PyTorch1.8正式支持AMD,煉丹不必NVIDIA
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯(lián)系出處。
1.8版本中,官方終于加入了對AMD ROCm的支持,可以方便的在原生環(huán)境下運行,不用去配置Docker了。

AMD ROCm只支持Linux操作系統(tǒng)
1.8版本集合了自2020年10月1.7發(fā)布以來的超過3000次GitHub提交。
此外,本次更新還有諸多亮點:
- 優(yōu)化代碼,更新編譯器
- Python內函數轉換
- 增強分布式訓練
- 新的移動端教程與演示
- 新的性能檢測工具
相關的庫TorchCSPRNG, TorchVision, TorchText和TorchAudio也會隨之更新。
要注意的是,自1.6起,Pytorch新特性將分為Stable、Beta、Prototype三種版本。其中Prototype不會包含到穩(wěn)定發(fā)行版中,需要從Nightly版本自行編譯。
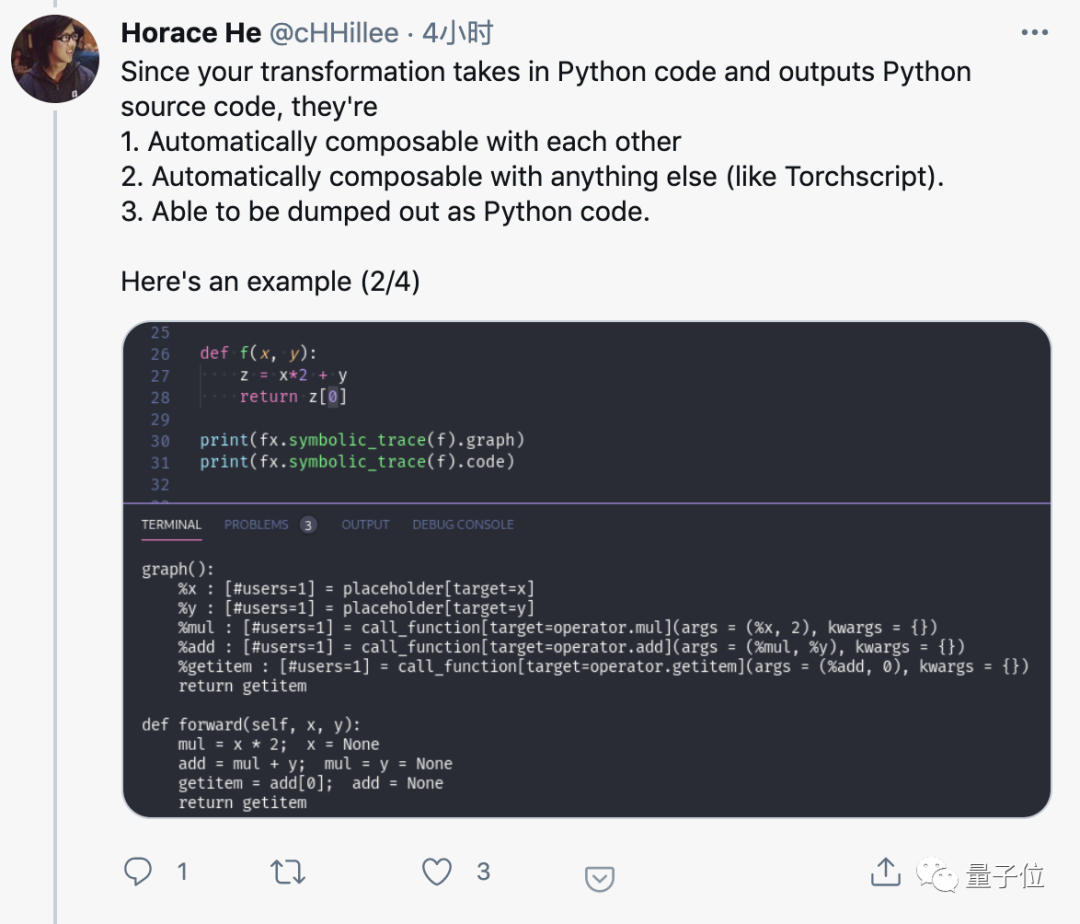
Python to Python函數轉換
新增的Beta特性torch.fx可以實現Python到Python的函數轉換,可以方便的加入任何工作流程。
新的API,向NumPy學習!
1.7版本中增加的Beta特性torch.fft已成為正式特性。實現了與Numpy中的np.fft類似的快速傅立葉變換,還增加了硬件加速支持與自動求導,以更好的支持科學計算。
還增加了Beta版NumPy風格的線性代數模塊torch.linalg,支持Cholesky分解、行列式、特征值等功能。
增強分布式訓練
增加了穩(wěn)定的異步錯誤與超時處理,增加NCCL的可靠性。
增加了Beta版的流水線并行功能*(Pipeline Parallelism)*,可將數據拆解成更小的塊以提高并行計算效率。
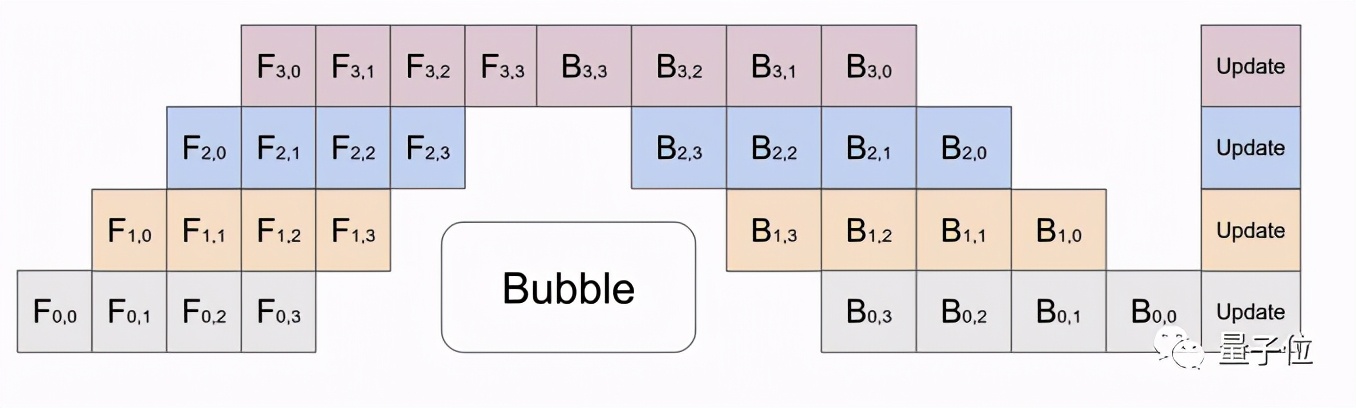
Pipeline Parallelism使用4個GPU時的工作示意圖
增加Beta版的DDP通訊鉤子,用于控制如何在workers之間同步梯度。
另外還有一些Prototype版的分布式訓練新特性。
ZeroRedundancyOptimizer:用于減少所有參與進程的內存占用。
Process Group NCCL Send/Recv:讓用戶可在Python而不是C++上進行集合運算。
CUDA-support in RPC using TensorPipe:增加對N卡多卡運算的效率。
Remote Module:讓用戶像操作本地模塊一樣操作遠程模塊。
移動端新教程
隨本次更新發(fā)布了圖像分割模型DeepLabV3在安卓和IOS上的詳細教程。
以及圖像分割、目標檢測、神經機器翻譯等在安卓和IOS上的演示程序,方便大家更快上手。



另外還有PyTorch Mobile Lite Interpreter解釋器,可以減少運行時文件的大小。
性能檢測工具
增加Beta版的Benchmark utils,用戶可以進行精確的性能測試。
以及Prototype版的FX Graph Mode Quantization,實現了量化過程的自動化。