













ElasticSearch使用規范Beta版
本文轉載自微信公眾號「Redis開發運維實戰」,作者付磊。轉載本文請聯系Redis開發運維實戰公眾號。
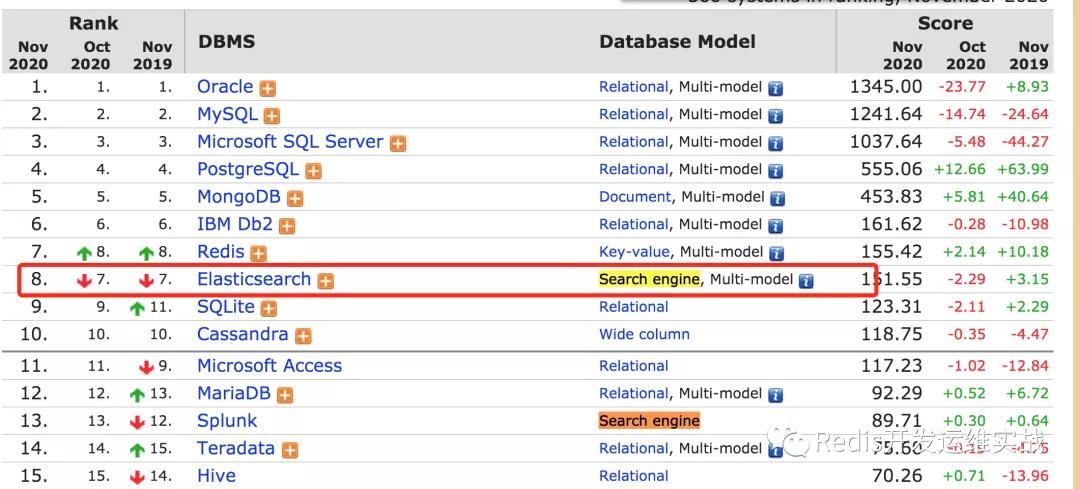
ElasticSearch除了在日志場景(監控、數據分析、debug)等場景大量使用以外,最近一年多在很多核心上的線上業務(譬如電商業務)大量使用,目前接近了5000個節點,目前在db-ranking(2020-11-24日),ElasticSearch在search-engine中常年第一:
對于MySQL、Redis這類存儲緩存許多開發同學多有很強的最佳實踐,但對于ElasticSearch的使用經驗相對模式。我個人經驗是ElasticSearch非常便于開發(譬如支持dynamic mapping)但它相對脆弱:一方面是開發同學對于其重視程度不夠(譬如沒有自己制定mapping)、另一方面它本身的一些設計(例如聚合計算都在JVM完成)導致其相對脆弱。
為此我們提供一份關于ElasticSearch的開發規范幫助ElasticSearch使用者減少一些可能碰到的坑
一、容量規劃
1. 分片(shard)容量
- 非日志型(搜索型、線上業務型)的shard容量在10~30GB(建議在10G)
- 日志型的shard容量在30~100GB(建議30G)
- 單個shard的文檔個數不能超過21億左右(Integer.MAX_VALUE - 128)
注:一個shard就是一個lucene分片,ES底層基于lucene實現。
2. 索引(index)數量
- 大索引需要拆分:增強性能,風險分散。
反例:一個10T的索引,例如按date查詢、name查詢
正例:index_name拆成多個index_name_${date}
正例:index_name按hash拆分index_name_{1,2,3,...100..}
- 提示:索引和shard數并不是越多越好,對于批量讀寫都會有性能下降,所以要綜合考慮性能和容量規劃,同時配合壓力測試,不存在真正的最優解。
3. 節點、分片、索引
一個節點管理的shard數不要超過200個
4. 示意圖
(1) 集群
(2) 節點:
(3) 索引:

(4) 分片(shard)
二、 索引mapping設計
大原則:不用默認配置和動態mapping、數據用途(類型、分詞、存儲、排序)弄清,下面是一個標準mapping:
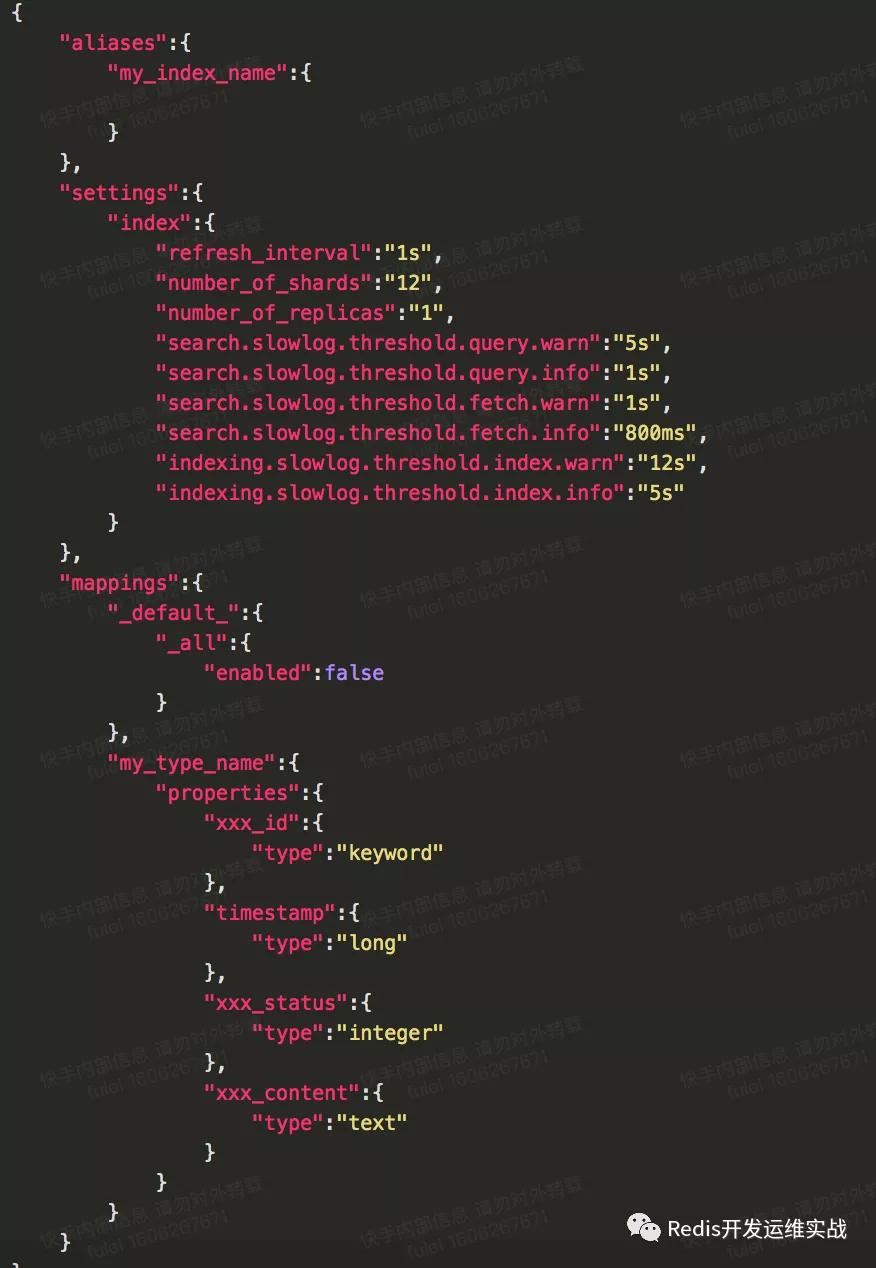
1. shard個數(number_of_shards):
參考一
2. refresh頻率(refresh_interval):
ES的定位是準實時搜索引擎,該值默認是1s,表示寫入后1秒后可被搜索到,所以這里的值取決于業務對實時性的要求,注意這里并不是越小越好,刷新頻率高也意味著對ES的開銷也大,通常業務類型在1-5s,日志型在30s-120s,如果集中導入數據可將其設置為-1,ES會自動完成數據刷新(注意完成后更改回來,否則后續會出現搜索不到數據)
3. 使用別名(aliases):不要過度依賴別名功能
正例:
- 索引名:index_name_v1
- 別名:index_name
未來重建index_name_v2索引,對于業務來說只需要換別名。
4. type個數
1個就夠了,從ES6開始只支持一個type,這個type比較雞肋,后面的版本可能會去掉。
如果一定用:針對已經使用多個type的場景,一定要保證不同type下字段盡量保持一致,否則會加大數據稀疏性,存儲與查詢性能受影響
5. 慢日志(slowlog):
一定要配置,默認不記錄慢查詢,kcc提供了grafana、kibana查詢功能。
6. 副本(number_of_replicas)
1個就夠用,副本多寫入壓力不可忽視。極端情況下:譬如批量導入數據,可以將其調整為0.
7. 字段設計
(1) text和keyword的用途必須分清:分詞和關鍵詞(確定字段是否需要分詞)
(2) 確定字段是否需要獨立存儲
(3) 字段類型不支持修改,必須謹慎。
(4) 對不需要進行聚合/排序的字段禁用doc_values
- text 類型作用:分詞,用于搜索。
- 適用于:email 內容、某產品的描述等需要分詞全文檢索的字段;
- 不適用:排序或聚合(Significant Terms 聚合例外)
- keyword 類型:無需分詞、整段完整精確匹配。
- 適用于:email 地址、住址、狀態碼、分類 tags。
(5) 不要在text做模糊搜索:
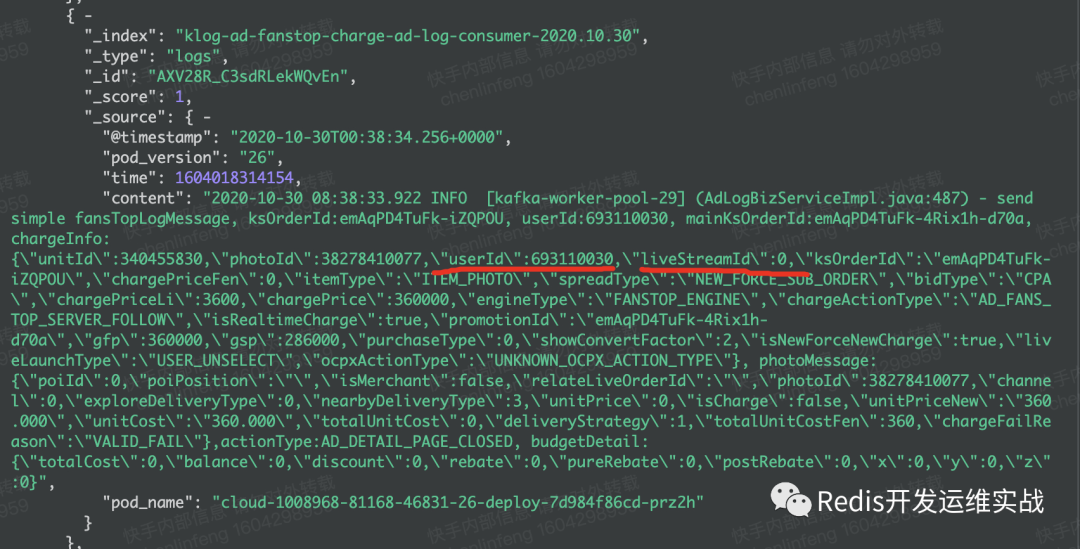
8. 設置合理的routing key(默認是id)
id不均衡:集群容量和訪問不均衡,對于分布式存儲是致命的。
9. 關閉_all
ES6.0已經去掉,對容量(索引過大)和性能(性能下降)都有影響。
10. 避免大寬表:
ES默認最大1000,但建議不要超過100.
11. text類型的字段不要使用聚合查詢。
text類型fileddata會加大對內存的占用,如果有需求使用,建議使用keyword
12.聚合查詢避免使用過多嵌套,
聚合查詢的中間結果和最終結果都會在內存中進行,嵌套過多,會導致內存耗盡
比如以下聚合就嵌套了3層,country、city和salary的結果都會保存在內存中,如果唯一值較多,就會導致內存耗盡
- {
- "aggs":{
- "country":{
- "terms":{
- "filed":"country",
- "size":10
- },
- "aggs":{
- "city":{
- "terms":{
- "filed":"city",
- "size":20
- },
- "aggs":{
- "salary":{
- "terms":{
- "filed":"salary",
- "size":20
- }
- }
- }
- }
- }
- }
- }
- }
三、違規操作
1. 原則:不要忽略設計,快就是慢,壞的索引設計后患無窮.
2. 拒絕大聚合 :ES計算都在JVM內存中完成。
3. 拒絕模糊查詢:es一大殺手
- {
- "query":{
- "wildcard":{
- "title.keyword":"*張三*"
- }
- }
- }
4. 拒絕深度分頁
ES獲取數據時,每次默認最多獲取10000條,獲取更多需要分頁,但存在深度分頁問題,一定不要使用from/Size方式,建議使用scroll或者searchAfter方式。scroll會把上一次查詢結果緩存一定時間(通過配置scroll=1m實現),所以在使用scroll時一定要保證search結果集不要太大。
5. 基數查詢
盡量不要用基數查詢去查詢去重后的數據量大小(kibana中界面上顯示是Unique Count,Distinct Count等),即少用如下的查詢:
- "aggregations": {
- "cardinality": {
- "field": "userId"
- }
- }
6. 禁止查詢 indexName-*
7. 避免使用script、update_by_query、delete_by_query,對線上性能影響較大。
四、常見問題
1. 一個索引的shard數一旦確定不能改變
2. ES不支持事務ACID特性。
3. reindex:
reindex可以實現索引的shard變更,但代價非常大:速度慢、對性能有影響,所以好的設計和規劃更重要
五、grafana使用規范
1.查詢范圍不要太大,建議在3h以內
如下查詢7d,數據量巨大,嚴重影響集群查詢性能
2. 拒絕多層嵌套,不要超過2層
如下圖中進行了4層嵌套,每層嵌套的結果都緩存在內存中,導致內存崩潰
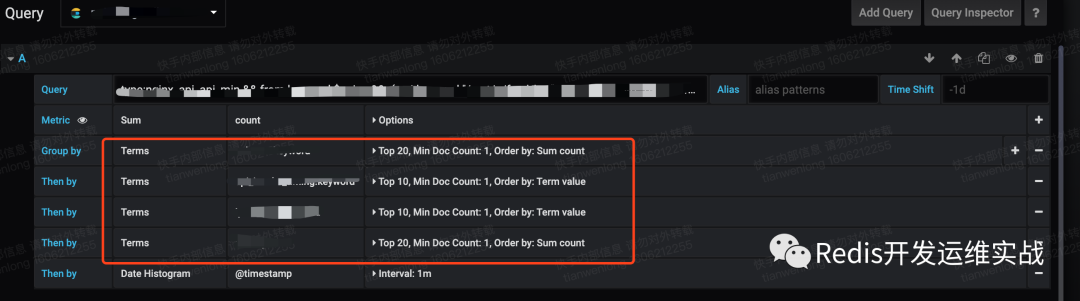
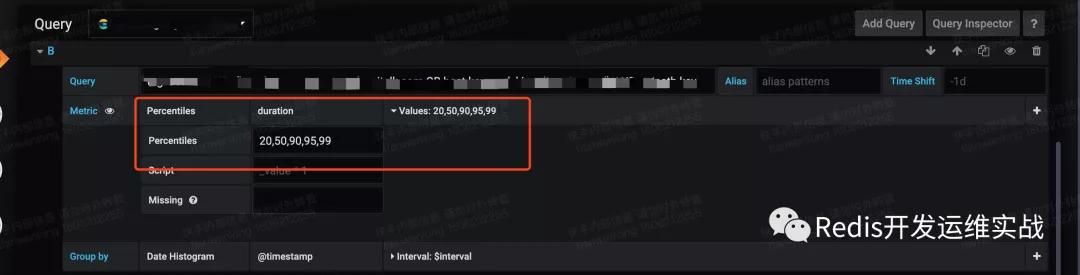
3. 拒絕分時查詢
分位查詢相當于一種分桶聚合方式,分的桶越多,帶來的CPU計算量越大
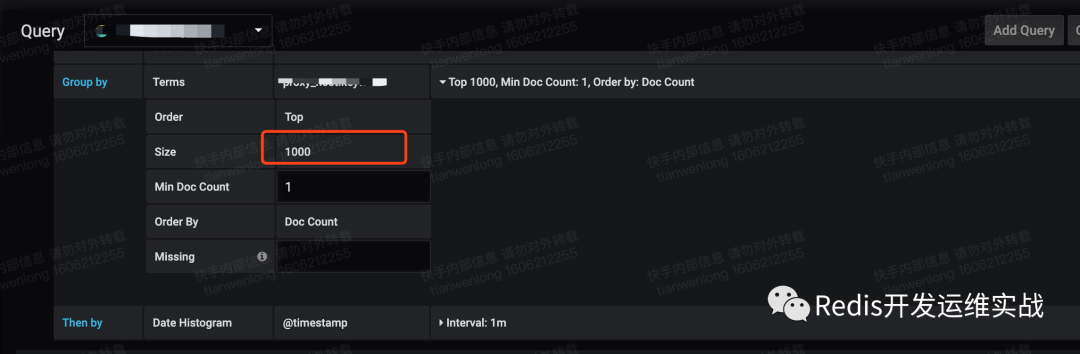
4. 拒絕TOP>100查詢
top查詢是在聚合的基礎上再進行排序,如果top太大,cpu的計算量和耗費的內存都會導致查詢瓶頸
5. 拒絕正則匹配查詢











