人工智能博士一篇文章讓你詳解分類、回歸評價指標,機器學習必看
作者:佚名
我們總是想到建模一個好的機器學習算法所涉及的步驟。第一步是評估模型優劣的指標。當我們擬合模型并做出預測時,我們總是嘗試了解誤差和準確性。本文將嘗試提供并解釋回歸和分類中的各種錯誤度量方法。
在本文中,我們將討論機器學習中回歸和分類的各種指標。我們總是想到建模一個好的機器學習算法所涉及的步驟。第一步是評估模型優劣的指標。當我們擬合模型并做出預測時,我們總是嘗試了解誤差和準確性。本文將嘗試提供并解釋回歸和分類中的各種錯誤度量方法。
有一些標準可以評估模型的預測質量,如下所示:
- 度量函數:我們將在本文中進行研究。
- 估計器評分方法:此方法具有評估解決問題的評分方法。
- 評分參數:該評分參數告訴估算人員選擇度量與模型的評估grid_search.GridSearchCV和cross_validation.cross_val_score
基本定義
估計器:它是一個函數或方程式,用于預測實際數據點上的更準確的建模點。
要知道的技巧
評估方法中有兩點需要注意,如下所示:
- 首先,某些方法以score單詞結尾,這意味著價值來自于此,它決定了基本事實。在這種情況下,如果數字較高,則更好。
- 第二個,如果單詞以error或結尾loss。在這種情況下,數量越少越好。
回歸指標
評估回歸性能的指標如下:
- 解釋方差得分:此指標評估數據點的變化或離散度。
- 該指標的公式如下所示:
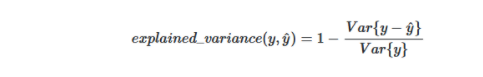
python中的示例:
- #從sklearn導入差異分數
- from sklearn.metrics import explained_variance_score
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- explained_variance_score(true_values, predicted_values)
- #output:
- 0.8525190839694656
2.最大誤差:此度量標準將計算真實值和預測值之間的最差值。
- 最大誤差的公式如下所示:
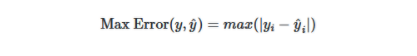
python中的示例
- from sklearn.metrics import max_error
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 8]
- max_error(true_values, predicted_values)
- #output:
- 2
3.平均絕對誤差:此度量標準計算真實值和預測值之差的平均誤差。該度量對應于l1-范數損失。
- 該指標的公式如下所示:
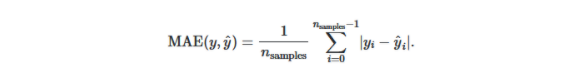
python中的示例
- from sklearn.metrics import mean_absolute_error
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- mean_absolute_error(true_values, predicted_values)
- #output:
- 0.475
3.均方誤差:此度量標準計算二次誤差或損失。
- 公式如下所示:

python中的示例
- from sklearn.metrics import mean_squared_error
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- mean_squared_error(true_values, predicted_values)
- #output:
- 0.3525
4. R平方得分:此度量標準從均值或估計量(如擬合的回歸線)計算數據的分布。通常稱為“確定系數”。
- 該指標的公式如下:
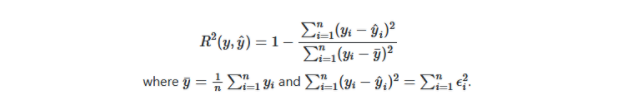
python中的示例
- from sklearn.metrics import r2_score
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- r2_score(true_values, predicted_values)
- #output:
- 0.8277862595419847
分類指標
評估分類效果的指標如下:
- 準確性得分:此度量標準計算真實值的準確性等于預測值,然后返回分數的分數,否則,如果歸一化參數為FALSE,則它將返回真實預測值的總數。
公式如下:
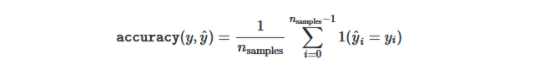
python中的示例
- from sklearn.metrics import accuracy_score
- true_values = [5, 2, 3, 6]
- predicted_values = [4, 3, 3, 6]
- accuracy_score(true_values, predicted_values)
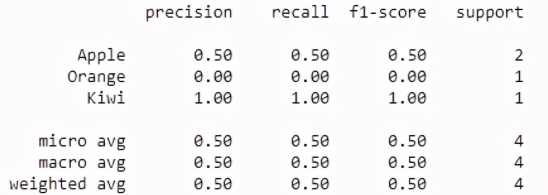
2.分類報告:此度量標準計算的報告包含分類問題的精度,召回率和F1得分。
Python范例
- from sklearn.metrics import classification_report
- true_values = [3, 4, 3, 6]
- predicted_values = [4, 3, 3, 6]
- target_names = ['Apple', 'Orange', 'Kiwi']
- print(classification_report(true_values, predicted_values, target_names=target_names))
3.鉸鏈損耗:此損耗計算數據點和模型預測點之間的平均距離。SVM算法中也使用它來獲得最大邊際。
- 公式如下所示:

python中的示例
- from sklearn import svm
- from sklearn.metrics import hinge_loss
- from sklearn.svm import LinearSVC
- #data set in x and y values
- x_values = [[3], [2]]
- y_values = [-1, 1]
- #using linear SVC model
- svm_linear = svm.LinearSVC(random_state=0)
- #fitting the model
- svm_linear.fit(x_values, y_values)
- LinearSVC(random_state=0)
- #making decision prediction
- pred_decision = svm_linear.decision_function([[-2], [3], [0.5]])
- hinge_loss([-1, 1, 1], pred_decision)
- #output:
- 1.333372678152829
結論:
這些都是從回歸和分類中評估模型性能的一些指標。分類中有基于回歸,二元類和多類指標的各種指標。
責任編輯:梁菲
來源:
今日頭條