2020年,這個算法團隊都干了啥?
寫在最前
我個人有寫年度總結的習慣,2020年我的工作職責有所變化,從垂直方向的廣告算法變化到了水平橫向的算法整體,所以這篇總結是關于阿里巴巴國際站(Alibaba.com,簡稱ICBU)算法團隊的。本文內容主要包括以下幾個部分:
- 第一部分,分享我對算法、電商算法的理解,以及ICBU算法團隊的整體工作。
- 第二部分,ICBU算法團隊在2020年的一些重要技術突破。
- 第三部分,關于工作中一些開放性問題的思考。
- 第四部分,明年的展望。
一 ICBU算法團隊簡介
當年在做廣告算法的時候,我曾經想過一個問題,“什么是廣告算法工程師”?當時我從廣告、廣告算法、廣告算法工程師這3個維度,分別闡述了這個問題。而現在,隨著職責的變化,我問自己的問題就變成了,“什么是算法工程師?”
1 算法
什么是算法?當我們提到《算法導論》這本書的時候,當我們給一個面試候選人出了一道“算法題”的時候,當我們提到“區塊鏈算法”的時候,我們所說的算法,可能指的是排序算法、遞歸算法、隨機算法、加密算法等等。這些“算法”,未必是我們現在“算法工程師”們日常工作中的最主要的內容,這其中有一些“算法”,是所有程序員必備的基礎知識;而另外一些“算法”,似乎是算法工程師們所專有的。“算法(Algorithms)”這個概念太模糊,以至于不會有一個清晰的內涵和外延。
假如“算法”這個概念本身不那么清晰,那么“算法工程師”又是如何定義的呢?在國外,比如硅谷,是沒有“算法工程師”這樣的概念的,那里有數據科學家(Data Scientist)、應用科學家(Applied Scientist)、AI工程師(AI Engineer)、機器學習工程師(Machine Learning Engineer),唯獨沒有“Algorithm Engineer”這樣的職位。
在國內互聯網公司,最常見的對于“算法工程師”的定義,有兩種:
- 工具視角:以“機器學習(或優化)”等技術為日常工作主要工具的工程師,稱為算法工程師。就好比說,以“錛鑿斧鋸”為日常工作主要工具的工程師,我們稱之為“木匠”一樣,這種定義類似于Machine Learning Engineer。
- 目的視角:以“優化某可量化業務指標”為日常工作主要目的的工程師,稱為算法工程師。就好比說,以“制作一個木質家具”為日常工作主要目的的工程師,我們稱之為“木匠”一樣,這種定義類似于“指標優化工程師”。
兩種定義的視角,無所謂對錯,但是會塑造出不一樣的算法工程師。“工具視角”下的算法工程師,對于“工具”的使用熟練程度可能會比較高,但是可能會缺少業務感和目的感,缺少全棧化的能力和意愿;而“目的視角”下的算法工程師,與前者相反,有不錯的業務感和目的感,大多數有不錯的全棧化能力和意愿,但是對于“工具”的使用熟練程度未必那么高。
(PS:“目的視角”下的算法工程師的定義,引發了另外一個問題:假如說以“優化某可量化業務指標”為日常工作主要目的的工程師,是算法工程師,那么非算法崗位的其他開發工程師,是否就不關心或者說不能優化業務指標了呢?答案當然是否定的,本文就不詳細展開討論了。)
2 電商算法
阿里的算法工程師有很大一部分是服務于電商業務的,說說我對于“電商算法”的理解:
我們認為,電商算法的主要工作,都圍繞著“分配(Allocation)”二字展開,要么是“分配”本身,比如對于外投營銷預算、銷售傭金、廣告主的P4P預算和運營紅包的分配、對于銷售、拍檔和運營的時間精力的分配、對于買家的注意力(商機)的分配;要么就是為了更好地“分配”而做的基建或準備工作,比如對電商核心要素的數據標準化、對于視頻和直播等內容更深入的理解、對于分配過程中作弊行為的識別和打擊。
根據資源“分配”過程本身市場化程度的高低、分配過程中人為主觀因素的重要程度、被分配資源的規模量級、分配所造成的業務影響的即時性、分配對于實時性的要求,演化出了對算法團隊不同的要求:
- 從以市場經濟為主體,算法以中立(neutral)身份參與分配過程的方式到以宏觀調控為主體,算法主動干預分配過程的方式。
- 從組合和最優化類的算法問題到機器學習類的算法問題。
- 從以模型預測精準度為目標的有監督學習任務到以長期和全局的收益(reward)最大化為目標的強化學習任務。
- 從基于強可解釋性要求的樹模型算法到基于弱可解釋性的深度神經網絡模型算法。
- 從離線的算法建模工作到提供在線實時化的算法產品化的服務。
- 從單目標優化的算法問題到多目標帶約束優化的算法問題。
豐富多彩的應用場景,孕育了各種各樣的問題定義,不同的問題定義又催生出了不同的算法方案以及對于算法同學能力的不同要求。
效率和公平是衡量“分配”是否是“好分配”的兩個重要維度,通常來說,在分配效率還很低的時候,算法的關注點與優化的重點都在效率提升方面,對于“公平”還不會考慮太多,而一旦效率提升到接近天花板的水平之后,“公平”問題開始浮出水面,應該引起算法更多的重視。如何量化“效率和公平(尤其是公平)”不僅僅是算法問題,更涉及到道德倫理、經濟學、博弈論、數據科學等交叉學科,可以說是電商算法領域最復雜最核心的問題,甚至受到了人民日報[2]的關注。
3 ICBU算法
先從一張所謂的“算法大圖”開始:
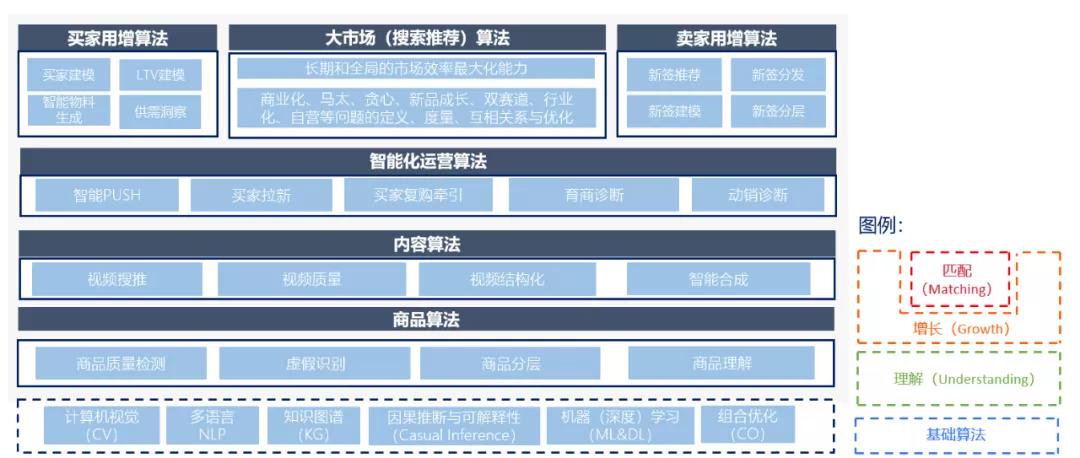
ICBU算法團隊,隸屬于ICBU技術部,服務于ICBU業務。它的整體工作,從上面算法大圖的視角來看,可以分為3大部分:理解(Understanding)、增長(Growth)和匹配(Matching),它們也分別對應了Market Place的“貨、人、場”三個部分:
理解(Understanding)
指的是基于計算機視覺(CV)、自然語言處理(NLP)、深度學習(Deep Learning)、數據標準化(Data Standardization)和知識圖譜(Knowledge Graph)等基礎算法能力,打造整個業務的數字化基建底盤,提升我們對于商品(貨)、內容(短視頻和直播)、買賣家、行業趨勢、市場供需等方面的理解,提升商品、內容和商家的數字化程度,并基于這些理解去賦能增長和匹配的環節,降本增效。
增長(Growth)
指的是在固定資源成本約束下,通過算法對于資源的最優化分配,來實現電商業務核心要素的買賣家(人)最大化增長,根據所分配資源的不同,可以分成三個方面:
- 第一方面(狹義理解的)買家增長,主要是基于組合優化、趨勢發現(forecasting)、最優化(Optimization)、對抗智能等基礎算法能力,來最優化分配外投的市場預算,實現固定預算的情況下的業務價值(LTV/AB)最大化。
- 第二方面,賣家增長,主要是基于數據驅動、機器學習、統計建模、因果推斷(Casual Inference)等基礎算法能力,來最優化分配銷售和拍檔的時間與精力,實現有限銷售和拍檔規模的情況下,新簽、續簽的會員費營收最大化。
- 第三方面,智能運營,基于算法賦能,最優化分配運營的精力、買賣家運營紅包和免服務費等運營權益,實現支付買家數、訂單數、GMV和供應鏈營收的最大化。
匹配(Matching)
指的是在包括搜索、推薦和廣告在內的大市場,完成買賣家的高效撮合匹配。主要是基于機器學習、最優化和E&E等基礎算法能力,在最大化市場長期和全局的匹配效率,追求有效商機極大產出(AB/Pay/GMV)的同時,實現商機在自然品和廣告品之間的合理分配(商業化問題)、商機在首次商機和往復商機之間的合理分配(貪心問題)、商機在頭部商家和尾部商家之間的合理分配(馬太問題)、商機在新品和爆品之間的合理分配(新品成長問題)、商機在RTS品和詢盤品之間的合理分配(雙賽道問題)、商機在CGS和GGS商家之間的合理分配(GGS問題)、商機在各個行業之間的合理分配(行業化問題)、算法需要回答如何定義和度量(Define & Measure)上述7個“合理”,它們之間的關系,以及如何優化它們。
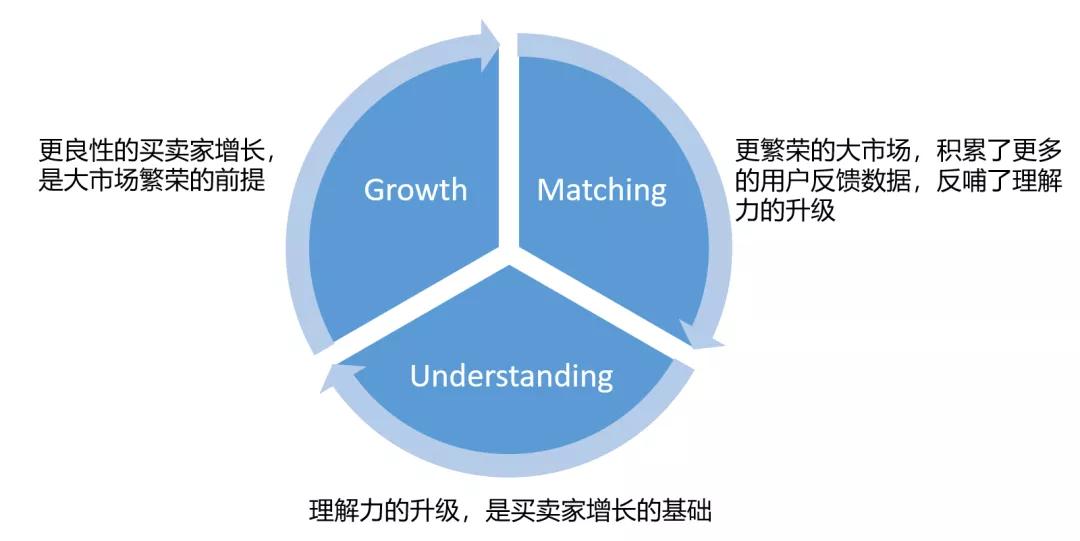
如上圖所示,理解、增長和匹配,形成了一個:理解->增長->匹配->增長……的飛輪,帶動整個ICBU業務的數字智能化的進程。
二 2020年ICBU算法工作總結
接下來分別向大家分享一下“理解”、“增長”和“匹配”三個領域的重要技術成果(以下內容引用自ICBU算法團隊相關文章)。
1 理解(Understanding)
場景底料挖掘
Alibaba.com國際站中,場景導購在首頁中占據著非常重要的地位,但長期起來并沒有體系化的場景生成方案,基本依靠人工經驗來完成場景的構建,而且B類采購的專業性、跨境貿易的文化多樣性、國際環境的不確定性更為有效的導購場景設置了天然的障礙。因此我們針對B類采購的需求,構建了B類場景生成方案,包含了2大特色:
- 基于cpv的細分市場生成。
- 模擬用戶組合采購的事件場景生成。
在網站App首頁、搜索推薦、云主題等場景應用,在過去一年里,算法對場景內容的豐富和優化,為網站帶來了AB和支付買家數提升的業務價值。
智能發品
ICBU作為承接全球B類買家尋源的重要電商平臺之一,一直致力于幫助來自國內的供應商(CGS)和海外供應商(GGS)發布優質的商品信息。商品表達的豐富度和確定性一直是影響買家詢盤,交易轉化的重要因素。為了解決很多商家缺乏運營能力、表達能力弱、重要屬性不填或者濫填、不知道該怎么填寫合理的商品標題等問題,算法建立標題屬性自動生成工具,其中提出了兩大創新點:
- finetuning預訓練文本生成模型BART,構建了文本生成模型。
- 結合ICBU流量特性,將生成語料更符合B類電商檢索和閱讀。
項目上線實驗效果為,在商品信息豐富度上整體約提升6%,算法推薦標題內容采納率CGS約32%,GGS約42%,實驗對比發現通過智能發布的商品在曝光效果提高約40%。
電商場景下的細粒度圖像分類
商品圖像是商品信息展示最重要的組成部分之一,網站圖像質量經過商品信息治理后已有很大提升,但仍缺乏對圖像內容的識別和理解能力。同時,B類商品標準化需要結合圖像標簽能力進行商品信息擴展和校驗,輸出商品結構化表達。我們針對網站需求構建的圖像標簽服務具有以下特色:
細粒度圖像分類模型。為提高對相似商品識別的區分能力,提出一種基于主體分割和圖關系網絡的圖像標簽識別方法,擴大圖像標簽的精準度和召回率。
沉淀了B類特色圖像標簽體系,基于CPV品類體系抽象出外觀有顯著區分度的品類以及屬性作為圖像標簽輸出能力,標簽體系已覆蓋交易TOP15行業,數千個品類標簽。
該項目會應用于搜索相關性提升和商品內容理解,沉淀的技術創新《Object Decoupling with Graph Correlation for Fine-Grained Image Classification》已投稿于ICME2021會議。
視頻檢測、分析、創意
在視頻創意外投承接項目中,我們基于對視頻智能創作流程的理解,設計出了一套基于優質視頻進行視頻合成的方法,提出視頻智能裁切等創新點,解決了視頻智能多尺寸、視頻素材優選、視頻創意美化的難題,克服了目前網站視頻素材質量參差不齊、海外平臺本地化的挑戰。該項目上線后,共生成視頻創意若干個,為ICBU業務節省了若干的創意成本;該項目在取得業務價值的同時,所沉淀的技術創新能力也得到了業界的認可,該技術目前已經應用開源。
2 增長(Growth)
外投預算分配
在智能預算分配1.0項目中,我們基于站內外付費流量數據的深刻洞察,提出了基于分層強化學習的智能預算分配方案,包含了3大創新點:
- 設計了預估器-求解器架構求解整體預算分配問題。
- 使用站內外渠道/國家等特征對付費渠道進行回歸預估,構建模型學習環境。
- 設計了基于分層強化學習的算法求解器,高效求解預算分配問題。
通過分層強化學習等創新設計,有效克服了預算分配與強化學習領域中的稀疏獎賞與延遲獎賞問題,增加求解精度與效率。項目上線后,為付費PPC渠道cpab降低10.3%,該項目還形成了核心創新方案《基于自注意力機制的強化學習預算分配解決方案》和《基于分布式神經進化算法的多目標預算分配模型優化方案》。
horae精排
在horae 1.0項目中,我們基于對付費流量特性的深刻洞察,在付費流量場景從0開始搭建整套召回+排序體系,提出3大創新點:
- 基于站外曝光品的用戶行為采集。
- 充分使用站外渠道/國家特征。
- 基于核心屬性的交叉特征構建。
對付費流量進行單獨建模,解決了付費流量與站內流量在分布上存在巨大差異的領域難題。同時克服了付費流量樣本較少的問題,context特征大量采用站外特征,而商品特征大量采用全站統計特征,充分利用站內數據進行輔助學習。項目上線后,為ICBU展示廣告業務帶來了App端AB rate提升13.6%,Wap端AB rate 提升3%。
供需匹配構建
在先知(紅藍海)項目中,我們基于對買賣家數據的深刻洞察,設計出了用來度量人貨匹配和供給選擇的量化指標,提出了藍海度、競爭力、豐富度三維指數, 帶來了從銷售驅動的供給升級為基于行業路徑和買家需求的定招培育新引擎。該項目上線后,平均簽單周期縮短8%,發MC15提升44%,品效是大盤2倍之多。該項目在取得業務價值的同時,也取得了技術創新,各指數綜合了站內數百特征的同時,結合利用基于時序TRMF預測的未來趨勢和周期性走勢。
買家意愿訂單確認
在Stellar項目中,我們基于賣家待確認PO單數量較大導致訂單無法及時確認,影響O-P轉化的業務痛點,提出基于買家質量、賣家接單偏好及訂單質量等維度,基于樹模型實時預測優質PO單,并解決了數據質量提升、樣本不均衡、id特征及長尾類別特征等技術難題,緩解了O-P鏈路環節中賣家確認率低的業務難題。該項目上線后,PO單確認率提升7pt,O-P轉化+1.2%。
TAO商家智能運營
在TAO拉新項目中,我們發現在供應鏈運營場景,拍檔的人力是有限的,但是客戶規模不斷在增長,如何在有限的人力情況下提升拍檔的人效,我們提出通過大數據的學習及模型可解釋能力,預測潛客分層及千人千面診斷&Action,為拍檔提供傻瓜式的行動指引,項目中使用SHAP、子模型等可解釋技術方案,并將算法解釋轉換為可執行的Action。該項目上線后,為ICBU業務帶來了,TAO拉新轉化率+8.46%,累計貢獻GMV提升的業務價值。
物流費用精準預測
在尼斯湖雙十二買家物流五折項目中,我們發現傳統的營銷運營是廣撒網式的做法,由于與自然轉化客群有較大的交集會造成較多的預算浪費,因此我們首先通過對具備采購需求嚴肅買家支付卡點的分析洞察,進而提出在營銷預算有限的情況下,通過算法精準預測物流費用敏感的支付增量人群的創新點。該項目上線后,為ICBU業務帶來了月均支付增量買家數提升,和ROI提升的業務價值。
3 匹配(Matching)
動態網絡表征學習
在DyHAN(動態圖向量檢索)項目中,我們發現買家在尋源過程中在不斷嘗試尋找更有效的供應商,導致買賣家形成的關系圖隨著時間推移在不斷演進。而之前基于靜態圖的模型無法捕捉這種變化,因此我們提出了基于動態圖的表征學習方法,解決了電商表征建模領域節點信息不斷演進帶來的問題。該項目在ICBU商品詳情頁跨店推薦上線后,核心的詢盤轉化率提升3.54%,創建訂單轉化率提升14.23%;該項目在取得業務價值的同時,所沉淀的技術創新也得到了業界認可,沉淀的《Dynamic Heterogeneous Graph Embedding using Hierarchical Attentions》和《Modeling Dynamic Heterogeneous Network for Link Prediction using Hierarchical Attention with Temporal RNN》論文,分別被ECIR2020和ECML-PKDD2020會議收錄 。
深度多興趣網絡
在DMIN(深度多興趣排序建模)項目中,我們基于ICBU買家特點,發現部分零售商和采購商,其采購商品往往橫跨多個類目,且在多個類目的偏好程度隨時間出現變化。我們基于DIN模型,提出多層次的多興趣抽取網絡模型,提升了模型動態建模買家多興趣的精準性。該項目在ICBU推送推薦場景上線后,曝光點擊率提升10.4%,買家訂單轉化率提升13%;該項目在取得業務價值的同時,所沉淀的技術創新也得到了業界認可,沉淀的《Deep Multi-Interest Network for Click-through Rate Prediction》論文,被CIKM’20會議收錄。
向量召回
跨境B類搜索場景下用戶搜索詞更加多樣化、表達更加專業化,基于傳統的關鍵字召回技術零少問題很嚴重,搜索長尾流量占比將近30%。從2018年開始,ICBU搜索就開始著手探索向量召回技術,用空間向量距離來進行相似度估計,從語義層面進行最相關(距離最近)產品的召回。今年ICBU搜索首次嘗試利用BERT模型結構,自研FashionBERT做到更細粒度的多模態匹配,目前已經基本解決ICBU搜索的零少問題。
在項目中,我們將商品圖像用于召回,即將Query和item image的對應關系轉化為圖文匹配。我們提出FashionBERT圖文匹配模型,直接將圖像split相同大小的Patch,然后將Patch作為圖像的token,和文本進行擬合。同時增加wordpiece來解決oov問題,query graph attention(GAT)來增加長尾Query的泛化能力。我們在電商領域FashionGen數據集,對比了主流圖文匹配技術,FashionBERT取得非常明顯的提升,目前論文《FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval》已被SIGIR2020 Industry Track接收。
語義搜索
ICBU用戶搜索詞更加多樣化表達更加專業化,召回和匹配一直是ICBU網站的搜索優化重點。2020年上半年我們完成了語義搜索1.0(向量召回3.0+語義匹配1.0)的升級,基本解決了相關性零少問題和緩解了關鍵字字面匹配局限問題,但是從通過人工達標分析case,發現當前鏈路依然存在Query理解不足-類目預測不準;核心詞提取不準;關鍵相關性和語義相關性融合方式欠佳等三個問題;針對這些問題,我們融合三個子項目ICBU NER 1.0,類目預測2.0和相關性2.0(融合優化+NER調檔)。進行聯合優化,取得了非常不錯的業務結果:高相關商品曝光占比提升6%,搜索相關性零少下降8%,點擊提升+0.65%,詢盤提升1.44%,支付轉化提升6.30%。
類目預測
對于ICBU而言,類目預測算法的應用場景非常廣泛。在搜索系統中,類目預測結果是商品相關性的重要判定標準,會直接影響搜索結果的召回和排序。對于搜索廣告而言,類目預測也直接影響買家體驗和廣告主效果。因此我們針對ICBU類目預測算法中存在的核心問題進行了重點優化:
- 文本語義分類模型由fasttext升級到了BERT。
- 借助ICBU在NER技術上的沉淀,通過Query中關鍵NER屬性詞組召回相應類目。
類目預測算法優化取得了不錯的效果:
- 離線評測指標:0檔位TOP1類目準確率+5%, 0檔位整體類目準確率+2.4%,0檔位類目召回提升了12.0%。
- 打包語義搜索項目整體,搜索業務指標影響:PC端 L-D +0.65%,L-AB +1.44%,L-P +6.30% ;APP端 L-D +0.69%,L-AB +1.93%,L-P +1.96%。
- 對于廣告業務指標影響:預算分桶下pv2f +2%,rpm+1%,badcase降低3.4%。
跨語言向量召回
我們利用全新的跨語言向量召回技術,跨越Query翻譯的障礙,極大豐富搜索召回結果,促進轉化效率的提升。該創新技術通過基于大規模平行數據的跨語言預訓練模型EcomLM,解決不同語言難以映射到同一語義空間的難題。結合商業表征以及用戶行為信息的間接交互模型,克服了傳統雙塔模型信息隔離的問題。實驗結果表明,通過跨語言向量召回,搜索零少結果率下降至1%以下,V1.0版本多語言整體L-AB +1.34%,L-P +4.2%。此外,我們在語種識別、Query翻譯、多語言語義相關性模型等模塊也有一定的技術積累,旨在打造一套完整的跨語言搜索解決方案。
結構化理解
ICBU作為國際B類跨境貿易的戰場,在當前網站的關鍵詞相關性部分仍存在這個一些問題,例如匹配準度不夠、中心詞提取錯誤、類目預測準確率低。以中心詞提取模塊為例,在關鍵詞匹配的錯誤中,中心詞提取錯誤占了40%,不僅如此,中心詞提取也缺乏提取Query或title中關鍵屬性的能力,例如用戶搜索商品時指定的顏色、規格等,這些都是中心詞提取模塊所欠缺的,因此從國際站搜索的角度來看,迫切需要NER工具來提升目前的關鍵詞匹配準確行。
首先,我們通過與達摩院多語言NLP基礎團隊的合作將NER直接用于搜索匹配中,通過NER來對Query與商品之間實現屬性匹配,基于NER模型的屬性匹配,不僅解決了中心詞提取模塊準確率低的問題,同時也能夠通過對其Query與offfer中的相同屬性,從而給予用戶更加精準的搜索體驗。另一方面,NER也賦能ICBU中的其他業務,如類目預測等、新屬性發現、CPV屬性擴充等,在新的季度,我們也會將NER搜索算法的各個方面,如深度語義匹配,個性化召回等。
三 一些思考
1 數據與算法
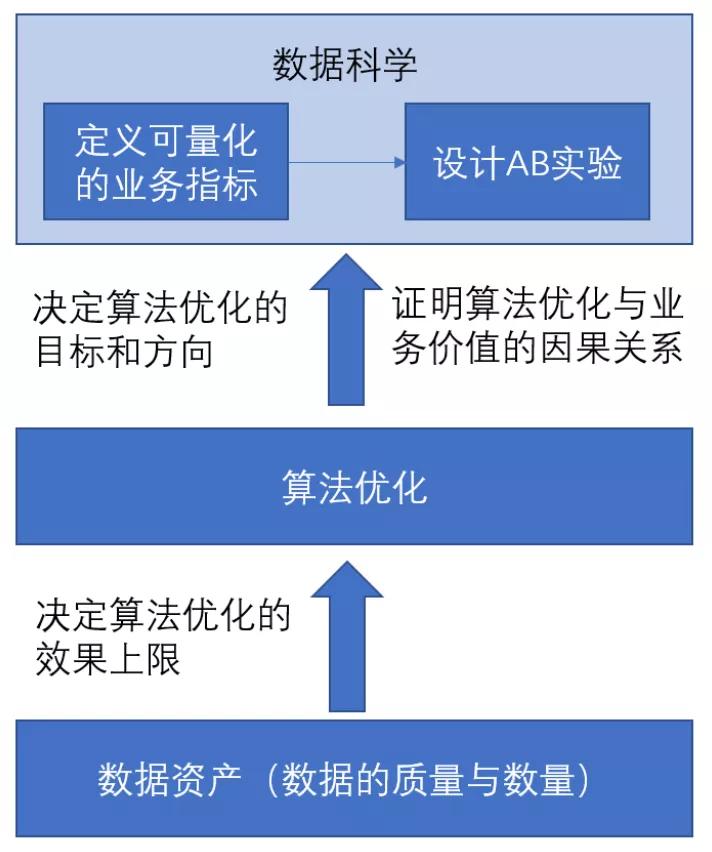
對于業務技術團隊而言,數據,可以從兩個方面去理解它:
- 數據科學(業務指標和因果推斷)——用來回答“算法要去向何方以及如何判斷算法做的事情是否成功”的一個可量化的標準。
- 數據資產——買賣家的行為和整個業務連路上沉淀下的所有數據資產。
數據資產和算法的關系可以理解為:數據資產是燃料,算法是引擎,引擎的輸出取決于燃料的質量和數量。或者說,數據資產是底層的基礎,算法是上層的應用,算法離開了數據資產的養分,就是無源之水無本之木。
數據科學和算法的關系可以理解為:數據科學是確定方向和目標、定義問題、指路明燈,是立靶子。而算法做的事情是在定了方向和目標之后,如何高效率地去標準靶子,去高效率地追逐目標。
結合這兩個角度來看,算法和數據,密不可分,數據科學為算法定義了問題和目標方向,而數據資產又為算法提供了燃料,供算法充分挖掘并使得算法有機會去逼近數據科學指定的目標,并高效地解決數據科學所提出的問題。
2 目標的重要性
前面剛剛說到了“數據科學為算法定義了問題和目標方向”,下面我聊聊“目標”這個話題,我拿一個真實的故事舉個例子:《印尼懸賞除鼠患遭質疑:有人為領獎會養老鼠》[1]。
上面真實故事里面,初衷是好的,以OKR來舉例的話,O(目標)可能是“創建衛生城市,消滅鼠患”。KR的話,有可能是:“通過科學滅鼠的方式,(消滅1000w只老鼠)收集到1000w條的老鼠尾巴。”
消滅鼠患,當然要殺死老鼠;殺死老鼠越多,鼠患消除的越徹底;而殺死老鼠越多,老鼠尾巴就應該會越多——所以我們拿“老鼠尾巴”的個數,來作為一個可量化指標來度量“消滅鼠患”這個目標完成的怎么樣,似乎是一個合理的選擇?問題在于落地和執行,在這個“老鼠尾巴”這個量化指標的激勵下,人們在執行時,會走偏,會發生“養老鼠”這樣奇葩的事情。
一個目標,對于一個業務的成敗來說,其重要性,無論多么強調都不為過。
3 對于未來AB的優化
我們B類跨境外貿在大市場(搜索推薦)算法領域的特點是什么?傳統偏C類電商的搜索推薦場景下,買家的轉化行為周期比較短,這個轉化的目標是一個離散的目標:可以是強轉化(成交),也可以是弱轉化(加購、收藏、關注),但無論是強弱轉化目標,算法建模的目標的都是一個離散的、脈沖式的單點的短期轉化行為的概率,算法優化的目標也同樣是這個離散的、脈沖式的單點的短期轉化行為的數學期望的最大化。
而我們B類的跨境貿易電商場景下,一個B類買家的轉化行為周期很長,這個轉化的目標,不應該是一個離散的目標——比如當天是否會發生AB行為,而應該是一個連續化的目標:一個買家在未來的每一天里會發生AB的行為的概率,我們需要對這個AB在他整個生意周期當中,會留存在ICBU的概率進行連續化地建模和連續化地優化。如果說C類電商搜索推薦場景下,C類買家的整個轉化行為周期比較短,因此建模和優化的目標本身應該也比較短的,是一個突兀的脈沖點的話,那么我們B類電商搜索推薦建模和優化的目標應該是一段持續穩健上升的曲線。也許是我們B類跨境貿易算法需要優化和建模的重要特點,值得我們思考。
當下的優化
簡單的說,當下的優化,算法的目標是去最大化每一次曝光機會轉化為一個AB行為的概率,因此算法真正需要去建模的,就是下面這個概率:

對于當下優化的反思與拆解
我們對當下的搜索推薦的算法優化的反思主要來自兩個方面:
| |
|
|
| 優化粒度 | 用戶粒度(AB) | 行為粒度(AB行為) |
| 優化范圍 | 所有AB(首次+往復) | 首次AB |
讓我們再仔細回顧一下我們真正想要的 (原目標),并對它進行一個細致的拆解:




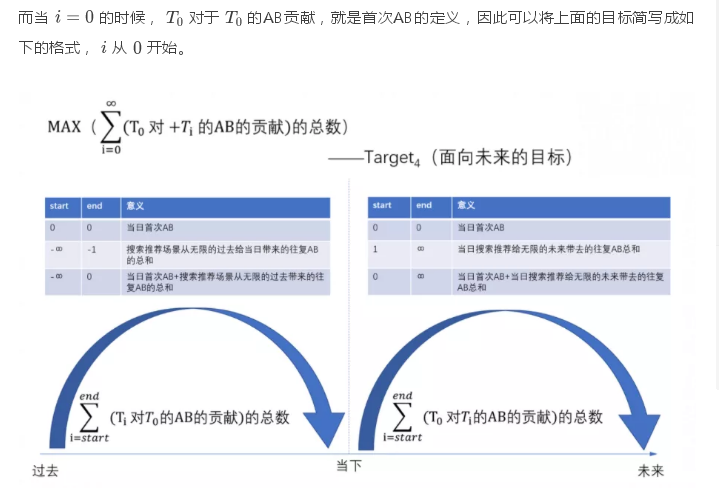
四 展望
接下來,我們的幾個重點包括:智能化運營&買賣家增長之間的更多聯動、內容化、搜推大市場的優化目標新定義、E&E馬太問題&在監管之下的調控等。接下來的一年,將是算法團隊再起飛的一年,算法團隊將更聚焦、做更少的事(但需要更多的人),每做一件事都做深做透,不求每件事都成功,但求每件事都有收獲,無論是業務上的、技術上的,還是經驗教訓上的,并爭取交出算法團隊自身的代表作。