













盤點URLError和HTTPError異常處理方式
一、前言
本文主要說URLError 還有 HTTPError,以及一些處理方式。
二、URLError
1. 解釋下 URLError 可能產生的3個原因:
- # 1. 網絡無連接,即本機無法上網。
- # 2. 連接不到特定的服務器。
- # 3. 服務器不存在。
2. 案例
例:
在代碼中,需要用 try-except 語句來包圍并捕獲相應的異常。
- # coding:UTF8
- import urllib.request
- request = urllib.request.urlopen("http://www.baidu.com")
- try:
- urllib.request.urlopen(request)
- print("[Errno 11004] getaddrinfo failed")
- except urllib.URLError as e:
- print(e.reason)
利用了 urlopen 方法訪問了一個不存在的網址。
運行結果:

注:
它說明了錯誤代號是11004,錯誤原因是 getaddrinfo failed。
三、HTTPError
HTTPError 是 URLError 的子類,在利用 urlopen 方法發出一個請求時,服務器上都會對應一個應答對象 response,其中它包含一個數字”狀態碼”。
例:
捕獲的異常是 HTTPError,它會帶有一個 code 屬性,就是錯誤代號,另外又打印了 reason 屬性,這是它的父類 URLError 的屬性。
- import urllib2
- req = urllib2.Request('http://blog.csdn.net/cqcre')
- try:
- urllib2.urlopen(req)
- except urllib2.HTTPError, e:
- print e.code
- print e.reason
運行結果:
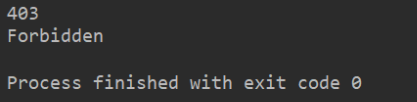
1. 代碼解析
錯誤代號是 403,錯誤原因是 Forbidden,說明服務器禁止訪問。
知道,HTTPError 的父類是 URLError,根據編程經驗,父類的異常應當寫到子類異常的后面,如果子類捕獲不到,那么可以捕獲父類的異常,
2. 優化代碼
- import urllib2
- req = urllib2.Request('http://blog.csdn.net/cqcre')
- try:
- urllib2.urlopen(req)
- except urllib2.HTTPError, e:
- print e.code
- except urllib2.URLError, e:
- print e.reason
- else:
- print "OK"

如果捕獲到了 HTTPError,則輸出 code,不會再處理 URLError 異常。如果發生的不是HTTPError,則會去捕獲 URLError 異常,輸出錯誤原因。
另外還可以加入 hasattr 屬性提前對屬性進行判斷,代碼改寫如下
- import urllib2
- req = urllib2.Request('http://blog.csdn.net/cqcre')
- try:
- urllib2.urlopen(req)
- except urllib2.URLError, e:
- if hasattr(e,"code"):
- print e.code
- if hasattr(e,"reason"):
- print e.reason
- else:
- print "OK"
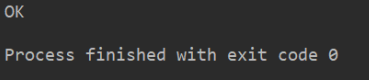
3. 異常處理方法
首先對異常的屬性進行判斷,以免出現屬性輸出報錯的現象。
假如 response 是一個”重定向”,需定位到別的地址獲取文檔,urllib2 將對此進行處理。
注 :
HTTPError 實例產生后會有一個 code 屬性,這就是是服務器發送的相關錯誤號。
因為 urllib2 可以為處理重定向,也就是 3 開頭的代號可以被處理,并且 100-299 范圍的號碼指示成功,所以只能看到 400-599 的錯誤號碼。
四、總結
本文基于基礎,通過案例的分析,代碼的展示。解決在實際應用中,對于URLError空異常的處理方式。介紹了兩種主要的異常錯誤。以及提供了相應錯誤的解決方案處理方法。
歡迎大家積極嘗試,有時候看到別人實現起來很簡單,但是到自己動手實現的時候,總會有各種各樣的問題,切勿眼高手低,勤動手,才可以理解的更加深刻。
使用語言,能夠讓讀者更清晰,更直觀的理解文章內容。代碼很簡單,希望對學習有幫助。






















