看完這篇文章,別再說不會 Redis 的高級特性了
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲。轉載本文請聯系Java極客技術公眾號。
Redis 作為后端工程師必備的技能,阿粉每次面試的時候都會被問到,阿粉特意把公號前面發過的 Redis 系列文章整理出來成一篇,自己學習同時也幫助大家一起學習。
文章較長,建議先收藏再觀看。
Redis 的數據類型有哪些?
Redis 五種數據類型,每種數據類型都有相關的命令,幾種類型分別如下:
- String(字符串)
- List(列表)
- Hash(字典)
- Set(集合)
- Sorted Set(有序集合)
Redis 有五種常見的數據類型,每種數據類型都有各自的使用場景,通用的字符串類型使用最為廣泛,普通的 Key/Value 都是這種類型;列表類型使用的場景經常有粉絲列表,關注列表的場景;字典類型即哈希表結構,這個類型的使用場景也很廣泛,在各種系統里面都會用到,可以用來存放用戶或者設備的信息,類似于 HashMap 的結構;Redis set 提供的功能與列表類型類似也是一個列表的功能,區別是 Set 是去重的;有序集合功能與 Set 一樣,只不過是有順序的。
Redis 的內存回收與Key 的過期策略
Redis 內存過期策略
過期策略的配置
Redis 隨著使用的時間越來越長,占用的內存會越來越大,那么當 Redis 內存不夠的時候,我們要知道 Redis 是根據什么策略來淘汰數據的,在配置文件中我們使用 maxmemory-policy 來配置策略,如下圖
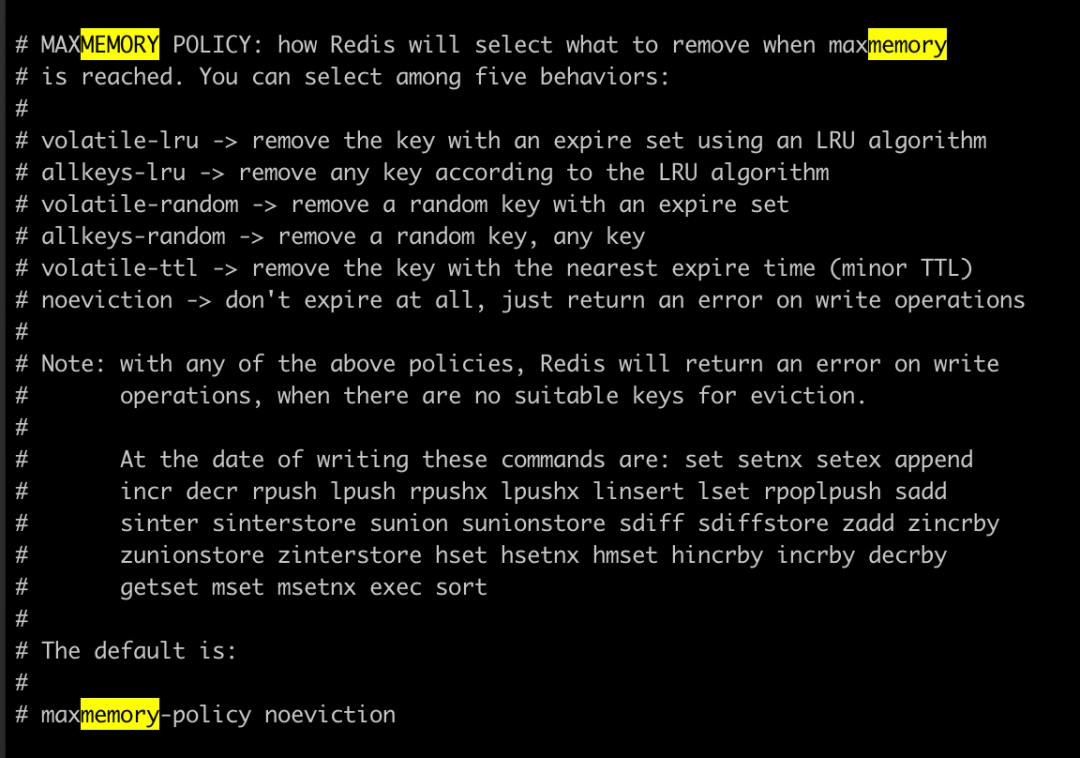
我們可以看到策略的值由如下幾種:
- volatile-lru: 在所有帶有過期時間的 key 中使用 LRU 算法淘汰數據;
- alkeys-lru: 在所有的 key 中使用最近最少被使用 LRU 算法淘汰數據,保證新加入的數據正常;
- volatile-random: 在所有帶有過期時間的 key 中隨機淘汰數據;
- allkeys-random: 在所有的 key 中隨機淘汰數據;
- volatile-ttl: 在所有帶有過期時間的 key 中,淘汰最早會過期的數據;
- noeviction: 不回收,當達到最大內存的時候,在增加新數據的時候會返回 error,不會清除舊數據,這是 Redis 的默認策略;
volatile-lru, volatile-random, volatile-ttl 這幾種情況在 Redis 中沒有帶有過期 Key 的時候跟 noeviction 策略是一樣的。淘汰策略是可以動態調整的,調整的時候是不需要重啟的,原文是這樣說的,我們可以根據自己 Redis 的模式來動態調整策略。”To pick the right eviction policy is important depending on the access pattern of your application, however you can reconfigure the policy at runtime while the application is running, and monitor the number of cache misses and hits using the Redis INFO output in order to tune your setup.“
策略的執行過程
- 客戶端運行命令,添加數據申請內存;
- Redis 會檢查內存的使用情況,如果已經超過的最大限制,就是根據配置的內存淘汰策略去淘汰相應的 key,從而保證新數據正常添加;
- 繼續執行命令。
近似的 LRU 算法
Redis 中的 LRU 算法不是精確的 LRU 算法,而是一種經過采樣的LRU,我們可以通過在配置文件中設置 maxmemory-samples 5 來設置采樣的大小,默認值為 5,我們可以自行調整。官方提供的采用對比如下,我們可以看到當采用數設置為 10 的時候已經很接近真實的 LRU 算法了。
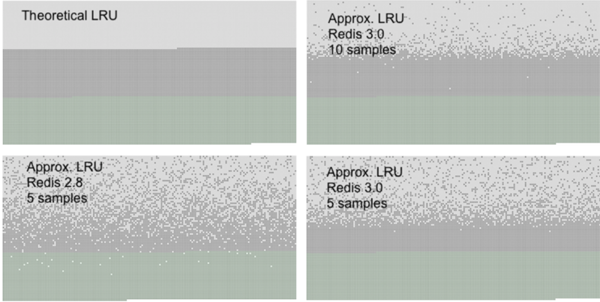
在 Redis 3.x 以上的版本的中做過優化,目前的近似 LRU 算法以及提升了很大的效率,Redis 之所以不采樣實際的 LRU 算法,是因為會耗費很多的內存,原文是這樣說的
The reason why Redis does not use a true LRU implementation is because it costs more memory.
Key 的過期策略
設置帶有過期時間的 key
前面介紹了 Redis 的內存回收策略,下面我們看看 Key 的過期策略,提到 Key 的過期策略,我們說的當然是帶有 expire 時間的 key,如下
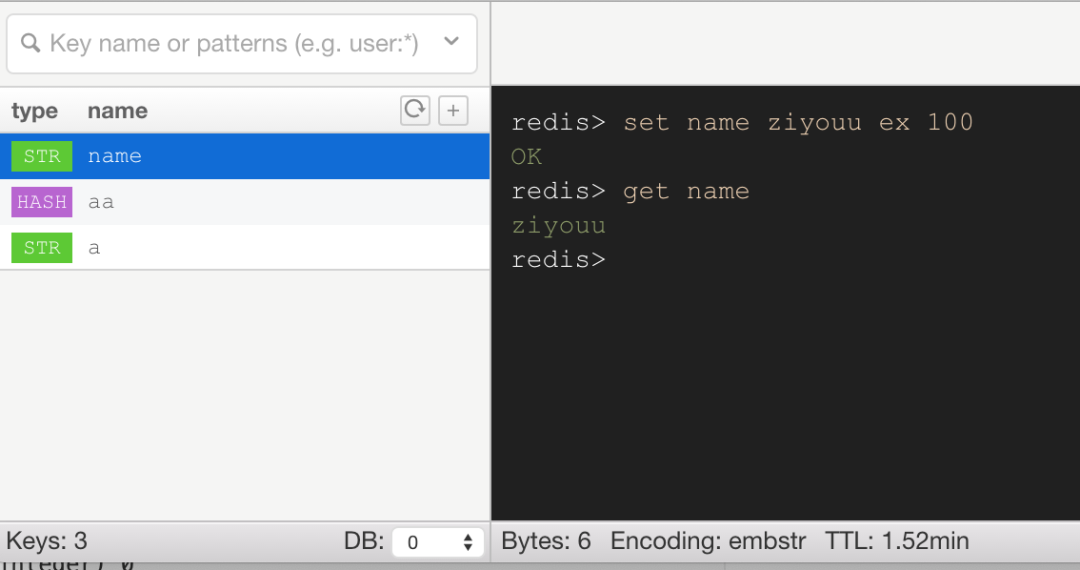
通過 redis> set name ziyouu ex 100 命令我們在 Redis 中設置一個 key 為 name,值為 ziyouu 的數據,從上面的截圖中我們可以看到右下角有個 TTL,并且每次刷新都是在減少的,說明我們設置帶有過期時間的 key 成功了。
Redis 如何清除帶有過期時間的 key
對于如何清除過期的 key 通常我們很自然的可以想到就是我們可以給每個 key 加一個定時器,這樣當時間到達過期時間的時候就自動刪除 key,這種策略我們叫定時策略。這種方式對內存是友好的,因為可以及時清理過期的可以,但是由于每個帶有過期時間的 key 都需要一個定時器,所以這種方式對 CPU 是不友好的,會占用很多的 CPU,另外這種方式是一種主動的行為。
有主動也有被動,我們可以不用定時器,而是在每次訪問一個 key 的時候再去判斷這個 key 是否到達過期時間了,過期了就刪除掉。這種方式我們叫做惰性策略,這種方式對 CPU 是友好的,但是對應的也有一個問題,就是如果這些過期的 key 我們再也不會訪問,那么永遠就不會刪除了。
Redis 服務器在真正實現的時候上面的兩種方式都會用到,這樣就可以得到一種折中的方式。另外在定時策略中,從官網我們可以看到如下說明
Specifically this is what Redis does 10 times per second:
- Test 20 random keys from the set of keys with an associated expire.
- Delete all the keys found expired.
- If more than 25% of keys were expired, start again from step 1.
意思是說 Redis 會在有過期時間的 Key 集合中隨機 20 個出來,刪掉已經過期的 Key,如果比例超過 25%,再重新執行操作。每秒鐘會執行 10 個這樣的操作。
Redis 的發布訂閱功能你知道嗎?
發布訂閱系統在我們日常的工作中經常會使用到,這種場景大部分情況我們都是使用消息隊列的,常用的消息隊列有 Kafka,RocketMQ,RabbitMQ,每一種消息隊列都有其特性。其實在很多時候我們可能不需要獨立部署相應的消息隊列,只是簡單的使用,而且數據量也不會太大,這種情況下,我們就可以考慮使用 Redis 的 Pub/Sub 模型。
使用方式
發布與訂閱
Redis 的發布訂閱功能主要由 PUBLISH,SUBSCRIBE,PSUBSCRIBE 命令組成,一個或者多個客戶端訂閱某個或者多個頻道,當其他客戶端向該頻道發送消息的時候,訂閱了該頻道的客戶端都會收到對應的消息。
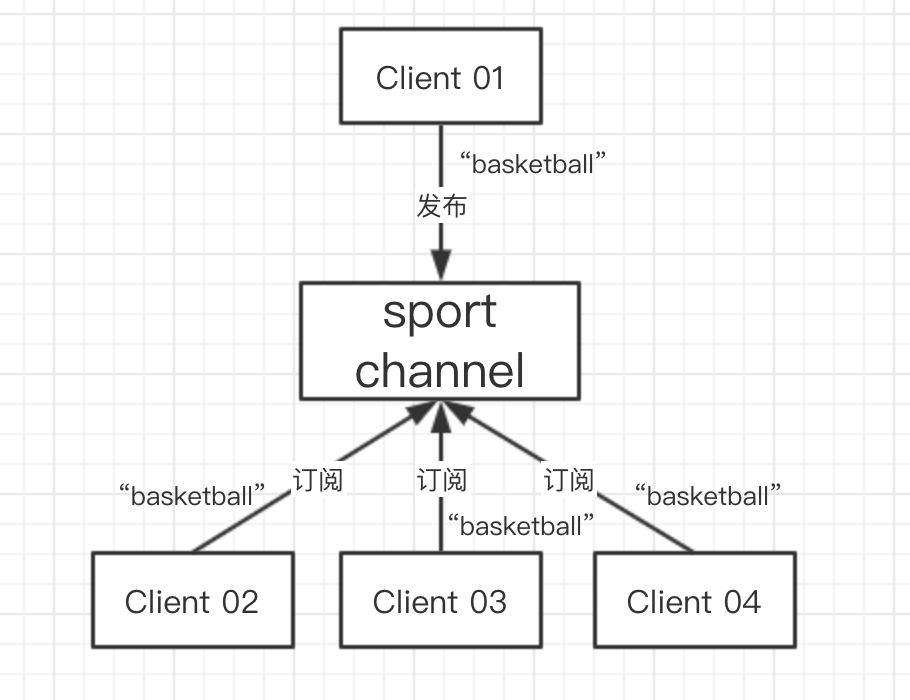
上圖中有四個客戶端,Client 02,Client 03,Client 04 訂閱了同一個Sport 頻道(Channel),這時當 Client 01 向 Sport Channel 發送消息 “basketball” 的時候,02-04 這三個客戶端都同時收到了這條消息。
整個過程的執行命令如下:
首先開四個 Redis 的客戶端,然后在 Client 02,Client 03,Client 04 中輸入subscribe sport 命令,表示訂閱 sport 這個頻道

然后在 Client 01 的客戶端中輸入publish sport basketball 表示向 sport 頻道發送消息 "basketball"
這個時候我們在去看下Client 02-04 的客戶端,可以看到已經收到了消息了,每個訂閱了這個頻道的客戶端都是一樣的。
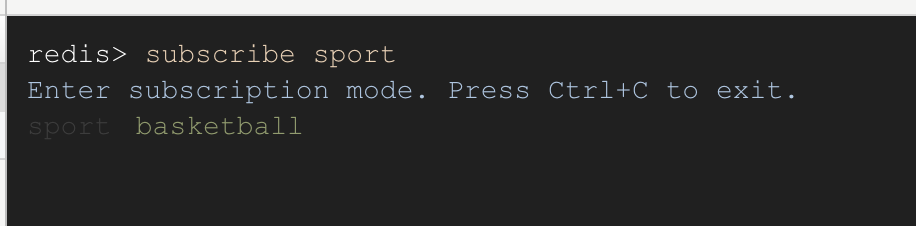
這里 Client 02-Client 04 三個客戶端訂閱了 Sport 頻道,我們叫做訂閱者(subscriber),Client 01 發布消息,我們叫做發布者(publisher),發送的消息就是 message。
模式訂閱
前面我們看到的是一個客戶端訂閱了一個 Channel,事實上單個客戶端也可以同時訂閱多個 Channel,采用模式匹配的方式,一個客戶端可以同時訂閱多個 Channel。
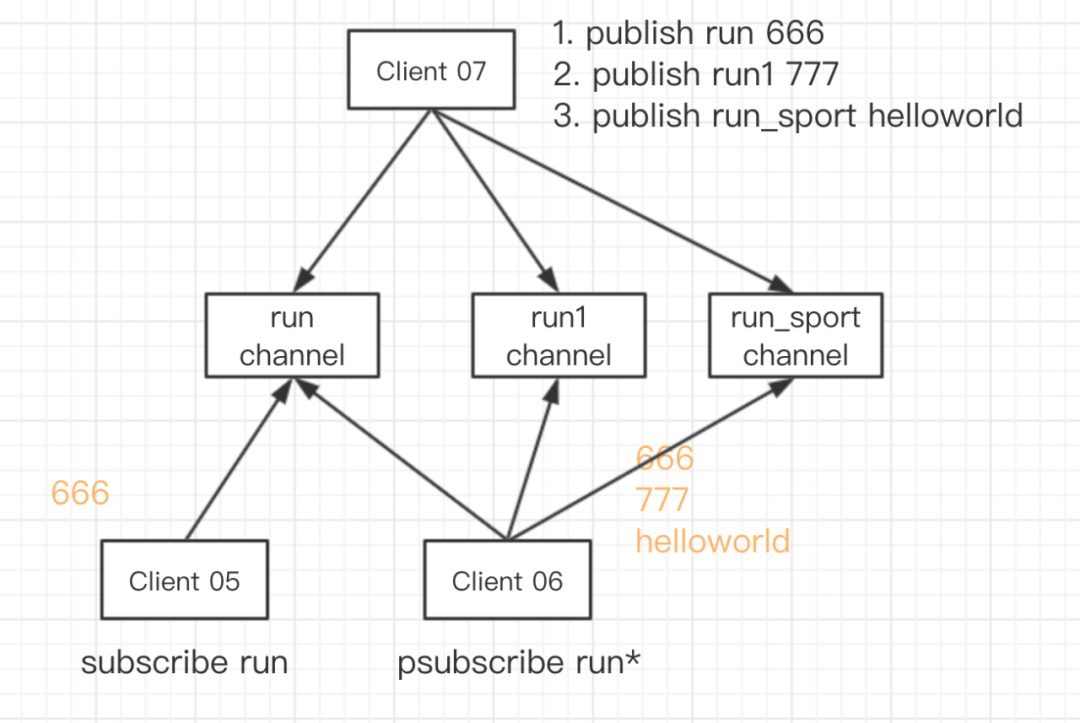
如上圖 Client 05 通過命令subscribe run 訂閱了 run 頻道,Client 06 通過命令psubscribe run* 訂閱了 run* 匹配的頻道。當 Client 07 向 run 頻道發送消息 666 的時候,05 和 06 兩個客戶端都收到消息了;接下來 Client 07 向 run1 和 run_sport 兩個頻道發送消息的時候,Client 06 依舊可以收到消息,而 Client 05 就收不到了消息了。
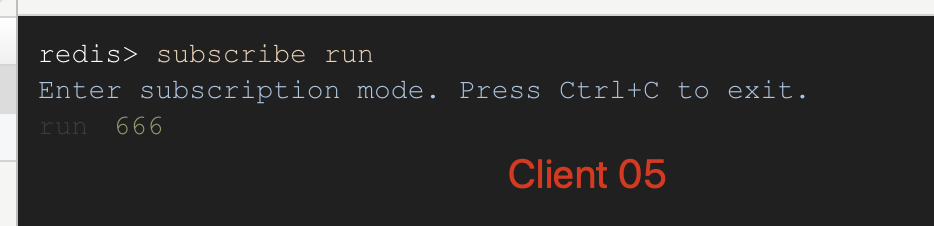
Client 05 訂閱run 頻道和接收到消息:
Client 06 訂閱run* 頻道和接收到消息:
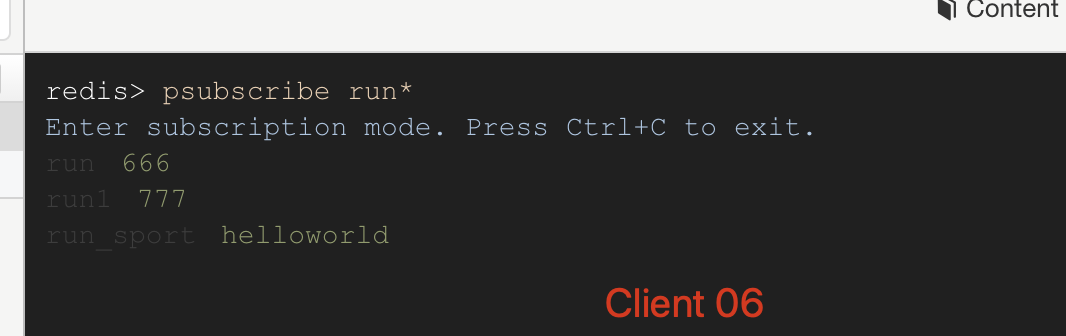
image-20191222141458065
Client 07 向多個頻道發送消息:
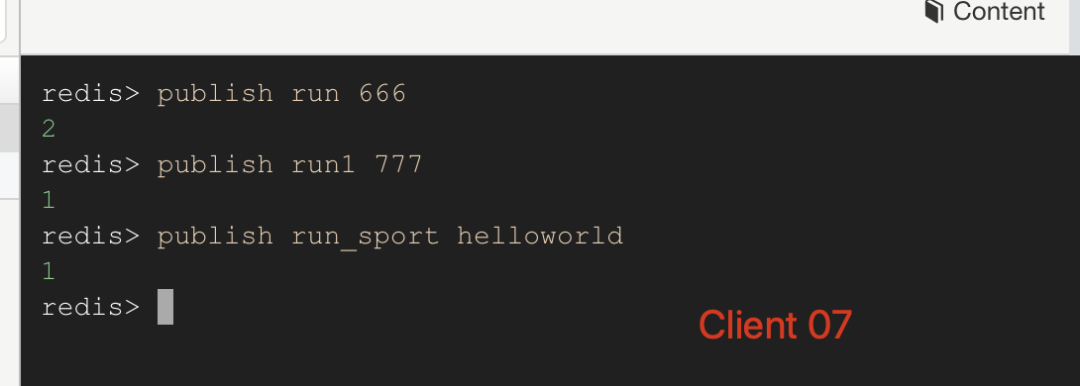
image-20191222141514914
通過上面的案例,我們學會了一個客戶端可以訂閱單個或者多個頻道,分別通過subscribe,psubscribe 命令,客戶端可以通過 publish 發送相應的消息。
在命令行中我們可以用 Ctrl + C 來取消相關訂閱,對應的命令時 unsubscribe channelName。
Pub/Sub 底層存儲結構
訂閱 Channel
在 Redis 的底層結構中,客戶端和頻道的訂閱關系是通過一個字典加鏈表的結構保存的,形式如下:
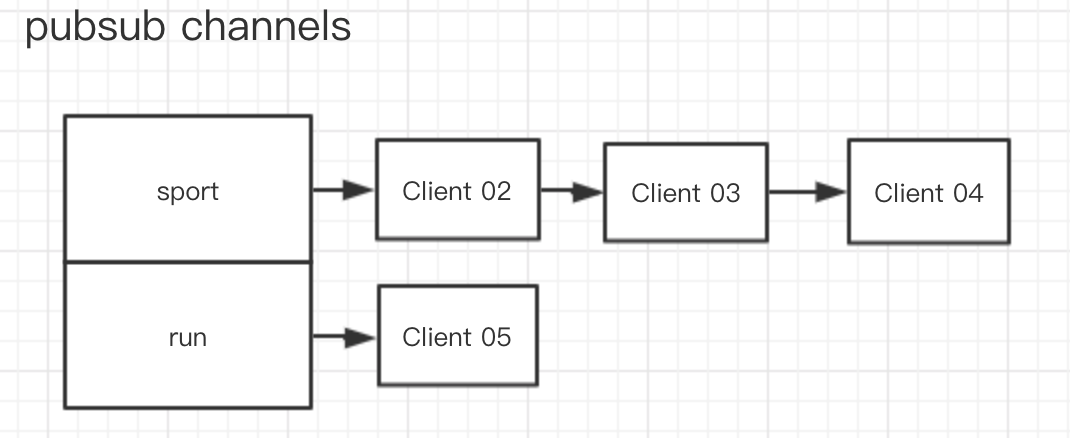
在 Redis 的底層結構中,Redis 服務器結構體中定義了一個 pubsub_channels 字典
- struct redisServer {
- //用于保存所有頻道的訂閱關系
- dict *pubsub_channels;
- }
在這個字典中,key 代表的是頻道名稱,value 是一個鏈表,這個鏈表里面存放的是所有訂閱這個頻道的客戶端。
所以當有客戶端執行訂閱頻道的動作的時候,服務器就會將客戶端與被訂閱的頻道在 pubsub_channels 字典中進行關聯。
這個時候有兩種情況:
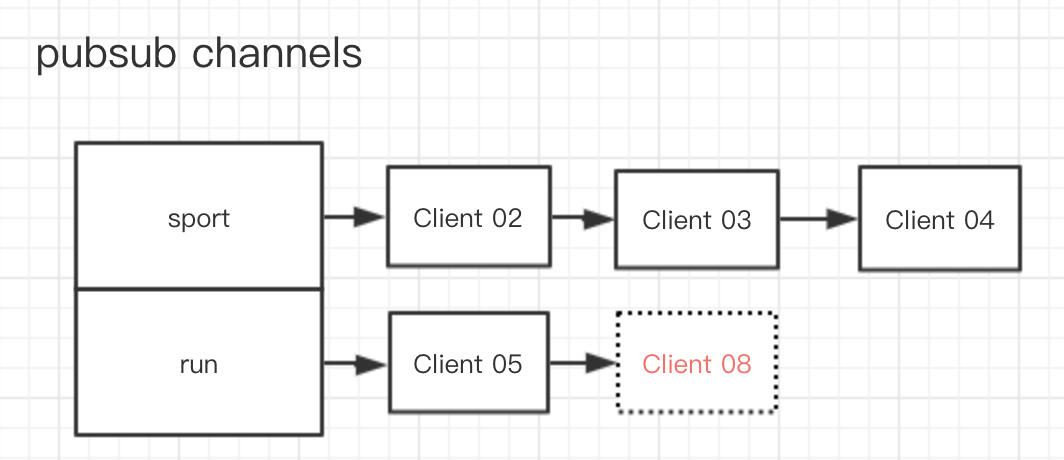
- 該渠道是首次被訂閱:首次被訂閱說明在字典中并不存在該渠道的信息,那么程序首先要創建一個對應的 key,并且要賦值一個空鏈表,然后將對應的客戶端加入到鏈表中。此時鏈表只有一個元素。
- 該渠道已經被其他客戶端訂閱過:這個時候就直接將對應的客戶端信息添加到鏈表的末尾就好了。
比如,如果有一個新的客戶端 Client 08 要訂閱 run 渠道,那么上圖就會變成
如果 Client 08 要訂閱一個新的渠道 new_sport ,那么就會變成
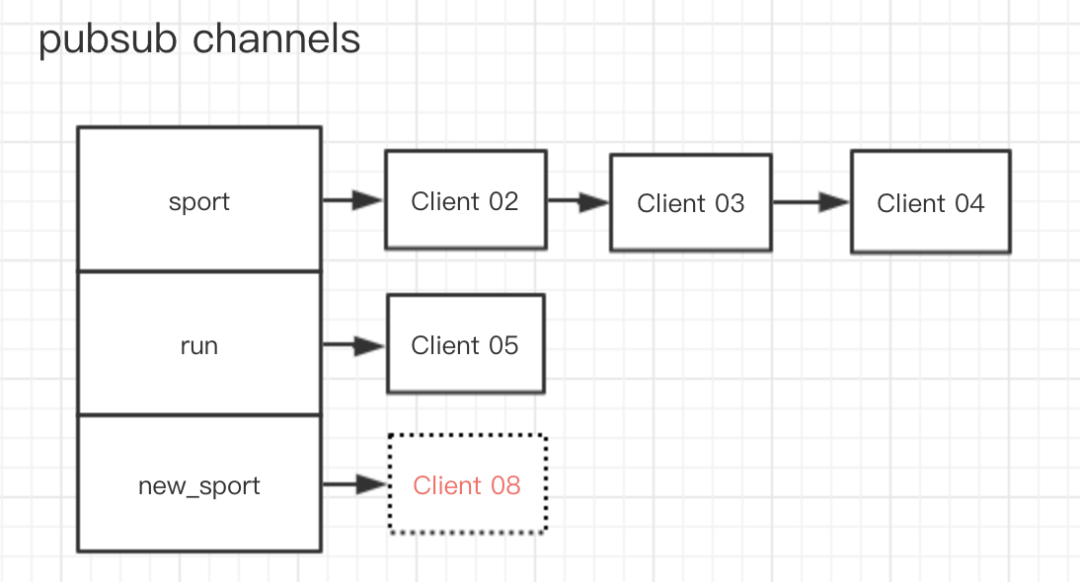
image-20191222161558999
整個訂閱的過程可以采用下面偽代碼來實現
- Map<String, List<Object>> pubsub_channels = new HashMap<>();
- public void subscribe(String[] subscribeList, Object client) {
- //遍歷所有訂閱的 channel,檢查是否在 pubsub_channels 中,不在則創建新的 key 和空鏈表
- for (int i = 0; i < subscribeList.length; i++) {
- if (!pubsub_channels.containsKey(subscribeList[i])) {
- pubsub_channels.put(subscribeList[i], new ArrayList<>());
- }
- pubsub_channels.get(subscribeList[i]).add(client);
- }
- }
取消訂閱
上面介紹的是單個 Channel 的訂閱,相反的如果一個客戶端要取消訂閱相關 Channel,則無非是找到對應的 Channel 的鏈表,從中刪除對應的客戶端,如果該客戶端已經是最后一個了,則將對應 Channel 也刪除。
- public void unSubscribe(String[] subscribeList, Object client) {
- //遍歷所有訂閱的 channel,依次刪除
- for (int i = 0; i < subscribeList.length; i++) {
- pubsub_channels.get(subscribeList[i]).remove(client);
- //如果長度為 0 則清楚 channel
- if (pubsub_channels.get(subscribeList[i]).size() == 0) {
- remove(subscribeList[i]);
- }
- }
- }
模式訂閱結構
模式渠道的訂閱與單個渠道的訂閱類似,不過服務器是將所有模式的訂閱關系都保存在服務器狀態的pubsub_patterns 屬性里面。
- struct redisServer{
- //保存所有模式訂閱關系
- list *pubsub_patterns;
- }
與訂閱單個 Channel 不同的是,pubsub_patterns 屬性是一個鏈表,不是字典。節點的結構如下:
- struct pubsubPattern{
- //訂閱模式的客戶端
- redisClient *client;
- //被訂閱的模式
- robj *pattern;
- } pubsubPattern;
其實 client 屬性是用來存放對應客戶端信息,pattern 是用來存放客戶端對應的匹配模式。
所以對應上面的 Client-06 模式匹配的結構存儲如下
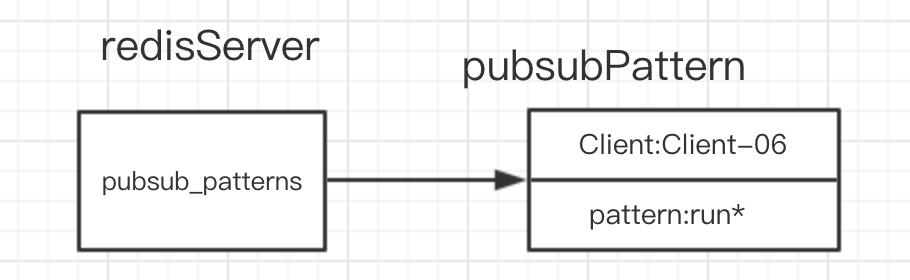
image-20191222174528367
在pubsub_patterns鏈表中有一個節點,對應的客戶端是 Client-06,對應的匹配模式是run*。
訂閱模式
當某個客戶端通過命令psubscribe 訂閱對應模式的 Channel 時候,服務器會創建一個節點,并將 Client 屬性設置為對應的客戶端,pattern 屬性設置成對應的模式規則,然后添加到鏈表尾部。
對應的偽代碼如下:
- List<PubSubPattern> pubsub_patterns = new ArrayList<>();
- public void psubscribe(String[] subscribeList, Object client) {
- //遍歷所有訂閱的 channel,創建節點
- for (int i = 0; i < subscribeList.length; i++) {
- PubSubPattern pubSubPattern = new PubSubPattern();
- pubSubPattern.client = client;
- pubSubPattern.pattern = subscribeList[i];
- pubsub_patterns.add(pubSubPattern);
- }
- }
- 創建新節點;
- 給節點的屬性賦值;
- 將節點添加到鏈表的尾部;
退訂模式
退訂模式的命令是punsubscribe,客戶端使用這個命令來退訂一個或者多個模式 Channel。服務器接收到該命令后,會遍歷pubsub_patterns鏈表,將匹配到的 client 和 pattern 屬性的節點給刪掉。這里需要判斷 client 屬性和 pattern 屬性都合法的時候再進行刪除。
偽代碼如下:
- public void punsubscribe(String[] subscribeList, Object client) {
- //遍歷所有訂閱的 channel 相同 client 和 pattern 屬性的節點會刪除
- for (int i = 0; i < subscribeList.length; i++) {
- for (int j = 0; j < pubsub_patterns.size(); j++) {
- if (pubsub_patterns.get(j).client == client
- && pubsub_patterns.get(j).pattern == subscribeList[i]) {
- remove(pubsub_patterns);
- }
- }
- }
- }
遍歷所有的節點,當匹配到相同 client 屬性和 pattern 屬性的時候就進行節點刪除。
發布消息
發布消息比較好容易理解,當一個客戶端執行了publish channelName message 命令的時候,服務器會從pubsub_channels和pubsub_patterns 兩個結構中找到符合channelName 的所有 Channel,進行消息的發送。在 pubsub_channels 中只要找到對應的 Channel 的 key 然后向對應的 value 鏈表中的客戶端發送消息就好。
Redis 的持久化你了解嗎
持久化是將程序數據在持久狀態和瞬時狀態間轉換的機制。通俗的講,就是瞬時數據(比如內存中的數據,是不能永久保存的)持久化為持久數據(比如持久化至數據庫中,能夠長久保存)。另外我們使用的 Redis 之所以快就是因為數據都存儲在內存當中,為了保證在服務器出現異常過后還能恢復數據,所以就有了 Redis 的持久化,Redis 的持久化有兩種方式,一種是快照形式 RDB,另一種是增量文件 AOF。
RDB
RDB 持久化方式是會在一個特定的時間間隔里面保存某個時間點的數據快照,我們拿到這個數據快照過后就可以根據這個快照完整的復制出數據。這種方式我們可以用來備份數據,把快照文件備份起來,傳送到其他服務器就可以直接恢復數據。但是這只是某個時間點的全部數據,如果我們想要最新的數據,就只能定期的去生成快照文件。
RDB 的實現主要是通過創建一個子進程來實現 RDB 文件的快照生成,通過子進程來實現備份功能,不會影響主進程的性能。同時上面也提到 RDB 的快照文件是保存一定時間間隔的數據的,這就會導致如果時間間隔過長,服務器出現異常還沒來得及生成快照的時候就會丟失這個間隔時間的所有數據;那有同學就會說,我們可以把時間間隔設置的短一點,適當的縮短是可以的,但是如果間隔時間段設置短一點頻繁的生成快照對系統還是會有影響的,特別是在數據量大的情況下,高性能的環境下是不允許這種情況出現的。
我們可以在 redis.conf 進行 RDB 的相關配置,配置生成快照的策略,以及日志文件的路徑和名稱。還有定時備份規則,如下圖所示,里面的注釋寫的很清楚,簡單說就是在多少時間以內多少個 key 變化了就會觸發快照。如save 300 10 表示在 5 分鐘內如果有 10 個 key 發生了變化就會觸發生產快照,其他的同理。
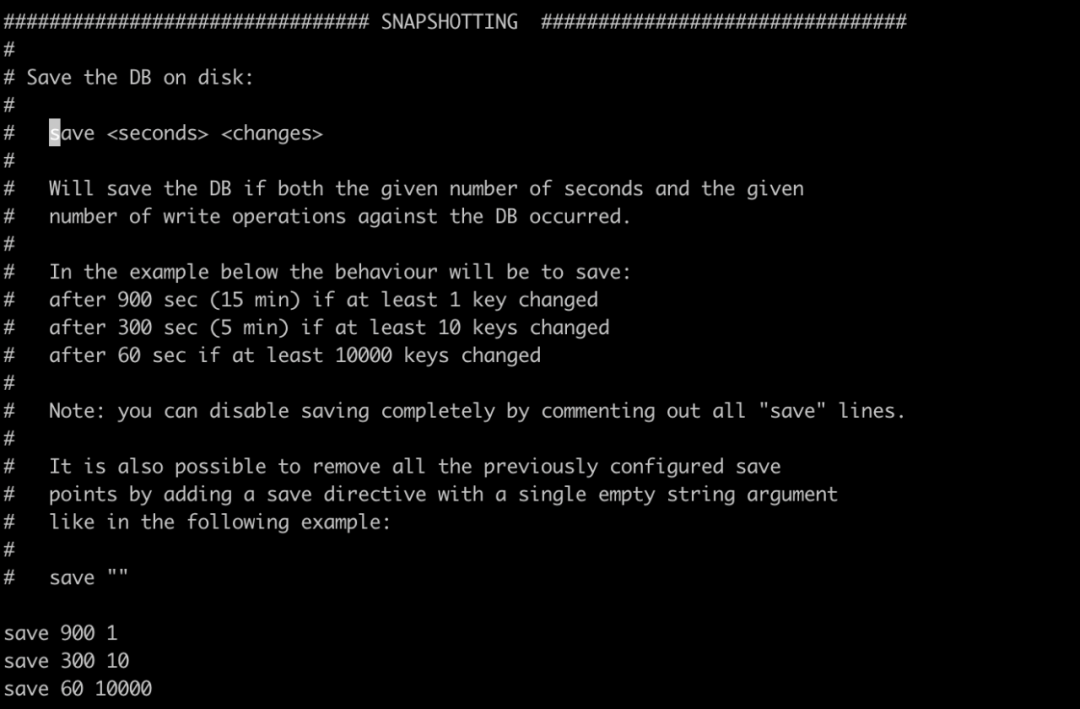
除了我們在配置文件中配置自動生成快照文件之外,Redis 本身提供了相關的命令可以讓我們手動生成快照文件,分別是 SAVE 和 BGSAVE ,這兩個命令功能相同但是方式和效果不一樣,SAVE 命令執行完后阻塞服務器進程,阻塞過后服務器就不能處理任何請求,所以在生產上不能用,和SAVE 命令直接阻塞服務器進程的做法不同,BGSAVE 命令是生成一個子進程,通過子進程來創建 RDB 文件,主進程依舊可以處理接受到的命令,從而不會阻塞服務器,在生產上可以使用。
阿粉在這里測試一下自動生成快照,我們修改一下快照的生成策略為save 10 2,然后在本地啟動Redis 服務,并用 redis-cli 鏈接進入,依次步驟如下
1.修改配置,如下

2.啟動 Redis 服務,我們可以從啟動日志中看到,默認是會先讀取 RDB 文件進行恢復的
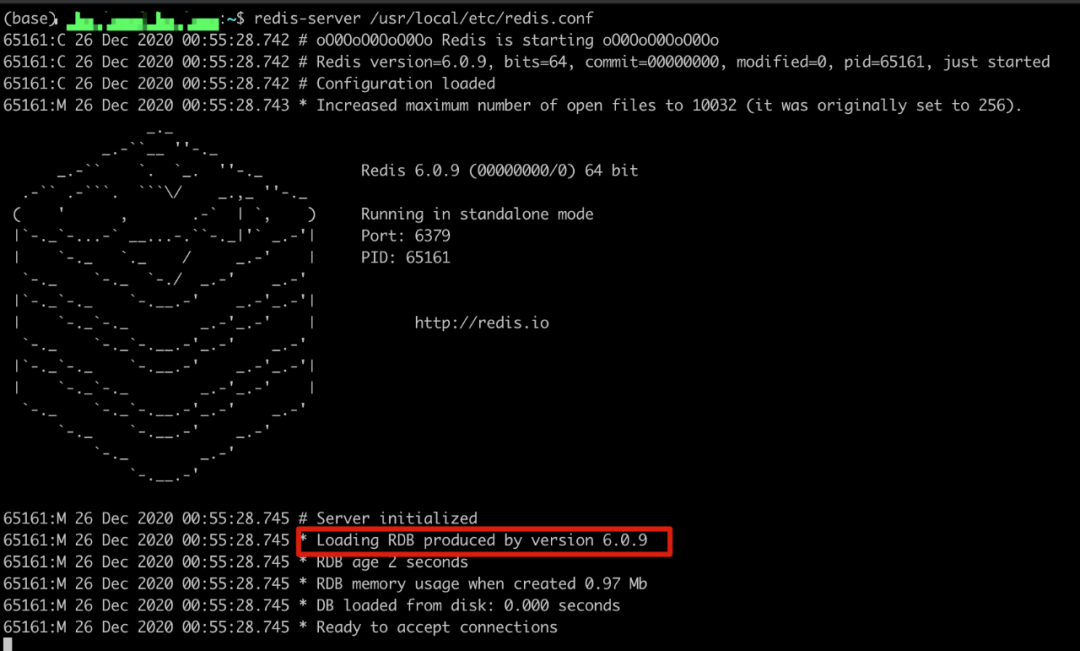
3.
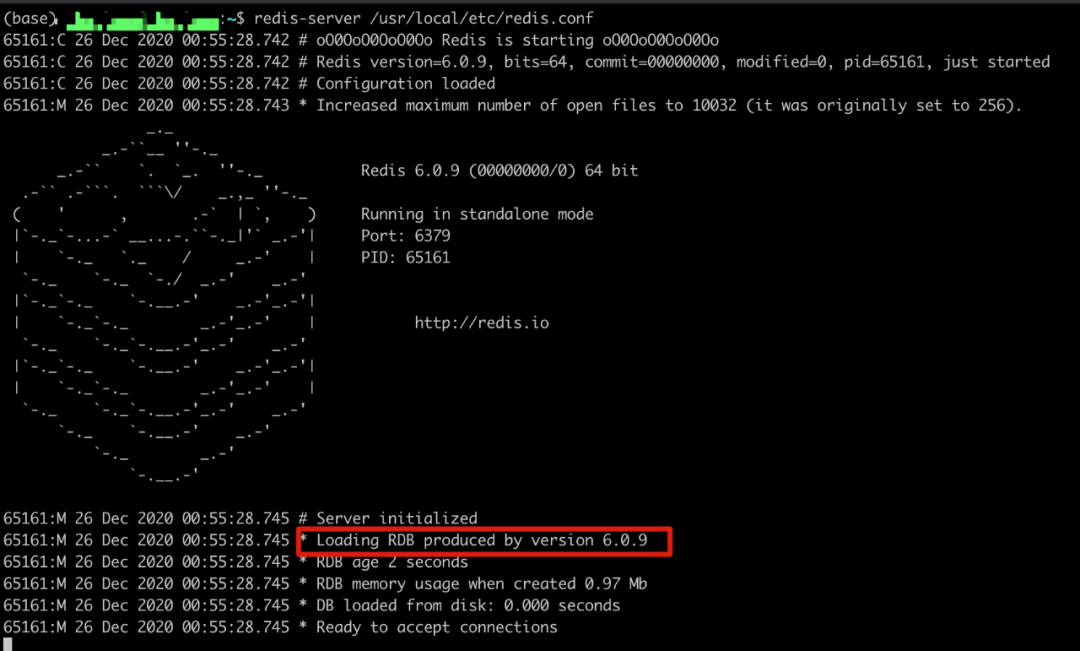
4.鏈接 Redis 服務,并在 10s 內設置 3 個 key
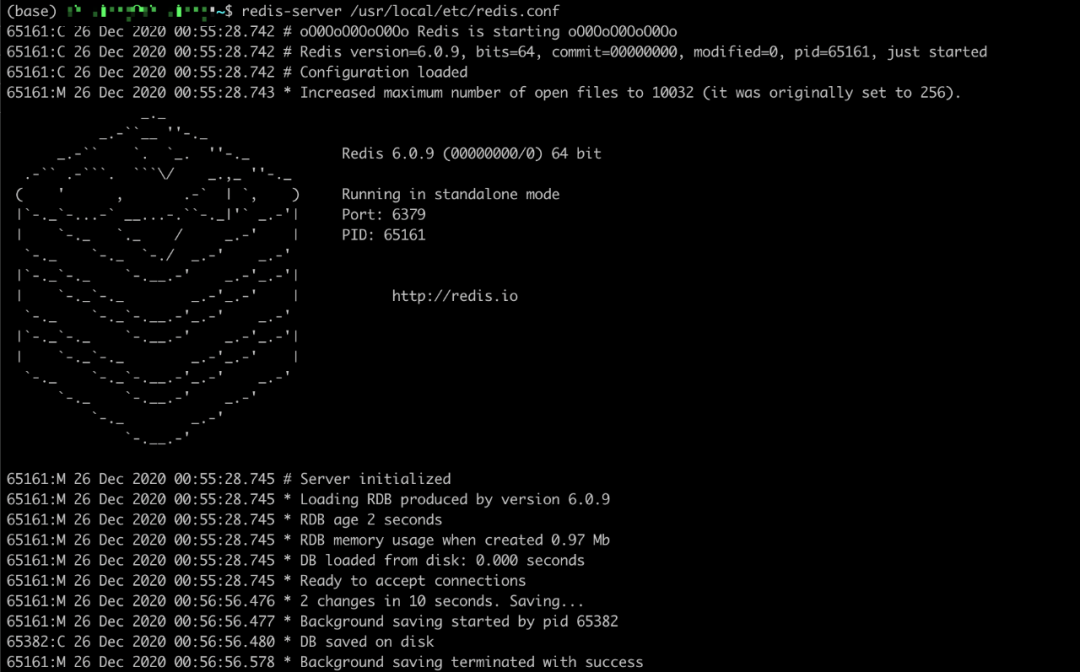
5.這個時候我們會看到 Redis 的日志里面會輸出下面內容,因為觸發了規則,所以開啟子進程進行數據備份,同時在對應的文件路徑下面,我們也看到了 rdb 文件。
6.
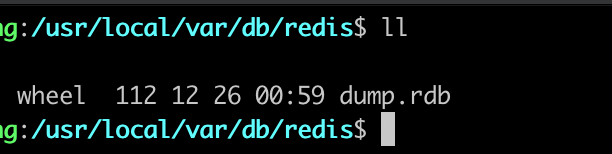
從上面可以看出,我們配置的規則生效了,也成功的生成了 RDB 文件, 后續在服務器出現異常的情況,只要重新啟動就會讀取對應的 RDB 文件進行數據備份。
AOF
AOF 是一種追加執行命令的形式,它跟 RDB 的區別是,AOF 并不是把數據保存下來,而是保存執行的動作。在開啟 AOF 功能的時候,客戶端連接后執行的每一條命令都會被記錄下來。這其實讓阿粉想起來的 MySQL 的 binlog 日志,也是記錄操作的命令,后續可以根據文件去恢復數據。
AOF 是追加命令格式的文件,同樣的我們可以定義多長時間把數據同步一次,Redis 本身提供了三種策略來實現命令的同步,分別是不進行同步,每秒同步一次,以及當有查詢的時候同步一次。默認的策略也是使用最多的策略就是每秒同步一次,這樣我們可以知道,丟失的數據最多也就只有一秒鐘的數據。有了這種機制,AOF 會比 RDB 可靠很多,但是因為文件里面存在的是執行的命令,所以AOF 的文件一般也會比 RDB 的文件大點。
Redis 的 AOF 功能,默認是沒有開啟的,我們可以通過在配置文件中配置appendonly yes 是功能開啟,同時配置同步策略appendfsync everysec 開啟每秒鐘同步一次,我們拿到 AOF 文件過后,可以根據這個文件恢復數據。
同樣的我們在redis.conf 中可以看到默認是沒有開啟 AOF 功能的,并且我們也可以指定對應的文件名稱和路徑。
接下來,我們測試一下開啟 AOF 功能,先修改配置然后重啟 Redis 的服務器,我們會發現已經沒有讀取 RDB 文件的日志了,并且在日志文件路徑下面已經生成了一個 aof 文件。需要注意的是,因為我們重啟的服務,并且開啟了 AOF,所以現在 Redis 服務器里面并沒有我們之前添加的數據(說明什么問題呢?)。
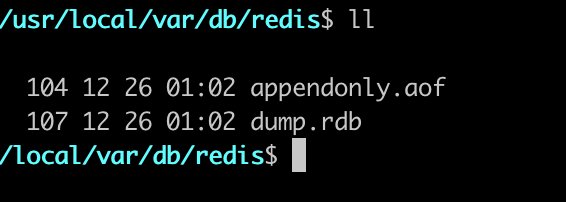
接下來我們使用客戶端連接進入,設置如下值,接下來我們可以看看 aof 文件里面的內容
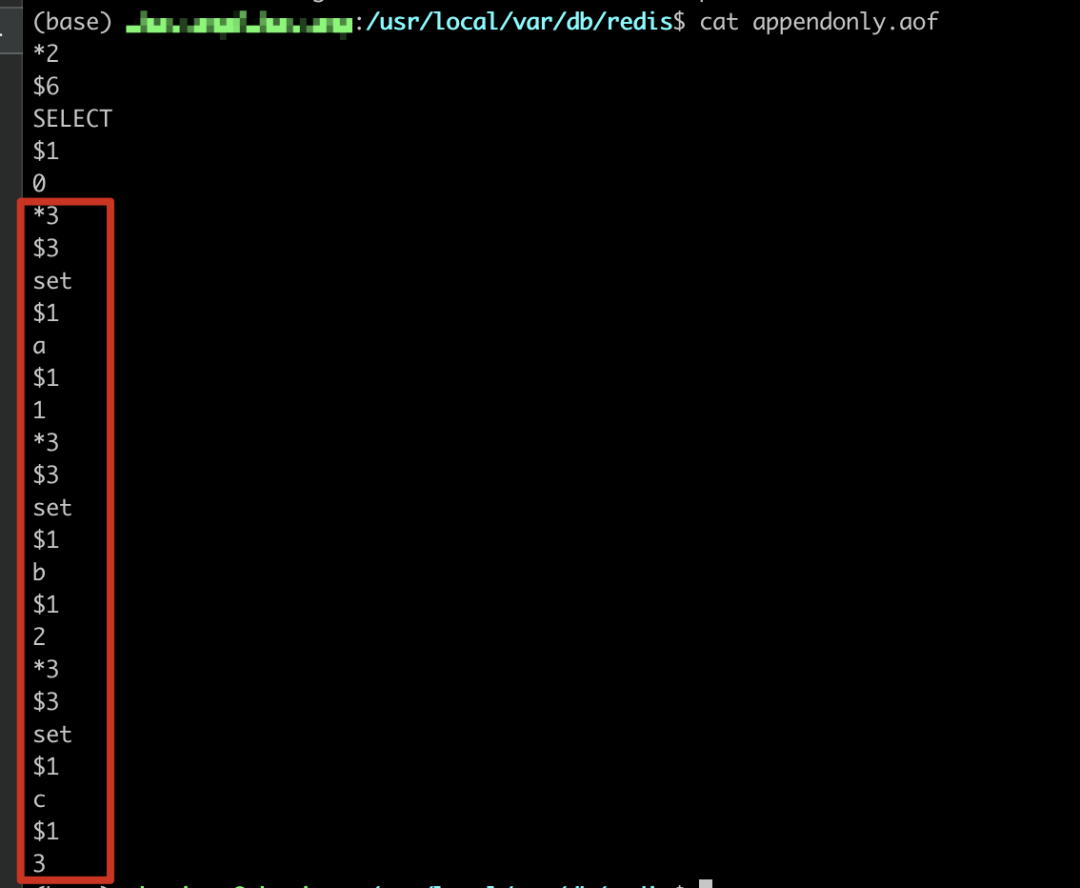
我們可以看到aof 文件里面的內容就是執行的命令,只不過是以一種固定的格式存儲的,我們在備份的時候如果不需要哪些數據,可以手動刪掉對應的命令就可以重新備份數據。
Redis 的有幾種集群模式
雖然說單機 Redis 理論上可以達到 10 萬并發而且也可以進行持久化,但是在生產環境中真正使用的時候,我相信沒有哪個公司敢這樣使用,當數據量達到一定的規模的時候肯定是要上 Redis 集群的。
Redis 的模式有主從復制模式,哨兵模式以及集群模式,這三種模式的涉及到篇幅內容會比較多,阿粉后面會單獨寫一篇文章來介紹,感興趣的小伙伴可以先自己學習下。