8 張圖帶你了解大型應用架構演進歷程
幾乎所有的大型應用都是從一個小應用開始的,好的互聯網產品是慢慢運營出來的,不是一開始就開發好的,所以本篇我們來聊聊應用架構的演進歷程。
如何打造一個高可用,高性能,易擴展的應用?首先我們了解一下大型應用的特點:
-
高可用:系統需要不間斷的提供服務,不能出現單點故障
-
高并發:在大流量的沖擊下,系統依然穩定提供服務
-
大數據:應用每天都會產生大量的數據,需要存儲和管理好這些數據
最簡單的架構
剛開始應用沒有太多訪問量,所以只需要一臺服務器,這時候的架構如下圖:
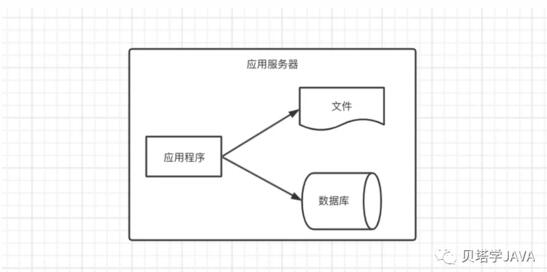
應用程序、文件、數據庫往往都部署在一臺服務器上。應用程序可以采用Java開發,部署在Tomcat服務器上,數據庫可以使用開源的MySQL
應用與數據服務分隔
隨著應用的業務越來越復雜,應用訪問量越來越大,導致性能越來越差,存儲空間嚴重不足,這時候我們考慮把服務增加到三臺(能通過加機器解決的問題都不是問題);分離出應用服務器、數據庫服務器、文件服務器。
-
應用服務器需要處理大量的訪問,所以需要性能更好的CPU
-
數據庫服務器需要存儲大量的數據以及快速的檢索,所以需磁盤的檢索速度較快以及存儲空間大
-
文件服務器需要存儲上傳的文件,需要更大的磁盤;現在通常情況下會選擇第三方的存儲服務
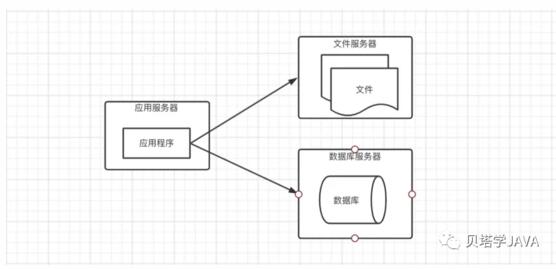
根據每個服務器對應的場景,配置服務器后應用的性能能夠大大提高,更好的支持業務的發展。但是隨之業務的發展,訪問量的增大,這種架構又將再次面臨挑戰,應用服務器處理能力下降,存儲空間不足
應用服務器集群
在高并發,大流量的情況下,一臺服務器是肯定處理不過來的,這個時候增加服務器,部署集群提供服務,來分擔每臺服務器的壓力。部署集群的另一個好處是可伸縮性,比如當遇到了雙11大流量的場景下,可以增加服務器分攤流量,等雙11過后,減少服務器節約成本。架構如下:
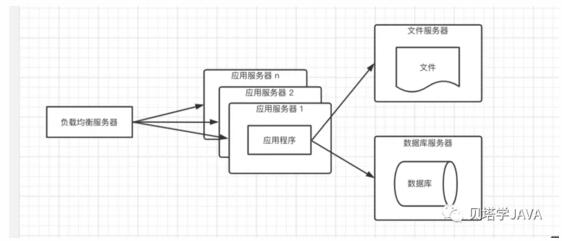
如果應用服務器是Tomcat,那么可以部署一個Tomcat的集群,外部在部署一個負載均衡器,可以采用隨機、輪詢或者一致性哈希算法達將用戶的請求分發到不同應用服務集群;通常選擇的免費的負載均衡是nginx。在這種架構下,應用服務器的負載將不會是整個應用的瓶頸點;
雖然應用程序的處理速度在這種架構下提升了許多,但是又會暴露一個問題,數據庫的壓力大大增大,導致訪問響應延遲,影響整個應用的性能。這種架構還有個問題,通常應用是有狀態的,需要記錄用戶的登錄信息,如果每次用戶的請求都是隨機路由到后端的應用服務器,那么用戶的會話將會丟失;解決這個問題兩個方案:
-
采用一致性hash把用戶的請求路由到同一個Tomcat,如果有一臺服務器跪了,那么這臺服務器上面的用戶信息將會丟失
-
Tomcat集群之間通過配置session復制,達到共享,此方案效率較低
兩個方案都不是很好,那么還有其他的方案嗎?請繼續往下看
根據二八原則,80%的的業務都是集中訪問20%的數據,這20%的數據通常稱為熱點數據,但是這20%的數據占用的內存也不會小,如果每個應用服務器都存放一份,有些浪費存儲空間,所以這時候需要考慮加入分布式緩存服務器(常用的是Redis);當引入了分布式緩存服務器,再來看上面那個方案的問題,就可以解決了,把用戶的會話存放到緩存服務器,不僅可以防止用戶數據丟失,效率也不低;架構圖如下:
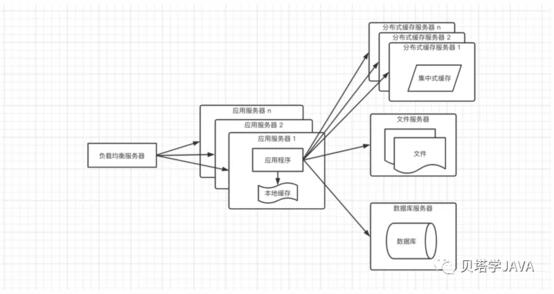
由于分布式緩存服務器畢竟存放在遠程,需要經過網絡,所以取數據還是要花一點時間;本地緩存訪問速度更快,但是內存空間有限,并且還會出現和應用程序爭搶資源;所以這種架構搭配了分布式緩存和本地緩存,本地緩存存放少量常用熱點數據,當本地緩存中沒有命中時在去集中式緩存取
在引進緩存之后,數據庫的訪問壓力可以的一定的緩解
數據庫讀寫分離
雖然在加入了緩存之后,部分數據可以直接走緩存,不需要訪問數據庫,但是任然會有一些請求,會訪問數據庫,比如:緩存失效,緩存未命中;當流量大的時候,數據庫的訪問量也不小。這時候我們需要考慮搭建數據庫集群,讀寫分離
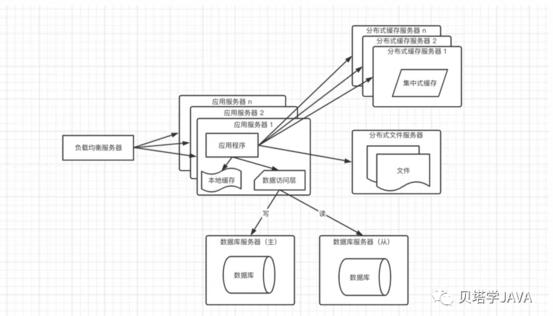
當應用服務器有寫操作時,訪問主庫,當應用程序有讀操作時,訪問從庫;大多數的應用都是讀的操作遠遠大于寫的操作,所以可以配置數據庫一主多從來分擔數據庫的壓力;為了讓應用程序對應主庫和從庫無感知,通常需要引入一些讀寫分離的框架做一個統一的數據訪問模塊。
這種架構通常需要警惕的一個問題是主從延遲,當在高并發的場景下,主庫剛寫成功,數據庫還未成功同步完從庫,這時候另一個請求進入讀取數據發現不存在;解放方案是在應用程序中高并發的場景下設置強制走主庫查詢
❝
兄弟們,請不要白嫖哦,文章看一半,請先點個贊
❞
反向代理和CDN
假如隨著業務的不斷擴大,全國各地都會使用到我們的應用,由于各地區的網絡情況不同,所以有的人請求響應速度快,有的人請求響應速度慢,這會嚴重的影響到用戶的體驗。為了提高響應速度需要引入反向代理和CDN;CDN和反向代理都是采用的緩存,目的:
-
盡可能快的把數據呈現給用戶
-
減輕后端服務器的壓力
架構圖如下:
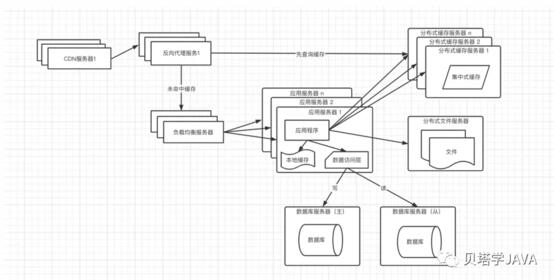
CDN: 部署在網絡提供商的機房,當用戶來訪問的時候,從距離用戶最近的服務器返回數據,盡快呈現給用戶;通常情況下在CDN中緩存的是靜態資源(html,js,css),達到動靜分離;但是有時候遇到了某些數據訪問量特別大的時候,后端會生成靜態資源放入到CDN,比如:商城的首頁,每個用戶進入都需要訪問的頁面,如果每次請求都進入到后端,那么服務器的壓力肯定不小,這種情況下會把首頁生成靜態的文件緩存到cdn和反向代理服務器
反向代理:部署在應用的中心機房,通常也是緩存的靜態資源,當用戶通過CDN未請求到需要的數據時,先進入反向代理服務器,如果有緩存用戶訪問的數據,那么直接返回給用戶;這里也有特殊情況,對于有些場景下的熱點數據,在這里根據用戶的請求去分布式緩存服務器中獲取,能拿到就直接返回。
這種架構已經把緩存做到了4級
-
第一級:CDN 緩存靜態資源
-
第二級:反向代理緩存靜態資源以及部分熱點數據
-
第三級:應用服務器的本地緩存
-
第四級:分布式緩存服務器
通常情況下經過了這4級緩存,能夠進入到數據庫的請求也不多了,很好的釋放了數據庫的壓力
搜索引擎和NoSQL
隨著業務的不斷擴大,對于數據的存儲和查詢的需求也越來越復雜,通常情況我們需要引入非關系型數據庫,比如搜索引擎和NoSQL數據庫
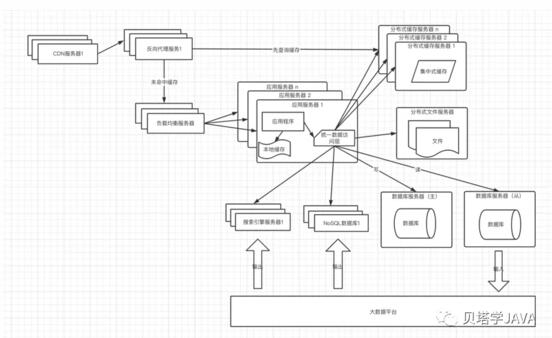
有時候我們的查詢場景很復雜,需要查詢很多數據表,經過一系列的計算才能完成,這時候可以考慮通過數據同步工具(比如canal)拉去數據到大數據平臺,使用批處理框架離線計算,把輸出的結果存放到搜索引擎或者NoSQL數據庫中,應用程序直接查詢計算的結果返回給用戶。也有可能我們需要匯總多個表的數據做一張寬表,方便應用程序查詢
由于引入的數據存儲方式增多,為了減輕應用程序的管理多個數據源的麻煩,需要封裝統一數據訪問模塊,如果使用的時Java,可以考慮spring-data
業務縱向拆分
互聯網公司通常的宗旨是小步迭代試錯快跑,當業務發展到足夠大,對于單體應用想要達到這個宗旨是有難度的,隨著業務的發展,應用程序越來越大,研發、維護、發布的成本也越來越大,這時候就需要考慮根據業務把單體應用拆分為多個服務,服務之間可以通過RPC遠程調用和消息隊列來一起完成用戶的請求。
由于業務的拆分,通常情況下也會相應的對數據庫進行拆分,達到一個服務對應一個數據庫的理想狀態
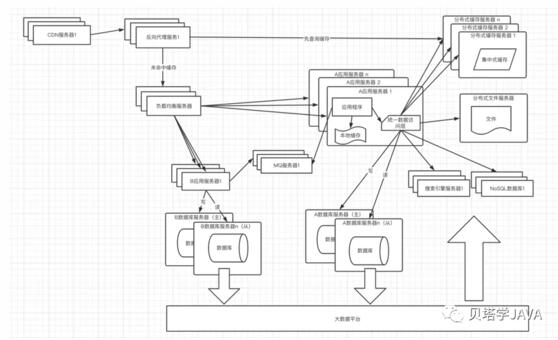
引入MQ的好處:
-
提高系統的可用性:當消費服務器發送故障時,消息還在消息隊列中,數據不會丟失
-
加快請求的響應:當用戶請求到達服務器后,把請求中可以異步處理的數據放入到MQ,讓系統逐一消費,不需要用戶等待,加快了響應速度
-
削峰填谷:當大量請求都同時進入到系統之后,會全部放入到消息隊列,系統逐一消費,不會對系統造成很大的沖擊
還有一個情況未談及到,就是數據庫的水平拆分,這也是數據庫拆分的最后手段,只有當單表數據特別大,不能滿足業務的需要才使用。使用最多的還是進行數據庫的業務縱向拆分,把數據庫中不同業務的數據放到不同的物理服務器上。
應用當前到底選擇什么架構,一定要根據實際業務的需求進行靈活的選擇,驅動技術架構發展的主要動力還是在于業務的發展,不要為了技術而技術。
寫在最后
-
首先感謝大家可以耐心地讀到這里。
-
當然,文中或許會存在或多或少的不足、錯誤之處,有建議或者意見也非常歡迎大家在評論交流。