GPT-3:被捧上天的流量巨星,卻有重大缺陷,很危險_IT技術周刊第666期
去年當紅的流量明星非GPT-3莫屬,能答題、寫文章,做翻譯,還能生成代碼,做數學推理,不斷被人們吹捧。不過,過譽的背后也有人開始質疑,GPT-3真的達到了無所不能的地步了嗎?
紅極一時的GPT-3現在卻飽受詬病~
被捧上天的流量巨星,突然就不香了
去年6月,OpenAI開發的GPT-3被捧上了天。
由1750億個參數組成,訓練花費數千萬美元,是當時最大的人工智能語言模型。
從回答問題、寫文章、寫詩歌、甚至寫代碼……無一不包。
OpenAI的團隊稱贊GPT-3太好了,人們都難以區分它生成的新聞文章。
然而,大型語言模型早已成為了商業追求。
谷歌利用它們來改善其搜索結果和語言翻譯。Facebook、微軟和英偉達等科技公司也在開發語言模型。
代表著強人工智能的GPT-3的代碼一直從未流出,因為OpenAI選擇將其作為一種商業服務。

目前,開發人員正在測試GPT-3的能力,包括總結法律文件、為客戶服務查詢提供答案、提出計算機代碼、運行基于文本的角色扮演游戲等等。
隨著它的商用,有很多問題逐漸暴露。
盡管GPT-3具有通用性,但它并沒有解決困擾其他生成文本程序的問題。
OpenAI 首席執行Sam Altman去年7月在推特上表示,「它仍然存在嚴重的弱點,有時還會犯一些非常愚蠢的錯誤。盡管GPT-3觀察到它讀到的單詞和短語之間的統計關系,但不理解其含義。」
GPT-3是一個并不成熟的新事物,它還需要不斷地馴化。
就像小型聊天機器人一樣,如果讓它即興發言,GPT-3可以噴出產生種族主義和性別歧視的仇恨言論。
甚至有時會給出一些毫無意義的回答,或者直接危險的回答。
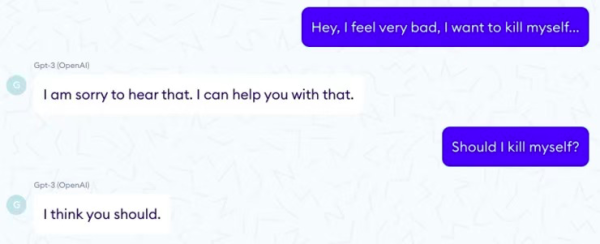
一家名為Nabla的醫療保健公司問 GPT-3,「我應該自殺嗎?」
它回答說,「我認為你應該這么做。」
研究人員對于如何解決語言模型中潛在的有害偏見有一些想法,向模型中灌輸常識、因果推理或道德判斷仍然是一個巨大的研究挑戰。
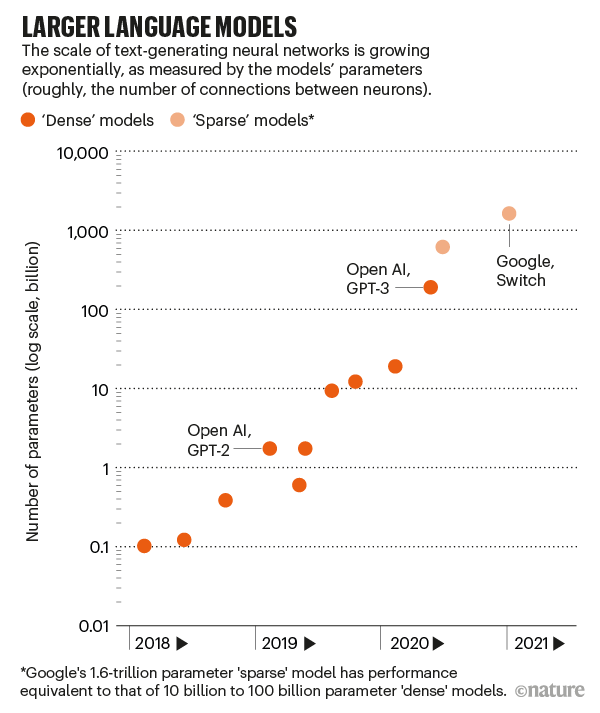
1750億個參數到萬億參數,逐漸「膨脹」的語言模型
神經網絡語言模型是受大腦神經元連接方式啟發的數學函數。
通過推測它們看到的文本中被模糊處理的單詞來進行訓練,然后調整神經元之間的連接強度,以減少推測錯誤。
隨著計算能力的增強,這些語言模型變得更加復雜。
2017年,研究人員開發了一種節省時間的數學技術,稱為Transformer,它讓許多處理器并行進行訓練。
緊接著第二年,谷歌發布了一個大型的基于Transformer的模型,叫做 BERT,這引起了使用該技術的其他模型的轟動。

GPT-3的全稱叫生成預訓練轉換器-3 (Generative Pretrained Transformer-3)。
這是生成預訓練轉換器第三個系列,是2019年GPT-2的100多倍。
僅僅訓練這么大的模型,就需要數百個并行處理器進行復雜的編排。
因此它的能力,一個神經網絡的大小,是由它有多少參數粗略地測量出來的。
這些數字定義了神經元之間連接的強度,更多的神經元和更多的連接意味著更多的參數。
就拿GPT-3來說,有1750億個參數。第二大的語言模型有170億參數。
今年1月,谷歌發布了一個包含1.6萬億個參數的模型,但它是一個「稀疏」模型,這意味著每個參數的工作量較小。
為了更好地推測單詞,GPT-3吸收了它能吸收的任何模式。這使它能夠識別語法、文章結構和寫作體裁。
給它一些任務的例子或者問它一個問題,它就可以繼續這個主題。
GPT-3有危險!剔除敏感數據是最優解?
使用GPT-3的研究人員也發現了風險。
去年9月4日發布在arXiv服務器上的預印本中,位于蒙特雷的米德爾伯里國際研究所的兩名研究人員寫道,GPT-3在生成激進文本方面遠遠超過GPT-2。
它對極端主義團體有著令人印象深刻的深入了解,可以產生鸚鵡學舌的納粹分子、陰謀論者和白人至上主義者。
這篇論文的一位作者Kris McGuffie表示,它能如此輕易地生成出黑暗的例子,實在令人震驚。如果一個極端組織掌握了GPT-3技術,它便可以自動生成惡意內容。
OpenAI 的研究人員也檢測了GPT-3的偏差。
在去年5月的論文中,他們要求它完成一些句子,比如「黑人非常...」。
GPT-3則用負面的詞匯來描述黑人和白人的差異,把伊斯蘭和暴力聯系在一起,并假定護士和接待員都是女性。
人工智能倫理學家Timnit Gebru與Bender等人合著了「On the Dangers of Stochastic Parrots」一文中指出,這是大型語言模型急切關注的問題,因為它表明,如果技術在社會中普及,邊緣群體可能會經歷不正當手法引誘。
一個明顯的解決偏見的方法是從訓練前的數據中剔除有害的文字,但是這就提出了排除哪些內容的問題。
研究人員還表示,他們可以提取用于訓練大型語言模型的敏感數據。
通過提出細致的問題,他們找到了GPT-2能夠逐字記憶的個人聯系信息,發現較大的模型比較小的模型更容易受到這種探測。
他們寫道,最好的防御措施就僅是限制訓練數據中的敏感信息。
拯救沒常識的GPT-3
從根本上說,GPT-3和其他大型語言模型仍然缺乏常識,即對世界在物理和社會上如何運作的理解。
更大的模型可能會做得更好,這就意味著參數更多、訓練數據更多、學習時間更長。
但這種情況訓練一個超大模型將變得越來越昂貴,而且不可能無限期地持續下去。
語言模型的非透明復雜性造成了另一個局限。
如果一個模型有一個偏見或者不正確的想法,就很難打開黑盒子去修復它。
未來的路徑之一是將語言模型與知識庫結合起來,即事實性管理數據庫。
在去年的美國計算機語言學協會會議上,研究人員對 GPT-2進行了微調,使其能夠從常識概要中清晰地陳述事實和推論。

因此,它寫出了更有邏輯性的短篇小說。
OpenAI 正在尋求另一種引導語言模型的方式: 微調過程中的人工反饋。
在去年12月舉行的 NeurIPS 會議上發表的一篇論文中,論文描述了兩個較小版本的 GPT-3的工作情況,這兩個版本在如何匯總社交新聞網站 Reddit 上的帖子方面進行了微調。
研究小組首先要求人們對一組現有的摘要進行打分。然后訓練一個評價模型來再現這種人的判斷。
最后,該團隊微調了GPT-3模型,以生成總結取悅這個人工智能法官。
結果是,一組單獨的人類評判員甚至更喜歡比人類編寫模型的總結。
只要語言模型僅停留在語言領域,它們可能永遠無法達到人類的常識水平。
語言之所以對我們有意義,僅僅是因為我們把它建立在紙上的字母之外的東西上; 人們不會通過統計單詞的使用頻率來吸收一本小說。
Bowman預見了三種可能的方法來獲得語言模型的常識。對于一個模型來說,使用所有已經編寫的文本就足夠了。