













從知識圖譜到知識推理,是否會成為AI的一個熱點
今天寫一篇知識圖譜方面的文章,算作是個人對知識圖譜的一個初步學習和認識。對于知識圖譜最近幾年一直有人跟我談到這個詞,或者是自己在從事知識圖譜技術工作,或者在大數據平臺構建完成后需要構建知識圖譜等。
實際在在10多年前,在企業知識管理和知識庫構建中,類似Autonomy知識管理軟件,當時就談到了文本內容的語義識別和語義網構建,包括類似香農理論和貝葉斯算法的使用等,也有基于知識圖譜的知識和學習路線規劃等。后來Autonomy被HP收購了,反而是銷聲匿跡。
但是最近幾年,隨著大數據和AI人工智能的發展,知識圖譜成為一個新的熱點,并在類似風控和反欺詐,智能推薦引擎,智能知識問答等諸多的領域發揮作用。實際上也可以看到大數據和AI算法的發展都進一步推動知識圖譜的應用和落地。
知識圖譜要構建不能離開大數據,海量自然數據的知識采集和抽象才能夠構建一個完整的知識語義網絡,但是只有網絡還不行,基于語義網絡你的知識推理邏輯和算法還得不斷提供技術支撐。
因此數據+算法兩個方面的發展才是推動知識圖譜細分領域發展的關鍵。
知識圖譜概述
對于知識圖譜,從基本概念到構建流程,方法工具,網上都有詳細的文章可以參考,在這里僅僅對知識圖譜的基礎概念做一個闡述。
知識圖譜(Knowledge Graph)的概念由谷歌2012年正式提出,旨在實現更智能的搜索引擎,并且于2013年以后開始在學術界和業界普及,并在智能問答、情報分析、反欺詐等應用中發揮重要作用。
知識圖譜本質上是一種叫做語義網絡(semantic network)的知識庫,即具有有向圖結構的一個知識庫,其中圖的結點代表實體(entity)或者概念(concept),而圖的邊代表實體/概念之間的各種語義關系,比如說兩個實體之間的相似關系。
當在理解知識圖譜的時候,實體和概念必須要區分清楚,對于概念當前本身又拆分為了概念和屬性兩個獨立的詞。
如果從IT和軟件開發來對比話,實體就類似于領域建模里面的實體對象,而概念類似于值對象,實體對象可以獨立存在,具有獨立生命周期,而概念或值對象則依托于實體,沒有實體單獨談概念對象或值沒有意義。
我們來舉例說明下:
雷軍認識林斌,是在2008年。當時林斌想推動Google和UCWEB之間的合作。雷軍驚訝的發現,林斌有發自內心對產品的熱愛,林斌在Google所做的工作和產品都非常投入,“下功夫”。那個時候,雷軍開始經常去找林斌聊天,兩個大男人經常在一起挑燈夜戰,聊到凌晨一、兩點鐘。聊著聊著,兩人從合作伙伴聊成了好朋友。
從上面這段,我們至少可以得知。
雷軍和林斌是好朋友。
這個是典型的實體和實體間關系描述,可以用類似RDF三元組模型進行抽象和建模,存儲到類似圖數據庫中。里面的核心元數據就是實體對象和實體關系。

可以看到雷軍和林斌兩個是獨立實體,具備獨立的生命周期,雖然兩者之間有關系,但是都可以獨立存在,而不受對方影響。
而對于概念和概念屬性呢?
則類似于進一步對雷軍的個人屬性描述,比如身高,性別,年齡,民族等。概念和屬性最大的一個特點就是概念只是一個屬性列表或者值集合。這個值可以是連續的,如身高數值。也可以是不連續的,如56個民族。但是不管是哪種情況最終概念里面的都是一個最終的屬性值。如同實體不存在了,這個概念和屬性值本身沒有業務意義。
當把這個理解清楚后,我們再來看。
雷軍畢業于湖北仙桃中學,那么仙桃中學究竟是概念還是實體?實際上仙桃中學應該作為實體獨立研究,因為對于仙桃中學的描述,不是通過一系列連續或不連續的值來定義的。同時仙桃中學可以獨立存在,雷軍是否存在過并不影響到仙桃中學這個學校。
那么仙桃中學就應該作為獨立的實體。
基于這個思路,整個關系圖可以變化為如下圖。
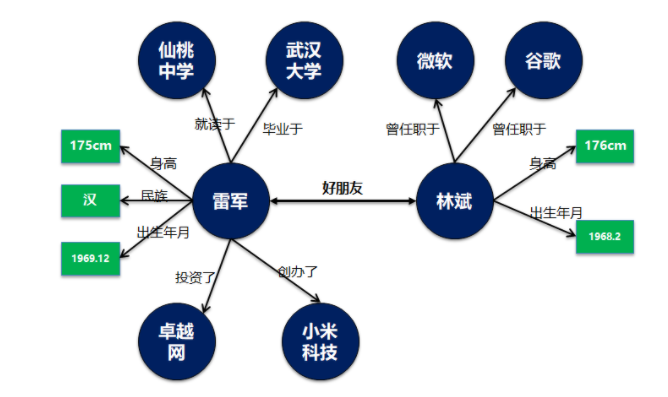
在這里我特意講概念和屬性值用了綠色方框進行描述。
簡單來說概念是一個特殊類型的實體,這類實體不會進一步展開,也不會直接和其它實體之間建立關系映射。
知識圖譜的構建過程
對于知識圖譜的構建過程,網上有很多詳細的文章可以參考,在這類不再詳細描述。僅僅談下重點內容。
在前面的簡單舉例已經可以看到,一個知識圖譜的構建核心還是實體對象的識別,實體關系的建立。也就是需要從一個非結構化的文本材料,乃至語音材料里面識別和抽象出對應的實體,同時建立實體之間的關系。
人和物皆是關鍵的實體
在識別實體的時候可以看到,人和物本身都是重點要識別的實體對象。人本身既從屬于一個團隊,地點或組織,同時也設計或創造事物。
因此再擴展的話,可以理解為物品,場所,人物,企業組織團隊,區域地點是重要可以識別的關鍵實體。這些實體本身又是一種可以向上聚合,向下展開的層次化結構。
比如一個商場本身屬于一個區域,同時商場展開本身又包括多個門店。
抽象概念還是實例概念
當分析實體的時候還得注意實體一般是實例化和特指的,而不是一個抽象的概念。比如當你談到悲慘世界的時候,悲慘世界既可以指雨果的書籍,也可以是電影的某個版本,還可以是10周年的音樂劇。
那我們對實體的研究最好特指到具體的實例層級,比如悲慘世界2012年電影版本。
當理解清楚實體后,再來看關系的識別。
人或物隸屬于一個組織或區域
人創造發明或消費使用某個物品
人和人之間的關系,如家人,同學,同事,合伙人等
實體本身體現的層次關系展開和聚合
也就是大部分實體的關系都體現在上面列舉的各個方面展開。
知識圖譜的構建
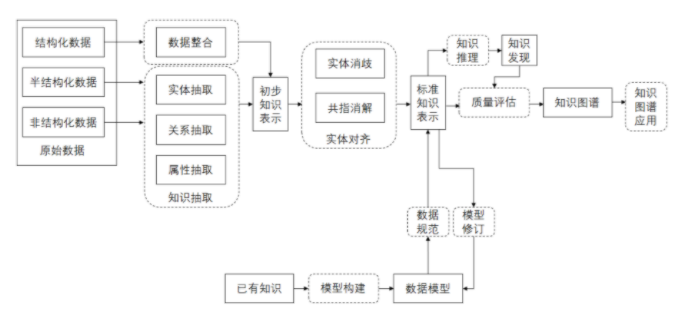
知識圖譜的構建過程實際上相當復雜,但是核心主要包括了知識的抽取,知識存儲,實體對齊,知識建模和知識推理等幾個關鍵步驟。
對于知識的抽象,不論是結構化數據還是文本等非結構化數據,最終都需要轉化為三元組數據結構,方便構建知識圖譜模型。在知識抽取完成后,就涉及到知識的存儲,當前主流仍然是采用類似Neo4j等圖數據庫來完成。在關系型數據庫中所有的數據庫模式都需要提前定義,后續改動代價高昂。而圖模型中,只需要重新增加模式定義, 再局部調整數據,便可完成在原有的數據源上增加標簽或添加屬性。
最近我在查看和學習知識圖譜的一些技術資料,發現一個大問題,即將知識體系和知識圖譜兩個概念混淆,將知識體系誤認為知識圖譜,同時采用思維導圖來構建知識圖譜,這是一個相當錯誤的做法。特別是思維導圖本身就是單節點為中心展開的,完全無法表達多實體之間的關系信息。
類似網上搜索到的這個圖,就是一個完全錯誤的做法。
知識推理過程
知識圖譜在構建完成后,更加重要的是進行知識推理,而知識推理本身是基于構建的推理模型進行的,也就是是知識圖譜體現的人工智能本身是基于算法和推理模型進行的,而非前面文章談到的基于統計學思維的人工智能。
那知識推理究竟是推理什么?
最常見的就是基于實體網絡已經的實體關系來推理實體間的其它關系。比如一個實體三角,當兩個關系已知的時候往往可以推理去未知的關系邊。
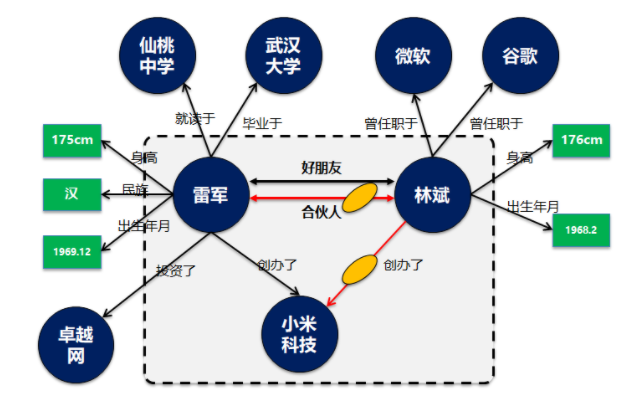
在實體關系里面,如果已知:
- 雷軍創辦了小米科技
- 林斌創辦了小米科技
那么則可以推理出雷軍和林斌兩個實體的關系,從好朋友增加了合伙人關系。
其次常見的就是異常風險檢測。
即通過知識抽取采集形成完整的知識圖譜后,你會發現在整個語義網絡里面實體之間的關系存在異常。在金融等反欺詐領域,經常就會遇到類似的知識圖譜推理邏輯去發現相關的問題,比如常說的多點共享信息,如下圖:
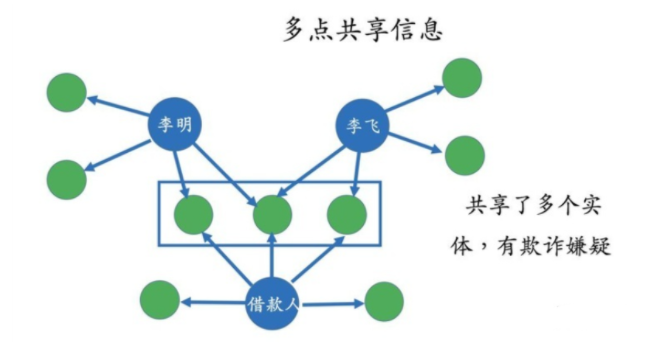
即李明,李飛和借款人三個實體共享多個實體信息,比如居住地址,銀行賬號,畢業學校等完全相同,那么就存在金融欺詐的可能性。
還有串行邏輯推理,最常見的例子類似股權穿透。
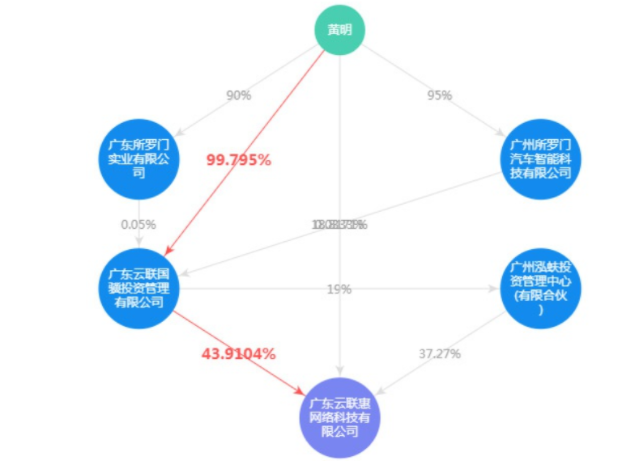
比如張三占A公司股權50%, 而A公司占B公司股權30%,那么股權穿透后張三實際占比A公司股權15%。當然張三可能還通過C公司來占有了B公司股權。通過這種企業和人構成的語義網絡就很容易分析計算出具體的公司實控人等信息。
就當前來看,知識圖譜的推理本身已經不是簡單基于語義網絡的語義模型和規則約束進行推理,而是和深度學習進行結合。即將語義模型導入到深度學習模型中,強化深度學習的推理和預測能力。
我們舉個簡單的例子,比如推薦系統和推薦引擎,實際核心仍然是基于采集的用戶大量行為數據作為基礎,但是同時如果導入了用戶本身的朋友關系語義模型,那么整個推薦模型可能會更加準確。






















