MySQL數據實時克隆的初步設計
之前我們重點建設了數據克隆的一個服務,其實起這個名字也琢磨了好久,說邏輯備份恢復很多業務同學都不大能理解,GET到我們要解決的問題,而數據克隆的概念就比較清晰。
先來說說我們對數據克隆的定義

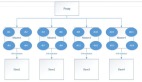
1)數據克隆快速從線上導出指定庫/表數據,并構建虛擬環境,從而來提供高效的數據服務;
2)功能方面實現了業務自助提取數據,分鐘級構建環境,可以通過workbench等工具訪問數據,無需DBA介入;
3)安全方面支持數據庫操作日志審計,已接入ES審計,并提供了庫/表訪問過濾,虛擬環境隨機分配,臨時密碼交付,同時限定了虛擬環境的使用時長。
適用場景:
1)線上配置數據的快速查看;
2)提取線上表結構;
3)日志數據查詢,線上大表;
4)線上SQL異常,快速構建虛擬環境進行SQL優化,壓測等;
5)指定大表的變更和數據操作影響評估;
6)數據補丁合并,基于業務邏輯的數據操作和數據補丁整理。
而從數據克隆的使用來看,其實能夠滿足一些不確定的需求,比如做一些全量的查詢過濾等,但是因為是和線上環境隔離的,所以就不會同步線上的數據,在這一點上可以更進一步,那就是落地實時數據克隆,從而能夠實現實時的數據同步,當然這種同步是一種多源冪等復制,打個比方,源庫有10張表,我們的目標環境可能只克隆了2張表,那么在做實時復制時,就需要排除那8張表,而且同一個實例上面有多套環境,所以會自然開啟多源復制模式。
如果排除一些瑣碎的細節,我們可以概括為:實時克隆的核心是對于GTID_SET的管理,在設計上需要考慮如下的一些因素:
基礎限定和配置
1. 同一個實例的數據庫只能克隆一次
2. 數據開啟GTID,實時克隆暫不支持MySQL 5.5版本
3. 數據庫參數slave_exec_mode值為IDEMPOTENT
4. 設置數據庫參數skip-slave-errors=1146
5. 實時克隆環境建議為只讀
6. 克隆的數據庫復制賬號為db_clone_repl
7. 通常克隆環境的表數量小于源庫環境
GTID變更流程
1. 數據邏輯備份時,需要包含GTID值,并記錄到導出記錄中
2. 數據邏輯恢復時,可以參考如下的步驟:
a) 如果已有數據復制通道運行
i. 暫停復制通道Channel
ii. 得到固定的GTID_SET值
iii. 追加導出的GTID至GTID_SET,并更新至GTID_PURGED
iv. 啟動復制通道Channel
b) 如果沒有數據復制通道運行
i. 追加導出的GTID至當前GTID_SET,并更新至GTID_PURGED
ii. 啟動復制通道Channel
注:復制通道Channel的命名為db_clone_【源IP】_【源端口】
3. 每天的定時任務清理環境時,自動執行reset master操作清空GTID_SET
本文轉載自微信公眾號「楊建榮的學習筆記」,可以通過以下二維碼關注。轉載本文請聯系楊建榮的學習筆記公眾號。