制定解決方案-確定故障案例是找出解決方法的第一步,以提高模型性能。在大多數情況下,它可以回溯到添加訓練數據,類似于模型失敗的地方,但是它還可以包括更改管道中的預處理或后處理步驟或修復注釋之類的事情。無論解決方案是什么,您都只能通過了解模型失敗的地方來解決問題。
階段4:生產
> Deploying a model (Image by author)
最后!您已經建立了一個模型,該模型可以很好地執行您的評估指標,并且在各種極端情況下都不會出現重大錯誤。
現在,您需要:
監控模型-測試您的部署,以確保您的模型相對于評估指標和推理速度之類的測試數據仍能按預期運行。
- Pachyderm,Algorithmia,Datarobot,Kubeflow,MLFlow —部署和監視模型和管道
- Amazon Web Services,Google AutoML,Microsoft Azure — ML模型的基于云的解決方案
評估新數據-在生產中使用模型意味著您將經常通過從未經過測試的模型傳遞全新數據。進行評估并挖掘特定的樣本,以查看模型如何處理遇到的任何新數據,這一點很重要。
繼續理解模型-模型中的某些錯誤和偏見可能很根深蒂固,需要很長時間才能發現。您需要針對各種可能導致問題的邊緣情況和趨勢不斷測試和探查模型,如果這些情況可能會被客戶發現,則會引起問題。
擴展功能-即使一切運行正常,該模型也可能無法實現您期望的利潤增長。從添加新類,開發新數據流到使模型更高效,有無數種方法可以擴展當前模型的功能以使其變得更好。每當您要改善系統時,都需要重新啟動ML生命周期以更新數據,建模和評估所有內容,以確保新功能能夠按預期工作。
FiftyOne
上面的內容很籠統,沒有偏見,但是我想向您介紹我一直在使用的工具。
在ML生命周期的各個部分都有許多工具。但是,非常缺乏工具可以幫助我在本文中強調的一些關鍵點。可視化復雜數據(例如圖像或視頻)和標簽,或編寫查詢以查找模型效果不佳的特定情況等操作通常是通過手動腳本完成的。
我一直在Voxel51上開發FiftyOne,這是一種開源數據可視化工具,旨在幫助調試數據集和模型并填補這一空白。FiftyOne使您可以在本地或遠程可視化GUI中的圖像和視頻數據集以及模型預測。它還提供了強大的功能,可以評估模型并針對數據集或模型輸出的任何方面編寫高級查詢。
FiftyOne可以在筆記本電腦上運行,因此請使用此Colab筆記本電腦在瀏覽器中進行嘗試。或者,您可以使用pip輕松安裝它。
pip install fiftyone
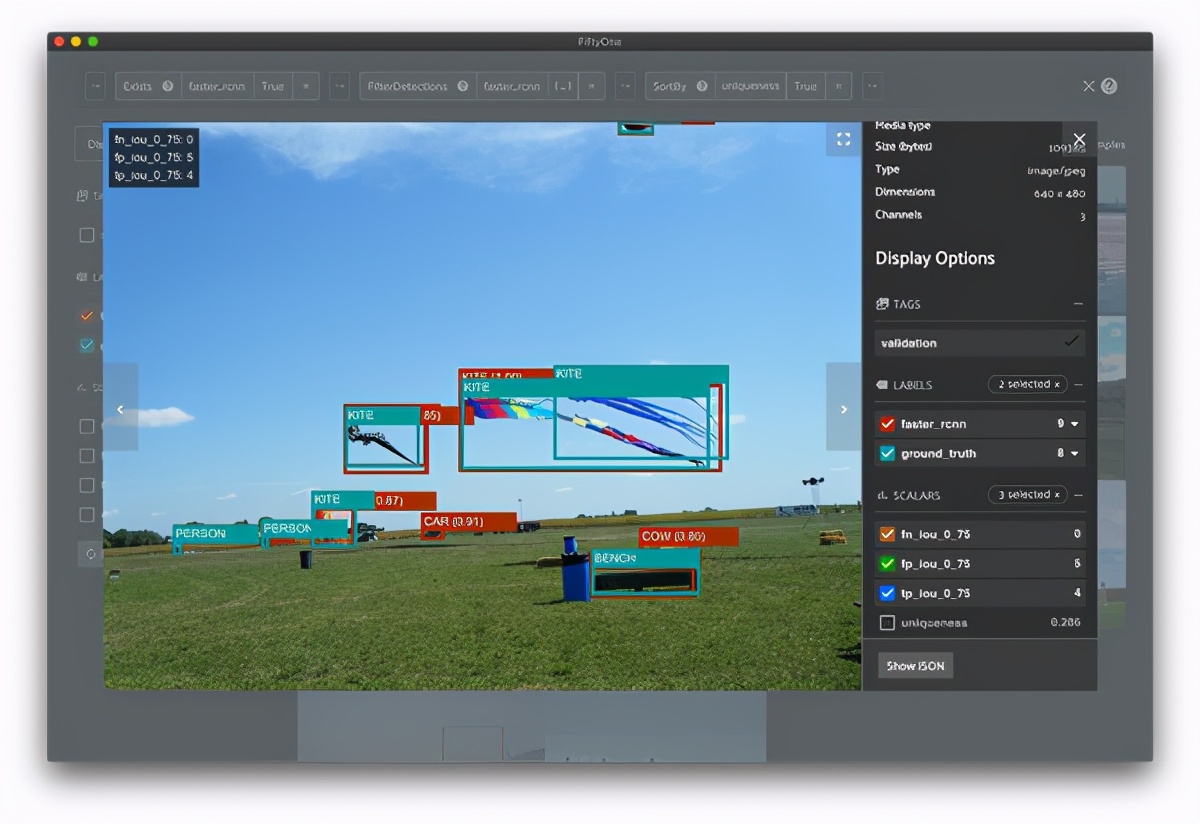
> Sample from object detection model and dataset in FiftyOne (Image by author)
概要
試圖將機器學習(ML)納入其業務的所有公司中只有一小部分設法將模型實際部署到生產中。ML模型的生命周期不是直截了當的,而是需要在數據和注釋改進,模型和訓練流水線構建以及樣本級別評估之間進行連續迭代。如果您知道自己要干什么,那么這個周期最終可能會產生可用于生產的模型,但是還需要隨著時間的推移進行維護和更新。幸運的是,開發了無數工具來幫助完成此過程的每個步驟。














