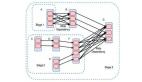
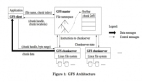
分布式存儲的技術趨勢(三):雙重RAID機制與三副本對比
雙重RAID究竟能否有效解決三副本的缺陷?讓我們從二者之間的對比開始。在前面我們分析了三副本的潛在隱患,也介紹了雙重RAID架構的工作原理與技術特點。雙重RAID究竟能否有效解決三副本的缺陷?讓我們從二者之間的對比開始。
故障修復時間更短,業務影響更小
硬盤損壞時,雙重RAID機制優先通過節點內RAID恢復數據,該恢復機制可自動調節速度以避讓工作負載,前端業務無感知。無需觸發網絡數據重建,從而有效地避免了網絡重建風暴。
節點故障時,可通過遷移磁盤到另一臺物理服務器,實現節點遷移(無需拷貝或重建數據)。SVM存儲池上每個磁盤記載關于存儲池構成的全部信息,分布式存儲的vOSD的ID號及用戶數據,保存在SVM存儲池的虛擬卷上,自動隨著SVM存儲池的遷移從一臺物理服務器遷移到另一臺物理服務器,主機名及vOSD的ID號保存不變,實現快速節點修復。
容錯性更強,可允許多節點同時有磁盤損壞
三副本分布式存儲通過跨節點的副本保護,可有效防止單個或兩個磁盤損壞對業務數據的影響,但是容錯性受到限制,如在三副本的情況下,不同故障域內之間,最多只能允許2個節點有磁盤損壞,超出2個節點出現磁盤故障,則極有可能發生數據丟失,如圖1所示。

圖 1 三副本分布式存儲多節點硬盤損壞導致數據丟失
鐵力士分布式存儲通過雙重RAID 機制,能夠將容錯性提升一個數量級。如圖2所示,以節點內RAID 10+節點間2副本為例,當每個節點都出現磁盤故障的時候,可以通過節點內RAID 分別修復,保障整個系統數據無丟失,業務無中斷。
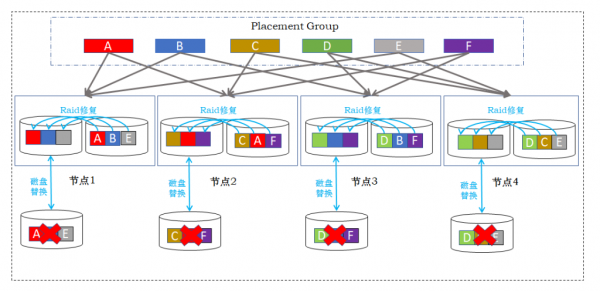
圖 2 雙重RAID容忍多節點磁盤損壞
數據持久性(Durability)高出一個數量級
下面通過具體數值來比較三副本與雙重RAID的數據持久性(可靠性)。數據持久性指標可通過存儲系統的AFR(Annual Failure Rate)來衡量。考慮一個1000個6TB硬盤的存儲集群,每個機械硬盤的MTTF(Mean Time to Failure)為1000,000小時。在計算中需要運用兩個著名的MTTF公式,一個是關于RAID6,其MTTF=(MTTF)*(MTTF)*(MTTF)/(N*(N-1)*(N-2)*MTTR), 另一個是關于RAID5,其MTTF=(MTTF)*(MTTF)/(N*(N-1)MTTR), 其中MTTR(Mean Time to Repair)是硬盤平均修復時間。
在三副本條件下,存儲系統共有333組三副本,每組三副本的MTTF相當于N=3的RAID6,在分布式并發修復的條件下,MTTR通常為3小時(每半小時修復1TB數據),因此每組三副本的MTTF =1000000*1000000*1000000/(3*2*1*3)=5.56x 1016 小時,而整個系統的MTTF = 5.56x 1016 /333 =1.67x 1014 小時。折算為AFR(一年共8760小時),AFR=8760/(1.67x 1014) =5.2x 10-11。
在雙重RAID情況下,考慮節點內采用(2+1) RAID5,存儲系統共有333組RAID5,為簡化計算,考慮每組RAID對應于兩個vOSD,12TB數據。據測算,RAID5的MTTR為30小時,每組RAID5 (vOSD)的MTTF=1000000*1000000/(3*2*30)=5.56x 109 小時。當一個RAID5組損壞時,由于vOSD在跨節點之間有鏡像保護(其可靠性相當于N=2 RAID5),采用分布式并發修復12TB數據,每半小時修復1TB數據,需6小時,因此,其MTTR=(5.56x 109 )* (5.56x 109 )/(2*1*6)=2.58x 1018 小時。考慮到整個存儲系統有333組RAID5, 因此整個系統的MTTF=2.58x 1018/333 =7,75x 1015 小時,相當于三副本MTTF的46倍。折算為AFR,雙重RAID的AFR=8760/(7.75x 1015)= 1.1x 10-12 。
對比三副本和雙重RAID的數據持久性,可見雙重RAID的數據可靠性高于三副本一個數量級以上。
總結
鐵力士分布式存儲將傳統磁盤陣列的RAID技術、存儲虛擬化管理技術與分布式存儲技術相結合,有效地解決了普通分布式存儲面臨的IO分布不均勻和木桶效應導致的性能缺陷,大幅度提升系統IOPS性能,并避免了普通分布式存儲因網絡重建風暴而可能導致的穩定性隱患。同時,雙重RAID架構的數據可靠性高于三副本分布式存儲一個數量級以上。