掌握這12個操作系統(tǒng)知識點,把面試官按在地上摩擦
問題一、操作系統(tǒng)的基本特征
1、并發(fā)
并發(fā)指一段時間內(nèi)能同時運行多個程序,并行指同一時刻能運行多個指令。操作系統(tǒng)通過引入進(jìn)程和線程,使得程序能夠并發(fā)運行。
2、共享
共享是指系統(tǒng)中的資源可以被多個并發(fā)進(jìn)程共同使用。它主要有兩種共享方式:互斥共享和同時共享。多個應(yīng)用并發(fā)執(zhí)行的時候,宏觀上要體現(xiàn)出它們在同時訪問資源的情況,而微觀上要實現(xiàn)它們的互斥訪問。比如說我們說到的內(nèi)存。
3、虛擬
虛擬技術(shù)把一個物理實體轉(zhuǎn)換為多個邏輯實體。利用多道程序設(shè)計技術(shù)(程序的交替運行),讓每個用戶都覺得有一個計算機專門為他服務(wù)。主要有兩種虛擬技術(shù):時間復(fù)用技術(shù)和空間復(fù)用技術(shù)。
時間復(fù)用技術(shù)是指多個進(jìn)程能在同一個處理器上并發(fā)執(zhí)行,讓每個進(jìn)程輪流占用處理器,每次只執(zhí)行一小個時間片并快速切換。
空分復(fù)用技術(shù)值將物理內(nèi)存抽象為地址空間,每個進(jìn)程都有各自的地址空間。當(dāng)需要一個地址空間時,如果沒有那就執(zhí)行頁面置換算法。
4、異步
異步指進(jìn)程不是一次性執(zhí)行完畢,而是走走停停,以不可知的速度向前推進(jìn)。但只要運行的環(huán)境相同,OS需要保證程序運行的結(jié)果也要相同。
問題二、進(jìn)程與線程的本質(zhì)區(qū)別、以及各自的使用場景(重要)
1、進(jìn)程
進(jìn)程是資源分配的基本單位。就好比是手機上的一個個應(yīng)用程序。
2、線程
線程是獨立調(diào)度的基本單位。一個進(jìn)程中可以有多個線程,它們共享進(jìn)程資源。
3、進(jìn)程和線程的理解
QQ 和瀏覽器是兩個進(jìn)程,瀏覽器進(jìn)程里面有很多線程,例如 HTTP 請求線程、事件響應(yīng)線程、渲染線程等等,線程的并發(fā)執(zhí)行使得在瀏覽器中點擊一個新鏈接從而發(fā)起 HTTP 請求時,瀏覽器還可以響應(yīng)用戶的其它事件。
4、進(jìn)程和線程的區(qū)別
(1)資源分配
進(jìn)程是資源分配的基本單位,但是線程不擁有資源,多個線程可以共享進(jìn)程資源。
(2)資源調(diào)度
在同一進(jìn)程中,線程的切換不會引起進(jìn)程切換,從一個進(jìn)程中的線程切換到另一個進(jìn)程中的線程時,會引起進(jìn)程切換。就好比是打開了QQ,又打開了瀏覽器。
(3)系統(tǒng)開銷
線程不占用系統(tǒng)資源,比進(jìn)程開銷更小效率更高。這是因為創(chuàng)建或撤銷進(jìn)程時,系統(tǒng)都要為之分配或回收資源,如內(nèi)存空間、I/O 設(shè)備等,切換進(jìn)程時候,還要保存CPU狀態(tài)。
(4)對于一些要求同時進(jìn)行而又共享某些變量的并發(fā)操作來說,只能用多線程,不能用多進(jìn)程。
問題三:進(jìn)程的幾種狀態(tài)
進(jìn)程主要是三種狀態(tài)。
(1)就緒。進(jìn)程已經(jīng)獲得了除CPU以外的所有所需資源,等待分配CPU資源
(2)運行。已獲得了CPU資源,進(jìn)行運行。處于運行態(tài)的進(jìn)程數(shù)<=CPU核心數(shù)
(3)阻塞。進(jìn)程等待某些條件,在條件滿足前無法執(zhí)行
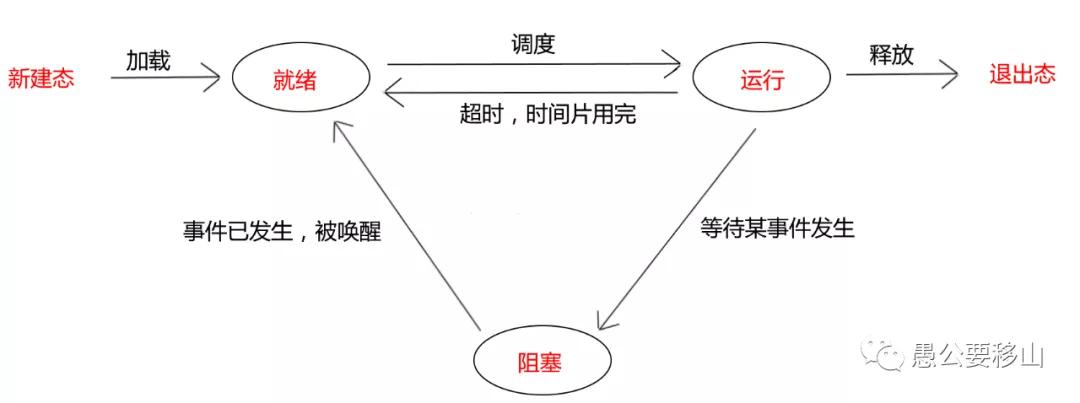
在這里我們最主要的是狀態(tài)之間的切換,比如說阻塞狀態(tài)是不能到運行狀態(tài)的。
問題四:常見的進(jìn)程同步方式和線程同步方式
1、進(jìn)程同步的方式
(1)為什么要進(jìn)程同步
多進(jìn)程雖然提高了系統(tǒng)資源利用率和吞吐量,但是由于進(jìn)程的異步性可能造成系統(tǒng)的混亂。進(jìn)程同步的任務(wù)就是對多個相關(guān)進(jìn)程在執(zhí)行順序上進(jìn)行協(xié)調(diào),使并發(fā)執(zhí)行的多個進(jìn)程之間可以有效的共享資源和相互合作,保證程序執(zhí)行的可再現(xiàn)性。
(2)同步機制需要遵循的原則:
空閑讓進(jìn):當(dāng)沒有進(jìn)程處于臨界區(qū)的時候,應(yīng)該許可其他進(jìn)程進(jìn)入臨界區(qū)的申請
忙則等待:當(dāng)前如果有進(jìn)程處于臨界區(qū),如果有其他進(jìn)程申請進(jìn)入,則必須等待,保證對臨界區(qū)的互斥訪問
有限等待:對要求訪問臨界資源的進(jìn)程,需要在有限時間呃逆進(jìn)入臨界區(qū),防止出現(xiàn)死等
讓權(quán)等待:當(dāng)進(jìn)程無法進(jìn)入臨界區(qū)的時候,需要釋放處理機,邊陷入忙等
(3)進(jìn)程同步的方式:原子操作、信號量、管程。
2、線程同步方式
(1)互斥(信號)量,每個時刻只有一個線程可以訪問公共資源。只有擁有互斥對象的線程才能訪問公共資源,互斥對象只有一個,一個時刻只能有一個線程持有,所以保證了公共資源不會被多個線程同時訪問。
(2)信號量,允許多個線程同時訪問公共資源。當(dāng)時控制了訪問資源的線程的最大個數(shù)。
(3)事件 in windows(條件變量 in linux)。通過通知的方式保持多線程的同步,還可以方便的實現(xiàn)多線程優(yōu)先級的比較
(4)臨界區(qū)。任意時刻只能有一個線程進(jìn)入臨界區(qū),訪問臨界資源。
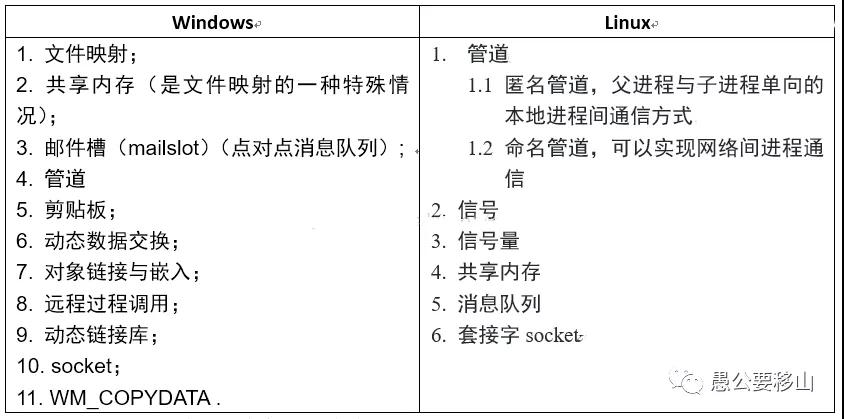
問題五、進(jìn)程間的通信方式
windows和linux是不一樣的。
問題六、進(jìn)程任務(wù)調(diào)度算法的特點以及使用場景
(1)時間片輪轉(zhuǎn)調(diào)度算法(RR):給每個進(jìn)程固定的執(zhí)行時間,根據(jù)進(jìn)程到達(dá)的先后順序讓進(jìn)程在單位時間片內(nèi)執(zhí)行,執(zhí)行完成后便調(diào)度下一個進(jìn)程執(zhí)行,時間片輪轉(zhuǎn)調(diào)度不考慮進(jìn)程等待時間和執(zhí)行時間,屬于搶占式調(diào)度。優(yōu)點是兼顧長短作業(yè);缺點是平均等待時間較長,上下文切換較費時。適用于分時系統(tǒng)。
(2)先來先服務(wù)調(diào)度算法(FCFS):根據(jù)進(jìn)程到達(dá)的先后順序執(zhí)行進(jìn)程,不考慮等待時間和執(zhí)行時間,會產(chǎn)生饑餓現(xiàn)象。屬于非搶占式調(diào)度,優(yōu)點是公平,實現(xiàn)簡單;缺點是不利于短作業(yè)。
(3)優(yōu)先級調(diào)度算法(HPF):在進(jìn)程等待隊列中選擇優(yōu)先級最高的來執(zhí)行。
(4)多級反饋隊列調(diào)度算法:將時間片輪轉(zhuǎn)與優(yōu)先級調(diào)度相結(jié)合,把進(jìn)程按優(yōu)先級分成不同的隊列,先按優(yōu)先級調(diào)度,優(yōu)先級相同的,按時間片輪轉(zhuǎn)。優(yōu)點是兼顧長短作業(yè),有較好的響應(yīng)時間,可行性強,適用于各種作業(yè)環(huán)境。
(5)高響應(yīng)比優(yōu)先調(diào)度算法:根據(jù)“響應(yīng)比=(進(jìn)程執(zhí)行時間+進(jìn)程等待時間)/ 進(jìn)程執(zhí)行時間”這個公式得到的響應(yīng)比來進(jìn)行調(diào)度。高響應(yīng)比優(yōu)先算法在等待時間相同的情況下,作業(yè)執(zhí)行的時間越短,響應(yīng)比越高,滿足段任務(wù)優(yōu)先,同時響應(yīng)比會隨著等待時間增加而變大,優(yōu)先級會提高,能夠避免饑餓現(xiàn)象。優(yōu)點是兼顧長短作業(yè),缺點是計算響應(yīng)比開銷大,適用于批處理系統(tǒng)。
問題七、死鎖的原因、必要條件、死鎖處理、手寫死鎖代碼、java是如何解決死鎖的
1、死鎖的原因
在兩個以上的并發(fā)進(jìn)程中,如果每個進(jìn)程都持有某種資源而又等待其他進(jìn)程釋放他們持有的資源,在未改變這種狀態(tài)前,誰都無法推進(jìn),則發(fā)生了死鎖。就好比是對方相互拿著自己需要的資源,都不釋放自己的。
2、產(chǎn)生死鎖的四個必要條件
(1)互斥。一個資源一次只能被一個進(jìn)程占有
(2)請求與保持。一個進(jìn)程因為請求資源而阻塞時,不釋放自己持有的資源
(3)非剝奪。無法在進(jìn)程結(jié)束前剝奪它對資源的所有權(quán)
(4)循環(huán)等待。若干進(jìn)程收尾相接形成環(huán)形等待關(guān)系
3、死鎖處理
(1)預(yù)防死鎖。破壞后三個條件中的一個即可(互斥是非共享設(shè)備的特性,無法更改):
(2)死鎖避免。避免死鎖并不是事先采取某種限制措施破壞死鎖的必要條件,而是再資源動態(tài)分配過程中,防止系統(tǒng)進(jìn)入不安全狀態(tài),以避免發(fā)生死鎖,比如銀行家算法、系統(tǒng)安全狀態(tài)、安全性算法。
(3)死鎖的檢測與解除:資源分配圖死鎖定理死鎖解除。
4、死鎖代碼
(1)使用信號量實現(xiàn)生產(chǎn)者-消費者
為了同步生產(chǎn)者和消費者的行為,需要記錄緩沖區(qū)中物品的數(shù)量。數(shù)量可以使用信號量來進(jìn)行統(tǒng)計,這里需要使用兩個信號量:empty 記錄空緩沖區(qū)的數(shù)量,full 記錄滿緩沖區(qū)的數(shù)量。其中,empty 信號量是在生產(chǎn)者進(jìn)程中使用,當(dāng) empty 不為 0 時,生產(chǎn)者才可以放入物品;full 信號量是在消費者進(jìn)程中使用,當(dāng) full 信號量不為 0 時,消費者才可以取走物品。
- #define N 100
- typedef int semaphore;
- semaphore mutex = 1;
- semaphore empty = N;
- semaphore full = 0;
- void producer() {
- while(TRUE) {
- int item = produce_item();
- down(&empty);
- down(&mutex);
- insert_item(item);
- up(&mutex);
- up(&full);
- }
- }
- void consumer() {
- while(TRUE) {
- down(&full);
- down(&mutex);
- int item = remove_item();
- consume_item(item);
- up(&mutex);
- up(&empty);
- }
- }
(2)使用管程實現(xiàn)生產(chǎn)者-消費者
- // 管程
- monitor ProducerConsumer
- condition full, empty;
- integer count := 0;
- condition c;
- procedure insert(item: integer);
- begin
- if count = N then wait(full);
- insert_item(item);
- count := count + 1;
- if count = 1 then signal(empty);
- end;
- function remove: integer;
- begin
- if count = 0 then wait(empty);
- remove = remove_item;
- count := count - 1;
- if count = N -1 then signal(full);
- end;
- end monitor;
- // 生產(chǎn)者客戶端
- procedure producer
- begin
- while true do
- begin
- item = produce_item;
- ProducerConsumer.insert(item);
- end
- end;
- // 消費者客戶端
- procedure consumer
- begin
- while true do
- begin
- item = ProducerConsumer.remove;
- consume_item(item);
- end
- end;
(3)讀寫問題
允許多個進(jìn)程同時對數(shù)據(jù)進(jìn)行讀操作,但是不允許讀和寫以及寫和寫操作同時發(fā)生。一個整型變量 count 記錄在對數(shù)據(jù)進(jìn)行讀操作的進(jìn)程數(shù)量,一個互斥量 count_mutex 用于對 count 加鎖,一個互斥量 data_mutex 用于對讀寫的數(shù)據(jù)加鎖。
- typedef int semaphore;
- semaphore count_mutex = 1;
- semaphore data_mutex = 1;
- int count = 0;
- void reader() {
- while(TRUE) {
- down(&count_mutex);
- count++;
- if(count == 1) down(&data_mutex); // 第一個讀者需要對數(shù)據(jù)進(jìn)行加鎖,防止寫進(jìn)程訪問
- up(&count_mutex);
- read();
- down(&count_mutex);
- count--;
- if(count == 0) up(&data_mutex);
- up(&count_mutex);
- }
- }
- void writer() {
- while(TRUE) {
- down(&data_mutex);
- write();
- up(&data_mutex);
- }
- }
(4)哲學(xué)家就餐問題
五個哲學(xué)家圍著一張圓桌,每個哲學(xué)家面前放著食物。哲學(xué)家的生活有兩種交替活動:吃飯以及思考。當(dāng)一個哲學(xué)家吃飯時,需要先拿起自己左右兩邊的兩根筷子,并且一次只能拿起一根筷子。
下面是一種錯誤的解法,考慮到如果所有哲學(xué)家同時拿起左手邊的筷子,那么就無法拿起右手邊的筷子,造成死鎖。
- #define N 5
- void philosopher(int i) {
- while(TRUE) {
- think();
- take(i); // 拿起左邊的筷子
- take((i+1)%N); // 拿起右邊的筷子
- eat();
- put(i);
- put((i+1)%N);
- }
- }
為了防止死鎖的發(fā)生,可以設(shè)置兩個條件:
- 必須同時拿起左右兩根筷子;
- 只有在兩個鄰居都沒有進(jìn)餐的情況下才允許進(jìn)餐。
- #define N 5
- #define LEFT (i + N - 1) % N // 左鄰居
- #define RIGHT (i + 1) % N // 右鄰居
- #define THINKING 0
- #define HUNGRY 1
- #define EATING 2
- typedef int semaphore;
- int state[N]; // 跟蹤每個哲學(xué)家的狀態(tài)
- semaphore mutex = 1; // 臨界區(qū)的互斥
- semaphore s[N]; // 每個哲學(xué)家一個信號量
- void philosopher(int i) {
- while(TRUE) {
- think();
- take_two(i);
- eat();
- put_two(i);
- }
- }
- void take_two(int i) {
- down(&mutex);
- state[i] = HUNGRY;
- test(i);
- up(&mutex);
- down(&s[i]);
- }
- void put_two(i) {
- down(&mutex);
- state[i] = THINKING;
- test(LEFT);
- test(RIGHT);
- up(&mutex);
- }
- void test(i) { // 嘗試拿起兩把筷子
- if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
- state[i] = EATING;
- up(&s[i]);
- }
- }
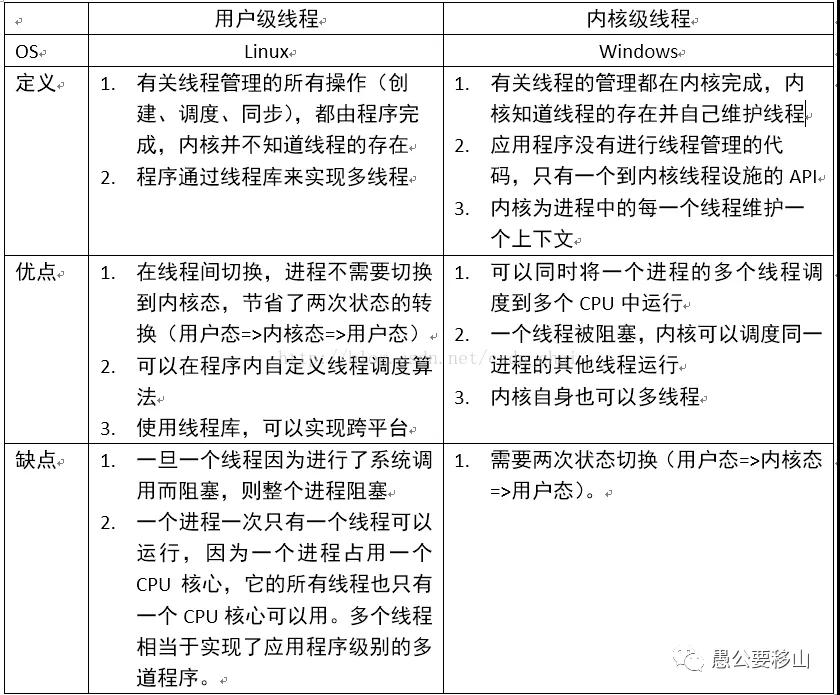
問題八:線程實現(xiàn)的兩種方式,各有什么優(yōu)缺點
問題九、內(nèi)存管理的方式:段式、頁式、段頁式。比較他們的區(qū)別
操作系統(tǒng)中的內(nèi)存管理有三種,段式頁式段頁式。
1、為什么需要三種管理方式
由于連續(xù)內(nèi)存分配方式會導(dǎo)致內(nèi)存利用率偏低以及內(nèi)存碎片的問題,因此需要對這些離散的內(nèi)存進(jìn)行管理。引出了三種內(nèi)存管理方式。
2、分頁存儲管理
(1)基本分頁存儲管理中不具備頁面置換功能,因此需要整個程序的所有頁面都裝入內(nèi)存之后才可以運行。
(2)需要一個頁表來記錄邏輯地址和實際存儲地址之間的映射關(guān)系,以實現(xiàn)從頁號到物理塊號的映射。
(3)由于頁表也是存儲在內(nèi)存中的,因此內(nèi)存數(shù)據(jù)需要兩次的內(nèi)存訪問(一次是從內(nèi)存中訪問頁表,從中找到指定的物理塊號,加上頁內(nèi)偏移得到實際物理地址;第二次就是根據(jù)第一次得到的物理地址訪問內(nèi)存取出數(shù)據(jù))。
(4)為了減少兩次訪問內(nèi)存導(dǎo)致的效率影響,分頁管理中引入了快表,當(dāng)要訪問內(nèi)存數(shù)據(jù)的時候,首先將頁號在快表中查詢,如果在快表中,直接讀取相應(yīng)的物理塊號;如果沒有找到,那么訪問內(nèi)存中的頁表,從頁表中得到物理地址,同時將頁表中的該映射表項添加到快表中。
(5)在某些計算機中如果內(nèi)存的邏輯地址很大,將會導(dǎo)致程序的頁表項會很多,而頁表在內(nèi)存中是連續(xù)存放的,所以相應(yīng)的就需要較大的連續(xù)內(nèi)存空間。為了解決這個問題,可以采用兩級頁表或者多級頁表的方法,其中外層頁表一次性調(diào)入內(nèi)存且連續(xù)存放,內(nèi)層頁表離散存放。相應(yīng)的訪問內(nèi)存頁表的時候需要一次地址變換,訪問邏輯地址對應(yīng)的物理地址的時候也需要一次地址變換,而且一共需要訪問內(nèi)存3次才可以讀取一次數(shù)據(jù)。
3、分段存儲管理
分頁是為了提高內(nèi)存利用率,而分段是為了滿足程序員在編寫代碼的時候的一些邏輯需求(比如數(shù)據(jù)共享,數(shù)據(jù)保護,動態(tài)鏈接等)。
(1)分段內(nèi)存管理當(dāng)中,地址是二維的,一維是段號,一維是段內(nèi)地址;
(2)其中每個段的長度是不一樣的,而且每個段內(nèi)部都是從0開始編址的。由于分段管理中,每個段內(nèi)部是連續(xù)內(nèi)存分配,但是段和段之間是離散分配的,因此也存在一個邏輯地址到物理地址的映射關(guān)系,相應(yīng)的就是段表機制。段表中的每一個表項記錄了該段在內(nèi)存中的起始地址和該段的長度。段表可以放在內(nèi)存中也可以放在寄存器中。
(3)訪問內(nèi)存的時候根據(jù)段號和段表項的長度計算當(dāng)前訪問段在段表中的位置,然后訪問段表,得到該段的物理地址,根據(jù)該物理地址以及段內(nèi)偏移量就可以得到需要訪問的內(nèi)存。由于也是兩次內(nèi)存訪問,所以分段管理中同樣引入了聯(lián)想寄存器。
4、分段和分頁的對比
(1)頁是信息的物理單位,是出于系統(tǒng)內(nèi)存利用率的角度提出的離散分配機制;段是信息的邏輯單位,每個段含有一組意義完整的信息,是出于用戶角度提出的內(nèi)存管理機制
(2)頁的大小是固定的,由系統(tǒng)決定;段的大小是不確定的,由用戶決定
(3)頁地址空間是一維的,段地址空間是二維的
5、段頁存儲方式
先將用戶程序分為若干個段,然后再把每個段分成若干個頁,并且為每一個段賦予一個段名稱。這樣在段頁式管理中,一個內(nèi)存地址就由段號,段內(nèi)頁號以及頁內(nèi)地址三個部分組成。
段頁式內(nèi)存訪問:系統(tǒng)中設(shè)置了一個段表寄存器,存放段表的起始地址和段表的長度。地址變換時,根據(jù)給定的段號(還需要將段號和寄存器中的段表長度進(jìn)行比較防止越界)以及寄存器中的段表起始地址,就可以得到該段對應(yīng)的段表項,從段表項中得到該段對應(yīng)的頁表的起始地址,然后利用邏輯地址中的段內(nèi)頁號從頁表中找到頁表項,從該頁表項中的物理塊地址以及邏輯地址中的頁內(nèi)地址拼接出物理地址,最后用這個物理地址訪問得到所需數(shù)據(jù)。由于訪問一個數(shù)據(jù)需要三次內(nèi)存訪問,所以段頁式管理中也引入了高速緩沖寄存器。
問題十、虛擬內(nèi)存的作用
1、虛擬內(nèi)存存在的意義?
(1)既然每個進(jìn)程的內(nèi)存空間都是一致而且固定的,所以鏈接器在鏈接可執(zhí)行文件時,可以設(shè)定內(nèi)存地址,而不用去管這些數(shù)據(jù)最終實際的內(nèi)存地址,這是有獨立內(nèi)存空間的好處
(2)當(dāng)不同的進(jìn)程使用同樣的代碼時,比如庫文件中的代碼,物理內(nèi)存中可以只存儲一份這樣的代碼,不同的進(jìn)程只需要把自己的虛擬內(nèi)存映射過去就可以了,節(jié)省內(nèi)存
(3)在程序需要分配連續(xù)的內(nèi)存空間的時候,只需要在虛擬內(nèi)存空間分配連續(xù)空間,而不需要實際物理內(nèi)存的連續(xù)空間,可以利用碎片。
2、虛擬內(nèi)存和物理內(nèi)存的關(guān)系

問題十一、頁面置換算法
1、算法講解
(1)最佳置換算法:理想的置換算法。置換策略是將當(dāng)前頁面中在未來最長時間內(nèi)不會被訪問的頁置換出去。
(2)先進(jìn)先出置換算法:每次淘汰最早調(diào)入的頁面 。
(3)最近最久未使用算法LRU:每次淘汰最久沒有使用的頁面。使用了一個時間標(biāo)志。
(4)時鐘算法clock(最近未使用算法NRU):頁面設(shè)置一個訪問位,并將頁面鏈接為一個環(huán)形隊列,頁面被訪問的時候訪問位設(shè)置為1。頁面置換的時候,如果當(dāng)前指針?biāo)疙撁嬖L問為為0,那么置換,否則將其置為0,循環(huán)直到遇到一個訪問為位0的頁面
(5)改進(jìn)型Clock算法:在Clock算法的基礎(chǔ)上添加一個修改位,替換時根究訪問位和修改位綜合判斷。優(yōu)先替換訪問為何修改位都是0的頁面,其次是訪問位為0修改位為1的頁面。
(6)最少使用算法LFU:設(shè)置寄存器記錄頁面被訪問次數(shù),每次置換的時候置換當(dāng)前訪問次數(shù)最少的。LFU和LRU是很類似的,支持硬件也是一樣的,但是區(qū)分兩者的關(guān)鍵在于一個以時間為標(biāo)準(zhǔn),一個以次數(shù)為標(biāo)準(zhǔn)。
(7)頁面緩沖算法PBA:置換的時候,頁面無論是否被修改過,都不被置換到磁盤,而是先暫留在內(nèi)存中的頁面鏈表里面,當(dāng)其再次被訪問的時候可以直接從這些鏈表中取出而不必進(jìn)行磁盤IO,當(dāng)鏈表中已修改也難數(shù)目達(dá)到一定數(shù)量之后,進(jìn)行依次寫磁盤操作。
2、java實現(xiàn)LRU算法
- public class LRU {
- public static void main(String[] args) {
- String[] inputStr = {"6", "7", "6", "5", "9", "6", "8", "9", "7", "6", "9", "6"};
- // 內(nèi)存塊
- int memory = 3;
- List<String> list = new ArrayList<>();
- for(int i = 0; i < inputStr.length; i++){
- if(i == 0){
- list.add(inputStr[i]);
- System.out.println("第"+ i +"次訪問:\t\t" + ListUtils.listToString(list));
- }else {
- if(ListUtils.find(list, inputStr[i])){
- // 存在字符串,則獲取該下標(biāo)
- int index = ListUtils.findIndex(list, inputStr[i]);
- // 下標(biāo)不位于棧頂時,且list大小不為1時
- if(!(list.get(list.size() - 1)).equals(inputStr[i]) && list.size() != 1) {
- String str = list.get(index);
- list.remove(index);
- list.add(str);
- }
- System.out.println("第" + i + "次" + "訪問:\t\t" + ListUtils.listToString(list));
- }else{
- if(list.size()>= memory) {
- list.remove(0);
- list.add(inputStr[i]);
- System.out.println("第" + i + "次" + "訪問:\t\t" + ListUtils.listToString(list));
- }else {
- list.add(inputStr[i]);
- System.out.println("第" + i + "次" + "訪問:\t\t" + ListUtils.listToString(list));
- }
- }
- }
- }
- }
- }
問題十二、靜態(tài)鏈接和動態(tài)鏈接
應(yīng)用程序有兩種鏈接方式,一種是靜態(tài)鏈接,一種是動態(tài)鏈接。
1、基本概念
所謂靜態(tài)鏈接就是在編譯鏈接時直接將需要的執(zhí)行代碼拷貝到調(diào)用處,優(yōu)點就是在程序發(fā)布的時候就不需要的依賴庫,也就是不再需要帶著庫一塊發(fā)布,程序可以獨立執(zhí)行,但是體積可能會相對大一些。
所謂動態(tài)鏈接就是在編譯的時候不直接拷貝可執(zhí)行代碼,而是通過記錄一系列符號和參數(shù),在程序運行或加載時將這些信息傳遞給操作系統(tǒng),操作系統(tǒng)負(fù)責(zé)將需要的動態(tài)庫加載到內(nèi)存中,然后程序在運行到指定的代碼時,去共享執(zhí)行內(nèi)存中已經(jīng)加載的動態(tài)庫可執(zhí)行代碼,最終達(dá)到運行時連接的目的。
2、windows和linux區(qū)別
windows:
在windows上大家都是DLL是動態(tài)鏈接庫,里面是一系列可執(zhí)行的代碼,開發(fā)過windows程序的人可能還知道有另外一種形式的庫,就是LIB,大家可能普遍認(rèn)為LIB就是靜態(tài)庫,至少我之前是這么認(rèn)為的,但是在實際的開發(fā)過程中,糾正了我這個錯誤的想法。LIB形式的文件可能會有兩種形式,這里并不排除第三種形式。1:包括符號表和二進(jìn)制可執(zhí)行代碼,也就是傳統(tǒng)意義上理解的靜態(tài)庫,可以被靜態(tài)連接。2:只有符號表,也就是只有動態(tài)庫的符號導(dǎo)出信息,通過這些信息可以在程序運行時定位到動態(tài)庫中,最終實現(xiàn)動態(tài)連接。
linux:
在linux上大家也都知道SO是動態(tài)庫,類似于windows下的DLL,實現(xiàn)方式也是大同小異,同時開發(fā)過linux下程序的人也都知道另外一種形式的庫就是A庫,同樣道理普遍認(rèn)為是和SO對立的,也就是靜態(tài)庫,不然沒道理存在啊,呵呵。但是事實區(qū)卻不是如此,A文件的作用和windows下的LIB文件作用幾乎一樣,也可能會有兩種形式,和windows下的lib文件一樣,在此就不在贅述。
3、靜態(tài)鏈接庫的優(yōu)點
(1) 代碼裝載速度快,執(zhí)行速度略比動態(tài)鏈接庫快;
(2) 只需保證在開發(fā)者的計算機中有正確的.LIB文件,在以二進(jìn)制形式發(fā)布程序時不需考慮在用戶的計算機上.LIB文件是否存在及版本問題,可避免DLL地獄等問題。
4、動態(tài)鏈接庫的優(yōu)點
(1) 更加節(jié)省內(nèi)存并減少頁面交換;
(2) DLL文件與EXE文件獨立,只要輸出接口不變(即名稱、參數(shù)、返回值類型和調(diào)用約定不變),更換DLL文件不會對EXE文件造成任何影響,因而極大地提高了可維護性和可擴展性;
(3) 不同編程語言編寫的程序只要按照函數(shù)調(diào)用約定就可以調(diào)用同一個DLL函數(shù);
(4)適用于大規(guī)模的軟件開發(fā),使開發(fā)過程獨立、耦合度小,便于不同開發(fā)者和開發(fā)組織之間進(jìn)行開發(fā)和測試。
5、不足之處
(1) 使用靜態(tài)鏈接生成的可執(zhí)行文件體積較大,包含相同的公共代碼,造成浪費;
(2) 使用動態(tài)鏈接庫的應(yīng)用程序不是自完備的,它依賴的DLL模塊也要存在,如果使用載入時動態(tài)鏈接,程序啟動時發(fā)現(xiàn)DLL不存在,系統(tǒng)將終止程序并給出錯誤信息。而使用運行時動態(tài)鏈接,系統(tǒng)不會終止,但由于DLL中的導(dǎo)出函數(shù)不可用,程序會加載失敗;速度比靜態(tài)鏈接慢。當(dāng)某個模塊更新后,如果新模塊與舊的模塊不兼容,那么那些需要該模塊才能運行的軟件,統(tǒng)統(tǒng)撕掉。這在早期Windows中很常見。
本文轉(zhuǎn)載自微信公眾號「愚公要移山」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系愚公要移山公眾號。