













常見的垃圾回收器你知道有哪些嗎?
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲。轉載本文請聯系Java極客技術公眾號。
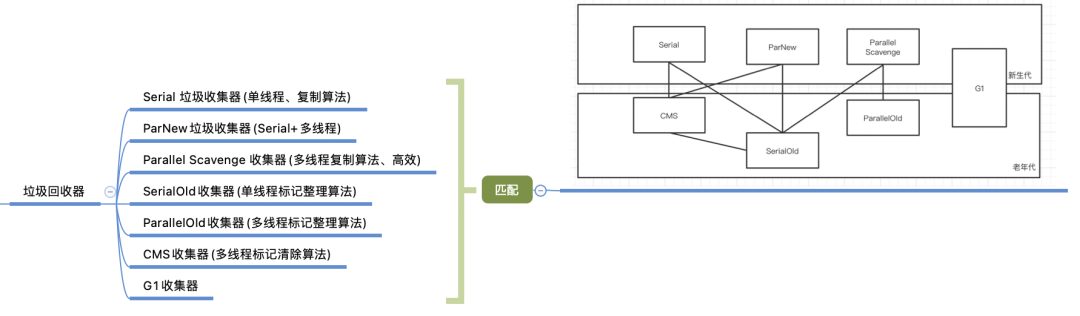
作為一個 Java 開發,在面試的過程中垃圾回收器是經常會被問到的一個問題,隨著 Java 的發展,垃圾回收器也經歷了很多的發展。大家熟知的垃圾回收器主要有下面幾種。
- Serial 單線程新生代復制算法的垃圾回收器;
- SerialOld 垃圾回收器,是一種單線程老年代標記整理算法;
- ParNew 垃圾回收器,是 Serial 的多線程實現,采用復制算法實現;
- Parallel Scavenge 垃圾回收器,是一種高效的多線程復制算法;
- ParallelOld 垃圾回收器,是 Parallel Scavenge 的一種老年代的多線程標記整理算法;
- CMS 垃圾回收器,是一種多線程標記清除算法,后面會詳細介紹;
- G1 垃圾回收器,是一種高吞吐量的垃圾回收器。
回收算法
在介紹垃圾回收器之前,我們先了解一下垃圾回收器背后的算法,每個垃圾回收器都是具體算法的實現,不同的垃圾回收器只是背后的算法不同而已,下面就先簡單介紹下具體的算法。
標記清除
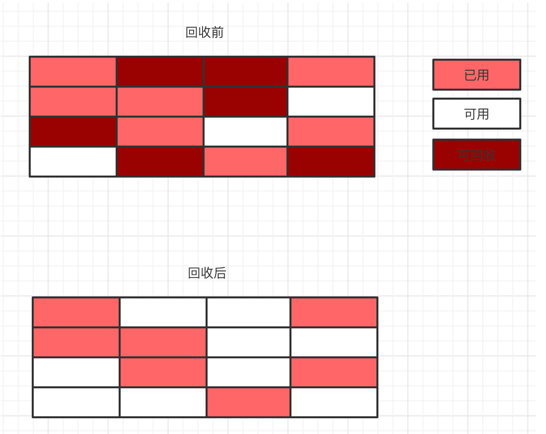
標記清除算法是一種先標記,后清除的算法,在第一次掃描的時候先標記出所有需要清理的內存,將所有需要回收的內存都標記過后,一次性清理掉。這種算法簡單但是效率低,而且內存碎片化嚴重。內存一旦碎片化嚴重的話,就會浪費內存,無法分配較大的對象。
復制算法
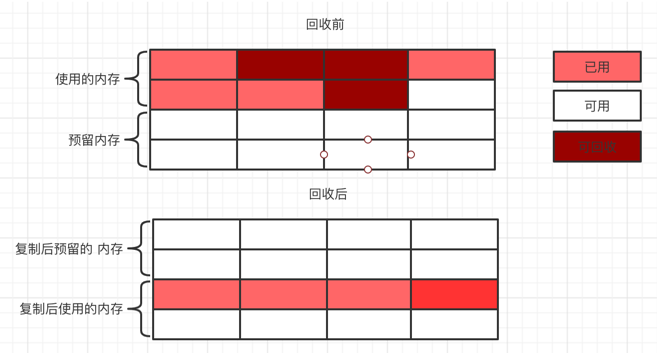
復制算法的實現方式比較簡潔明了,就是霸道的把內存分成兩部分,在平時使用的時候只用其中的固定一份,在當需要進行 GC 的時候,把存活的對象復制到另一部分中,然后將已經使用的內存全部清理掉。這種算法可以解決碎片化的問題,但是缺點也很明顯,就是浪費內存,有一半的內存都不能使用。
標記整理算法
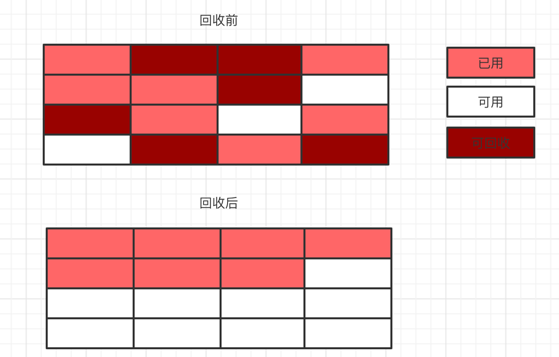
既然標記清除和復制算法各有優缺點,那自然的我們就想到是否可以把這兩種算法結合起來,于是就出現了標記整理算法。標記階段是標記清除算法一樣,先標記出需要回收的部分,不過清除階段不是直接清除,而是把存活的對象往內存的一端進行移動,然后清除剩下的部分。
標記整理的算法雖然可以解決上面兩個算法的一些問題,但是還是需要先進行標記,然后進行移動,整個效率還是偏低的。
分代回收算法
分代回收算法是目前使用較多的一種算法,這個不是一個新的算法,只是將內存進行的劃分,不同區域的內存使用不同的算法。根據對象的存活時間將內存的劃分為新生代和老年代,其中新生代包含 Eden 區和 S0,S1。在新生代中使用是復制算法,在進行對象內存分配的時候只會使用 Eden 和 S0 區,當發生 GC 的時候,會將存活的對象復制到 S1 區,然后循環往復進行復制。當某個對象在進行了 15 次GC 后依舊存活,那這個對象就會進入老年代。老年代因為每次回收的對象都會比較少,因此使用的是標記整理算法。
垃圾回收器
上面雖然提到了好幾個垃圾回收器,但是目前主流的垃圾回收器只有 CMS 和 G1。下面就跟大家聊下這兩個垃圾回收器。
CMS 垃圾回收器
CMS 全稱 Concurrent Mark Sweep 并發標記清除垃圾回收器。CMS 是一種以獲取最短停頓時間為目的的垃圾回收器。提到停頓時間,我們都知道任何垃圾回收器在進行工作的時候都會出現 STW,Stop the World 停止用戶進程,這對業務來說只很難接受的,但是現在市面上所有的垃圾回收器都無法避免這個問題,只能最大化的去優化,從而降低停頓的時間。
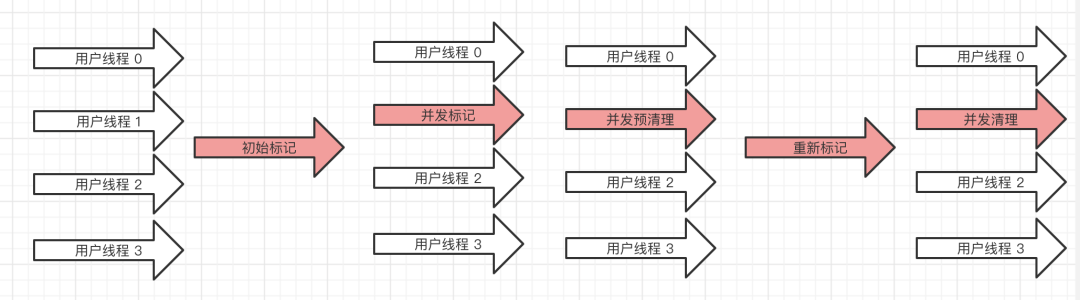
CMS 雖然被稱為是并發的垃圾回收器,但是也并不是完全并發的,從名字上我們可以看到是采用標記-清除算法來實現的,整個實現過程分為五個步驟:
- 初始標記:暫停所有線程,從來可達性分析來標記對象,這也是 CMS 垃圾回收器第一個 STW 的時候;
- 并發標記:并發標記的時候 GC 線程和用戶線程是同時存在的,這個過程中會記錄所有可達的對象,但是這個過程結束過后由于用戶線程一直在運行所以還會產生新的引用更新,也就是需要下一步了;
- 并發預清理:這個階段用戶線程和 GC 線程同時運行,GC 線程會進行一下預清理的動作;
- 重新標記:重新標記這個階段會暫停用戶線程,將上一步并發標記過程中用戶線程引起的更新進行修正,這個時間會比初始標記時間長,但是會比并發標記時間短一點;
- 并發清除:在所有需要清理的對象都被標記完過后就會執行最后一步清理的動作。清理的時候用戶線程是可以繼續運行的,GC 線程只清理標記的區域。
G1 垃圾回收器
G1 全稱 Garbage-First 是一種面向服務器的垃圾回收器,通過將堆內存劃分為多個 Region 來實現可預測的停頓時間模型。在 G1 當中,新生代和老年代已經不再是物理隔離,而都是被劃分一個個 Region 區域。正是由于這種可預測的時間停頓模型讓 G1 成為了一個高吞吐量的垃圾回收器。G1 能充分利用 CPU,多核環境下可以縮短 STW 的時間。
G1 垃圾回收器的整個實現過程分為四個步驟:
- 初始標記:通過可達性分析標記 GC Roots 的直接關聯對象,這個階段與 CMS 一樣需要 STW;
- 并發標記:并發標記是通過 GC Roots 找到存活的對象,這個階段 GC 線程是與用戶線程同時運行的,并且這個階段的時間比初始標記長;
- 最終標記:最終標記跟 CMS 的重新標記一樣,也是為了修正并發標記過程中因用戶線程繼續運行而導致產生新的引用更新;同樣的這里也需要 STW;
- 篩選回收:篩選回收這里會對每個 Region 的回收成本進行排序,根據用戶期望的停頓時間來制定收回計劃,這也就是可預測的停頓時間模型的體現之處,這個階段 GC 線程是與用戶線程同時運行的。
總結
雖然說 Java 開發不用程序員去手動創建和回收內存,但是了解和掌握垃圾回收器是每個 Java 程序員必須要掌握的,不僅僅是面試的過程中會被問到,對自己的職業發展也是很有幫助的。本文是阿粉自己學習和整理的,部分資料參考網絡上,分享給大家,幫助大家一起成長。





















