NameNode是用了什么神秘技術來支撐元數據百萬并發讀寫的
本文轉載自微信公眾號「KK架構師」,作者wangkai。轉載本文請聯系KK架構師公眾號。
本文大綱
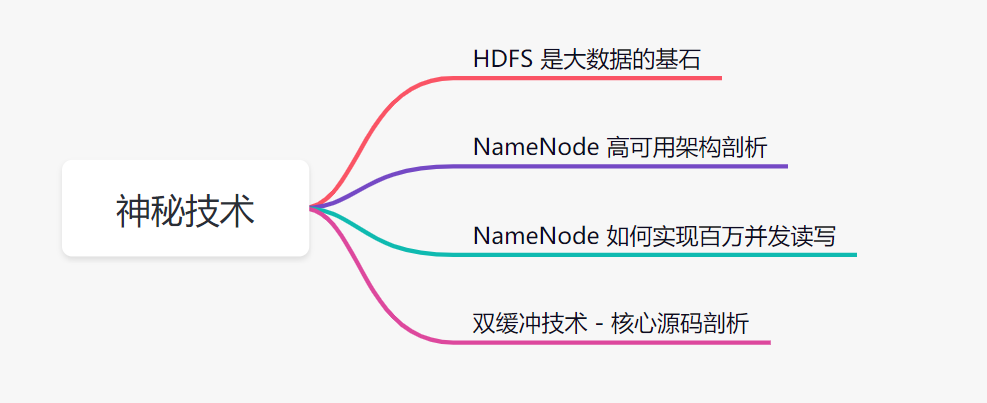
一、HDFS 是大數據的基石
我們都知道,HDFS 是大數據存儲的基石,所有的離線數據都存儲在 HDFS 上,而 NameNode 是存儲所有元數據的地方(所謂元數據就是描述數據的數據,比如文件的大小,文件都存儲在哪些 DataNode 上,文件在目錄樹的位置等),所以 NameNode 便成為了 HDFS 最關鍵的部分。
在離線數倉中,會存在很多離線任務,這些離線任務都要往 HDFS 寫數據,每次寫數據都會經過 NameNode 來保存元數據信息,那么 NameNode 勢必會承擔非常多的請求。NameNode 作為 HDFS 的核心,肯定自身要保證高可用,數據不能一直在內存中,要寫到磁盤里。
所以一個關鍵的問題來了,NameNode 是用了什么神秘的技術,在保證自身高可用的同時,還能承擔巨額的讀寫請求?
二、NameNode 高可用是如何實現的
下面直接來一個 NameNode 高可用的架構圖:
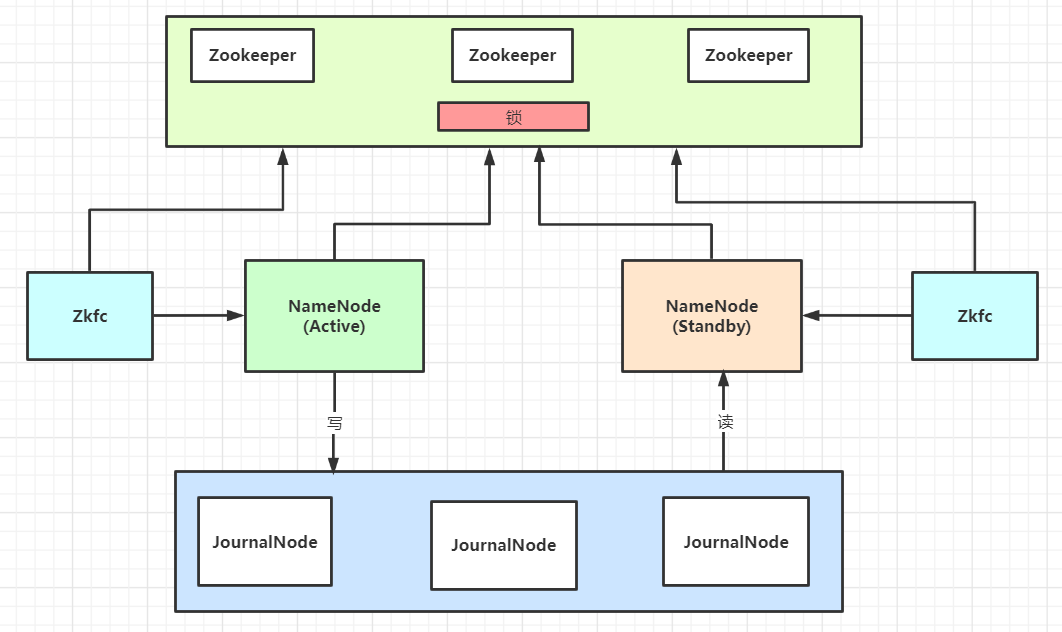
然后解釋下如何保證高可用的:
(1)NameNode 只有一個時的單點故障問題
如果我們只部署了一個 NameNode,那么這個 NameNode 是有單點故障的問題的。如何解決,再加一個 NameNode 即可;
(2)當有兩個 NameNode ,切換時,數據如何保持同步
兩個 NameNode 一起工作,某一個 NameNode 掛掉了,另一個 NameNode 接替工作,這件事成立的必要前提是,兩個 NameNode 的數據得時時刻刻保持一致。
那么如何保持數據一致,是不是可以在兩個 NameNode 之間搞個共享的文件系統?仔細想想也不行,這樣的話,單點故障問題就轉移到這個文件系統上了。
(3)使用多節點的 JournalNode 作為主備 NameNode 的數據同步介質
這里引入了 JournalNode 集群,JournalNode 的每個節點的數據都是一樣的,并且時刻保持一致。并且只要超過半數的節點存活,整個 JournalNode 集群都可以正常提供服務。
所以,一般會使用奇數個節點來搭建。(為什么一般不用偶數個呢?因為 3 個節點構成的集群,可以容忍掛掉一臺機器;而 4 個節點構成的集群,也只能容忍掛掉一臺機器。同樣是只能掛掉一臺,為何不選 3 個節點的呢,還能節省資源)。
使用 JournalNode 集群,一個 NameNode 實時的往集群寫,另一個 NameNode 也實時的讀集群數據,這樣兩個 NameNode 數據就可以保持一致了。
(4)一個 NameNode 掛掉,另一個 NameNode 如何立馬感知并接替工作
首先不能人工參與切換。那如何實時監聽呢?
首先要再引入一個關鍵組件:Zookeeper。當兩個 NameNode 同時啟動后,他們都會去 Zookeeper 上注冊,誰注冊成功了,誰就能獲得鎖,成為 Active 狀態的 NameNode。
另外還需要一個組件:ZKFC,它會實時監控 Zookeeper 進程狀態,并且會以心跳的方式實時的告訴 Zookeeper NameNode 的狀態。如果一個 NameNode 進程掛了,就會把 Zookeeper 上的鎖給另外一個 NameNode,讓它成為 Active 的來工作。
三、NameNode 如何既高可用,還能高并發
1、雙緩沖技術
NameNode 為了實現高可用,首先自己內存里的數據需要寫到磁盤,然后還需要往 JournalNode 里寫數據。
所以既然要寫磁盤,還是往兩個地方寫磁盤,那必然性能會跟不上的。
所以這里 NameNode 引入了一個技術,也是本篇文章的重點:雙緩沖技術。
雙緩沖的設計理念如下圖:
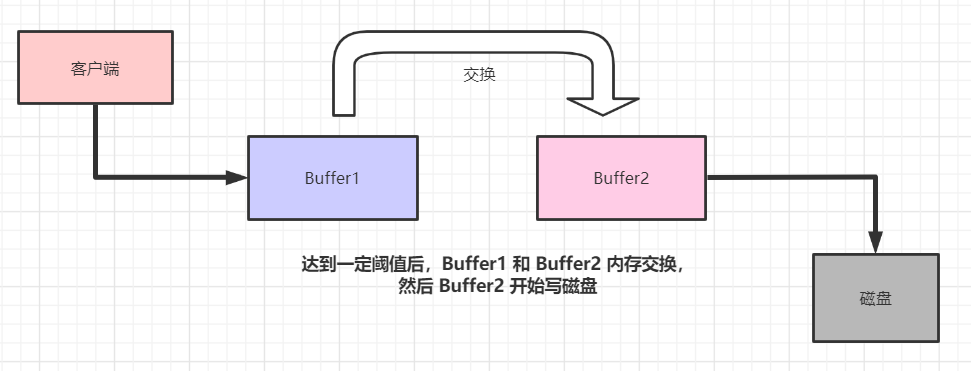
客戶端不是直接寫磁盤,而是往一個內存結構(Buffer1)里面寫數據。當 Buffer1 達到一定閾值后,Buffer 1 和 Buffer 2 交換內存數據。此時 Buffer1 數據為空,Buffer2 開始在后臺默默寫磁盤。
這樣的好處很明顯的,前端只需要進行內存寫 Buffer1 就行,性能特別高;而 Buffer2 在后臺默默的同步日志到磁盤即可。
這樣磁盤寫,就轉化成為了內存寫,速度大大提高了。
2、如何實現雙緩沖
然而,在真實環境不只一個客戶端是這樣子的:
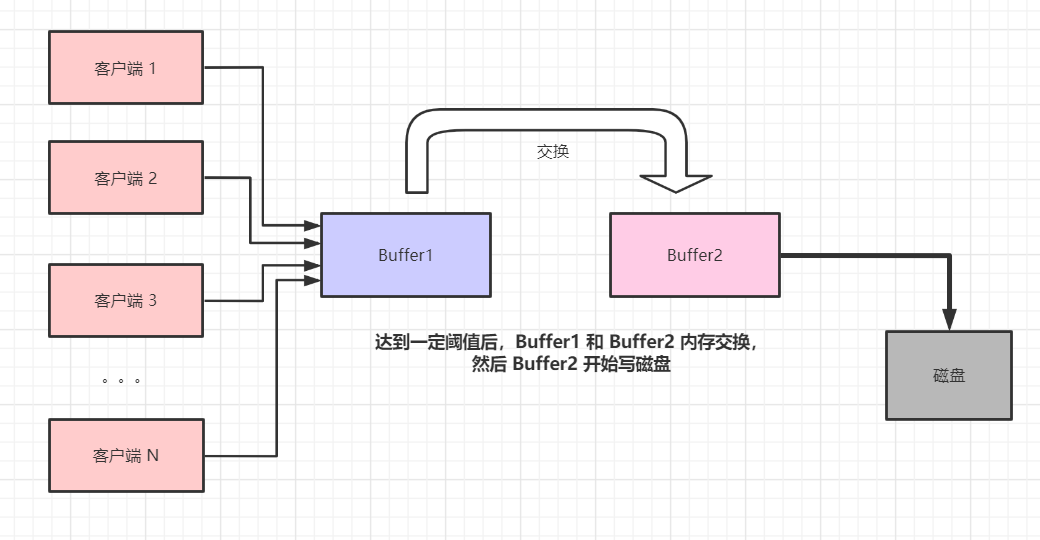
大數據情況下是 N 個客戶端同時并發寫的,在高并發的情況下,我們必然要去協調多個線程動作的一致性,比如往 Buffer1 的寫動作,Buffer1 與 Buffer2 數據交換的動作,Buffer2 寫磁盤的動作。
那么我們該如何實現這樣一個巧妙的雙緩沖呢?下面的代碼是我從 Hadoop 源碼里抽離出來的關鍵實現:
- package org.apache.hadoop;
- import java.util.LinkedList;
- public class FSEditLog2 {
- private long txid=0L;
- private DoubleBuffer editLogBuffer=new DoubleBuffer();
- //是否正在刷寫磁盤
- private volatile Boolean isSyncRunning = false;
- private volatile Boolean isWaitSync = false;
- private volatile Long syncMaxTxid = 0L;
- //每個線程都對應自己的一個副本
- private ThreadLocal<Long> localTxid=new ThreadLocal<Long>();
- public void logEdit(String content){//mkdir /a
- synchronized (this){//加鎖的目的就是為了事務ID的唯一,而且是遞增
- txid++;
- localTxid.set(txid);
- EditLog log = new EditLog(txid, content);
- editLogBuffer.write(log);
- }
- logSync();
- }
- private void logSync(){
- synchronized (this){
- if(isSyncRunning){ //是否有人正在把數據同步到磁盤上面
- long txid = localTxid.get();
- if(txid <= syncMaxTxid){
- //直接return,不接著干了?
- return;
- }
- if(isWaitSync){
- return;
- }
- isWaitSync = true;
- while(isSyncRunning){
- try {
- wait(2000);
- }catch (Exception e){
- e.printStackTrace();
- }
- }
- isWaitSync = false;
- }
- editLogBuffer.setReadyToSync();
- if(editLogBuffer.syncBuffer.size() > 0) {
- syncMaxTxid = editLogBuffer.getSyncMaxTxid();
- }
- isSyncRunning = true;
- } //釋放鎖
- editLogBuffer.flush();
- synchronized (this) {
- isSyncRunning = false;
- notify();
- } //釋放鎖
- }
- /**
- * 把日志抽象成類
- */
- class EditLog{
- //順序遞增
- long txid;
- //操作內容 mkdir /a
- String content;
- //構造函數
- public EditLog(long txid,String content){
- this.txid = txid;
- this.content = content;
- }
- //為了測試方便
- @Override
- public String toString() {
- return "EditLog{" +
- "txid=" + txid +
- ", content='" + content + '\'' +
- '}';
- }
- }
- /**
- * 雙緩存方案
- */
- class DoubleBuffer{
- //內存1
- LinkedList<EditLog> currentBuffer = new LinkedList<EditLog>();
- //內存2
- LinkedList<EditLog> syncBuffer= new LinkedList<EditLog>();
- /**
- * 把數據寫到當前內存1
- * @param log
- */
- public void write(EditLog log){
- currentBuffer.add(log);
- }
- /**
- * 交換內存
- */
- public void setReadyToSync(){
- LinkedList<EditLog> tmp= currentBuffer;
- currentBuffer = syncBuffer;
- syncBuffer = tmp;
- }
- /**
- * 獲取內存2里面的日志的最大的事務編號
- * @return
- */
- public Long getSyncMaxTxid(){
- return syncBuffer.getLast().txid;
- }
- /**
- * 刷寫磁盤
- */
- public void flush(){
- for(EditLog log:syncBuffer){
- //把數據寫到磁盤上
- System.out.println("存入磁盤日志信息:"+log);
- }
- //把內存2里面的數據要清空
- syncBuffer.clear();
- }
- }
- }
主要的業務邏輯就是 40 行,但是真的很巧妙。
1、EditLog
我們先看這個 EditLog 內部類,這是對 EditLog 日志的一個封裝,就兩個屬性 txid 和 content,分別是日志的事務id(保證唯一性)和 內容。
2、DoubleBuffer
再看這個 DoubleBuffer 雙緩沖類,很簡單,就是在內存里面維護了兩個有序的 LinkedList,分別是當前寫編輯日志的緩沖和同步到磁盤的緩沖,其中的元素就是 EditLog 類。
write 方法就是把一條編輯日志寫到當前緩沖里。
setReadyToSync 方法,就是交換兩個緩沖,也是最簡單的剛學習 Java 就學習過的兩個變量交換值的方法。
getSyncMaxTxid 方法,獲得正在同步的那個緩沖去里的最大的事務id。
flush 方法,遍歷同步的緩沖的每一條編輯日志,寫到磁盤,并最終清空緩沖區內容。
3、主類的一些屬性說明
(1)全局的事務id
private long txid=0L;
(2)雙緩沖結構
private DoubleBuffer editLogBuffer=new DoubleBuffer();
(3)控制變量
private volatile Boolean isSyncRunning = false; // 是否正在同步數據到磁盤
private volatile Boolean isWaitSync = false; // 是否有線程在等待同步數據到磁盤完成
private volatile Long syncMaxTxid = 0L; // 當前同步的最大日志事務id
private ThreadLocallocalTxid=new ThreadLocal(); // 每個線程的線程副本,用來放本線程當前寫入的日志事務id
(4)主邏輯 logEdit 方法
這個方法是對外暴露的方法,客戶端往雙緩沖寫數據就是用的這個方法。
假設當前有一個線程1 進到了 logEdit 方法,首先直接把當前類實例加鎖,避免別的線程進來,以此來保證編輯日志事務id的唯一自增性。
- // 全局事務遞增
- txid++;
- // 往線程本身的變量里設置事務id值
- localTxid.set(txid);
- // 構造 EditLog 變量
- EditLog log = new EditLog(txid, content);
- // 寫入當前的 Buffer
- editLogBuffer.write(log);
當它執行完了這些之后,釋放鎖,開始執行 logSync() 方法。此時由于釋放了鎖,于是很多線程開始拿到鎖,進入了這個方法中。
假設有五個線程進來了分別寫了一條日志,于是現在雙緩沖是這樣子的:
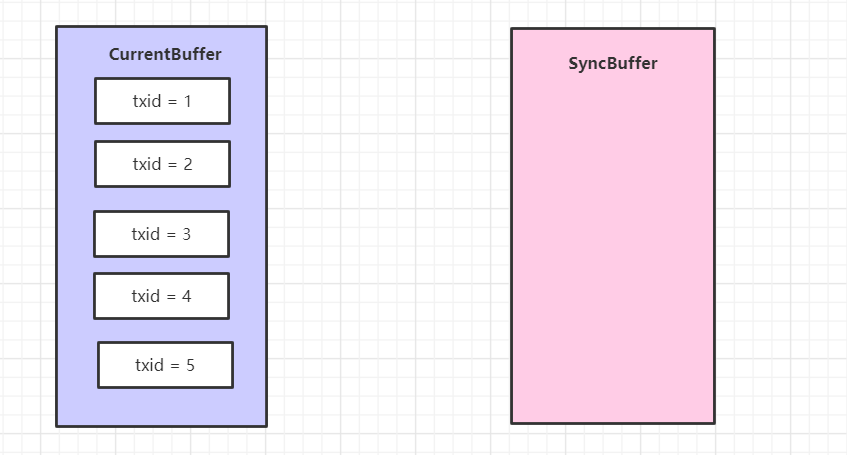
好,然后線程1 開始進入 logSync 方法,第一步就是使用當前類的實例加了鎖,保證只有一個線程進來。
檢查 isSyncRunning 變量是否為 true,目前是 false,跳過這個方法。
開始執行這個 editLogBuffer.setReadyToSync(); 方法,于是雙緩沖的數據直接被交換了。
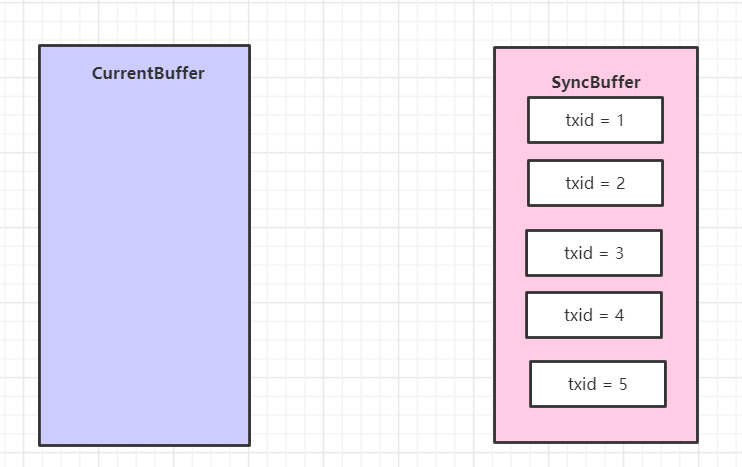
然后獲得了全局最大的id,當前是 5,賦值給了 syncMaxTxid 變量
- if(editLogBuffer.syncBuffer.size() > 0) {
- syncMaxTxid = editLogBuffer.getSyncMaxTxid();
- }
然后 isSyncRunning = true; 把這個變量置為 true,表示正在同步數據到磁盤。此時釋放鎖。
然后 線程 1 開始執行數據同步到磁盤的動作:editLogBuffer.flush() ,這個動作肯定耗費的時間比較久,基本是在 ms 級別。
此時我們假設 線程2 爭搶到了鎖,進入到了 logSync 方法。
- // 線程2 判斷 是否有人正在把數據同步到磁盤上面,這個值被線程 1 改為 true 了
- // 進入到 if 方法
- if(isSyncRunning){
- // 獲得到自己線程的事務id,為 2
- long txid = localTxid.get();
- // 2 是否小于 5 ?小于,直接返回,因為此時 5 已經正在被同步到磁盤了
- if(txid <= syncMaxTxid){
- return;
- }
- if(isWaitSync){
- return;
- }
- isWaitSync = true;
- while(isSyncRunning){
- try {
- wait(2000);
- }catch (Exception e){
- e.printStackTrace();
- }
- }
- isWaitSync = false;
- }
線程2 由于自身的編輯日志的事務id 小于當前正在同步的最大的事務id,所以直接返回了,然后線程3 ,線程4,線程5 進來都是這樣,直接 return 返回。
假設線程6 此時進來,當前雙緩沖狀態是這樣的
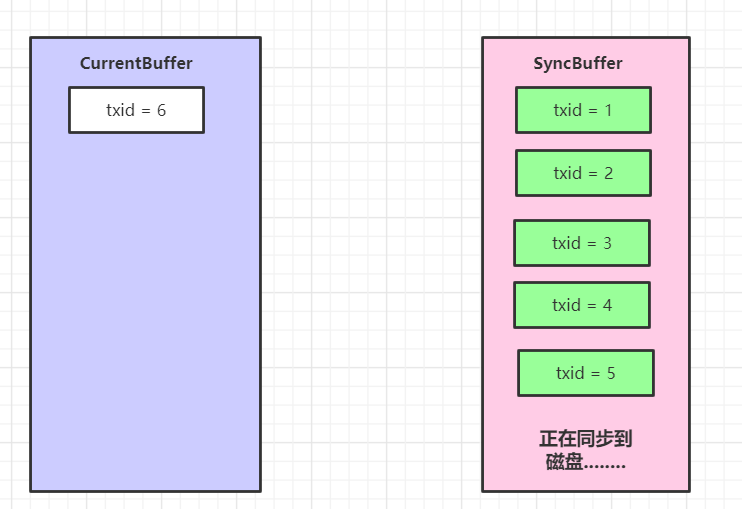
下面線程 6 干的活,參考下面代碼里的注釋:
- // 線程6 判斷是否有人正在把數據同步到磁盤上面,這個值被線程 1 改為 true 了
- // 進入到 if 方法
- if(isSyncRunning){
- // 獲得到自己線程的事務id,為 6
- long txid = localTxid.get();
- // 6 是否小于 5 ,不小于繼續執行
- if(txid <= syncMaxTxid){
- return;
- }
- // 這個值為 false,繼續執行
- if(isWaitSync){
- return;
- }
- // 把 isWaitSync 設置為 true
- isWaitSync = true;
- // 這個值被線程1置為了 true,所以這里在死循環
- while(isSyncRunning){
- try {
- // 等待 2s,wait 會釋放鎖,同時線程 6 進入睡眠中
- wait(2000);
- }catch (Exception e){
- e.printStackTrace();
- }
- }
- isWaitSync = false;
- }
可以看到 線程 6 在 while 循環里無限等待數據同步到磁盤完畢。然后由于線程 6 把 isWaitSync 值改為了 true,線程 6 在等待期間釋放鎖,被其他線程搶到之后,其他線程由于 isWaitSync 為true,直接返回了。
當過了一會兒,線程1 把第二個 Buffer 同步到磁盤完畢后,線程1 會執行這些代碼
- synchronized (this) {
- isSyncRunning = false;
- notify();
- } //釋放鎖
把 isSyncRunning 變量置為 false,同時調用 notify(),通知線程 6 ,你可以繼續參與鎖的競爭了。
然后線程6 ,從 wait 中醒來,重新參與鎖競爭,繼續執行接下來的代碼。此時 isSyncRunning 已經為 false,所以它跳出了 while 循環,把 isWaitSync 置為了 false。
然后它開始執行:交換緩沖區,給最大的事務id(此時為6 )賦值,把 isSyncRunning 賦值為 true。
- editLogBuffer.setReadyToSync();
- if(editLogBuffer.syncBuffer.size() > 0) {
- syncMaxTxid = editLogBuffer.getSyncMaxTxid();
- }
- isSyncRunning = true;
執行完了之后,釋放鎖,開始執行Buffer2 的同步。然后所有的線程就按照上面的方式有序的工作。
這段幾十行的代碼很精煉,值得反復推敲,總結下來如下:
(1)寫緩沖到內存 和 同步數據到磁盤分開,互不影響和干擾;
(2)使用 synchronize ,wait 和 notify 來保證多線程有序進行工作;
(3)當在同步數據到磁盤中的時候,其他爭搶到鎖進來準備同步數據的線程只能等待;
(4)線程使用 ThreadLocal 變量,來記錄自身當前的事務id,如果小于當前正在同步的最大事務id,則不同步;
(5)有線程在等待同步數據的時候,其他線程寫完 editLog 到內存后直接返回;
四、最后的總結
本文詳細探討了 HDFS 在大數據中基石的地位,以及如何保障 NameNode 高可用的運行。
NameNode 在高可用運行時,同時是如何保證高并發讀寫操作的。雙緩沖在其中起到了核心的作用,把寫數據和同步數據到磁盤分離開,互不影響。
同時我們還剝離了一段核心雙緩沖的實現代碼,仔細分析了實現原理。這短短的幾十行代碼,可謂綜合利用了多線程高并發的知識,耐人尋味。