CPU比GPU訓(xùn)練神經(jīng)網(wǎng)絡(luò)快十幾倍,英特爾:別用矩陣運算了
在深度學(xué)習(xí)與神經(jīng)網(wǎng)絡(luò)領(lǐng)域,研究人員通常離不開 GPU。得益于 GPU 極高內(nèi)存帶寬和較多核心數(shù),研究人員可以更快地獲得模型訓(xùn)練的結(jié)果。與此同時,CPU 受限于自身較少的核心數(shù),計算運行需要較長的時間,因而不適用于深度學(xué)習(xí)模型以及神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。
但近日,萊斯大學(xué)、螞蟻集團和英特爾等機構(gòu)的研究者發(fā)表了一篇論文,表明了在消費級 CPU 上運行的 AI 軟件,其訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)的速度是 GPU 的 15 倍。這篇論文已被 MLSys 2021 會議接收。
論文鏈接:
https://proceedings.mlsys.org/paper/2021/file/3636638817772e42b59d74cff571fbb3-Paper.pdf
論文通訊作者、萊斯大學(xué)布朗工程學(xué)院的計算機科學(xué)助理教授 Anshumali Shrivastava 表示:「訓(xùn)練成本是 AI 發(fā)展的主要瓶頸,一些公司每周就要花費數(shù)百萬美元來訓(xùn)練和微調(diào) AI 工作負載。」他們的這項研究旨在解決 AI 發(fā)展中的訓(xùn)練成本瓶頸。
Anshumali Shrivastava。
研究動機及進展
深度神經(jīng)網(wǎng)絡(luò)(DNN)是一種強大的人工智能,在某些任務(wù)上超越了人類。DNN 訓(xùn)練通常是一系列的矩陣乘法運算,是 GPU 理想的工作負載,速度大約是 CPU 的 3 倍。
如今,整個行業(yè)都專注于改進并實現(xiàn)更快的矩陣乘法運算。研究人員也都在尋找專門的硬件和架構(gòu)來推動矩陣乘法,他們甚至在討論用于特定深度學(xué)習(xí)的專用硬件 - 軟件堆棧。
Shrivastava 領(lǐng)導(dǎo)的實驗室在 2019 年做到了這一點,將 DNN 訓(xùn)練轉(zhuǎn)換為可以用哈希表解決的搜索問題。他們設(shè)計的亞線性深度學(xué)習(xí)引擎(sub-linear deep learning engine, SLIDE)是專門為運行在消費級 CPU 上而設(shè)計的,Shrivastava 和英特爾的合作伙伴在 MLSys 2020 會議上就公布了該技術(shù)。他們表示,該技術(shù)可以超越基于 GPU 的訓(xùn)練。
在 MLSys 2021 大會上,研究者探討了在現(xiàn)代 CPU 中,使用矢量化和內(nèi)存優(yōu)化加速器是否可以提高 SLIDE 的性能。
論文一作、萊斯大學(xué) ML 博士生 Shabnam Daghaghi 表示:「基于哈希表的加速已經(jīng)超越了 GPU。我們利用這些創(chuàng)新進一步推動 SLIDE,結(jié)果表明即使不專注于矩陣運算,也可以利用 CPU 的能力,并且訓(xùn)練 AI 模型的速度是性能最佳專用 GPU 的 4 至 15 倍。」
Shabnam Daghaghi。
此外,論文二作、萊斯大學(xué)計算機科學(xué)與數(shù)學(xué)本科生 Nicholas Meisburger 認為,CPU 仍然是計算領(lǐng)域最普遍的硬件,其對 AI 的貢獻無可估量。
技術(shù)細節(jié)
在本論文中,該研究重新了解了在兩個現(xiàn)代 Intel CPU 上的 SLIDE 系統(tǒng),了解 CPU 在訓(xùn)練大型深度學(xué)習(xí)模型方面的真正潛力。該研究允許 SLIDE 利用現(xiàn)代 CPU 中的矢量化、量化和一些內(nèi)存優(yōu)化。與未優(yōu)化的 SLIDE 相比,在相同的硬件上,該研究的優(yōu)化工作帶來了 2-7 倍的訓(xùn)練時間加速。
SLIDE 的工作流程包括:初始化、前向-反向傳播和哈希表更新。下圖 1 為前向-反向傳播工作流程圖:
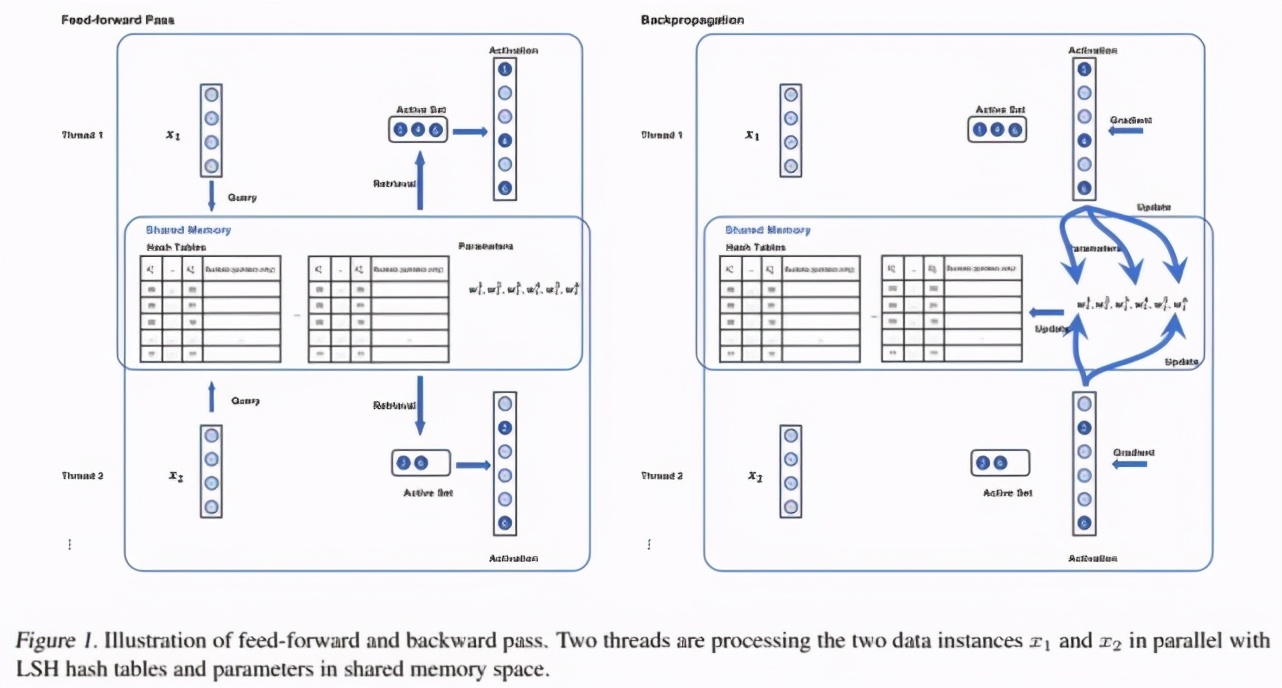
前向和后向傳播示意圖。
該研究專注于大規(guī)模評估,其中所需的神經(jīng)網(wǎng)絡(luò)擁有數(shù)億個參數(shù)。在兩臺 Intel CPU 上比較了優(yōu)化的 SLIDE,分別是 Cooper Laker 服務(wù)器(CPX)和 Cascade Lake 服務(wù)器(CLX),并與以下以下 5 個基準(zhǔn)進行了對比:
1)V100 GPU上的 full-softmax tensorflow 實現(xiàn);
2) CPX 上的 full-softmax tensorflow 實現(xiàn);
3)CLX 上的 full-softmax tensorflow 實現(xiàn);
4)CPX 上的 Naive SLIDE;
5)CLX 上的 Naive SLIDE。
其中,CPX 是英特爾第三代至強可擴展處理器,支持基于 AVX512 的 BF16 指令。CLX 版本更老,不支持 BF16 指令。
研究者在三個真實的公共數(shù)據(jù)集上評估了框架和其他基準(zhǔn)。Amazon670K 是用于推薦系統(tǒng)的 Kaggle 數(shù)據(jù)集;WikiLSH-325K 數(shù)據(jù)集和 Text8 是 NLP 數(shù)據(jù)集。詳細統(tǒng)計數(shù)據(jù)見下表 1:

對于 Amazon-670K 和 WikiLSH-325K,研究者使用了一個標(biāo)準(zhǔn)的全連接神經(jīng)網(wǎng)絡(luò),隱藏層大小為 128,其中輸入和輸出都是多個熱編碼向量。對于 Text8,該研究使用標(biāo)準(zhǔn) word2vec 語言模型,隱藏層大小為 200,其中輸入和輸出分別是一個熱編碼向量和多個熱編碼向量。
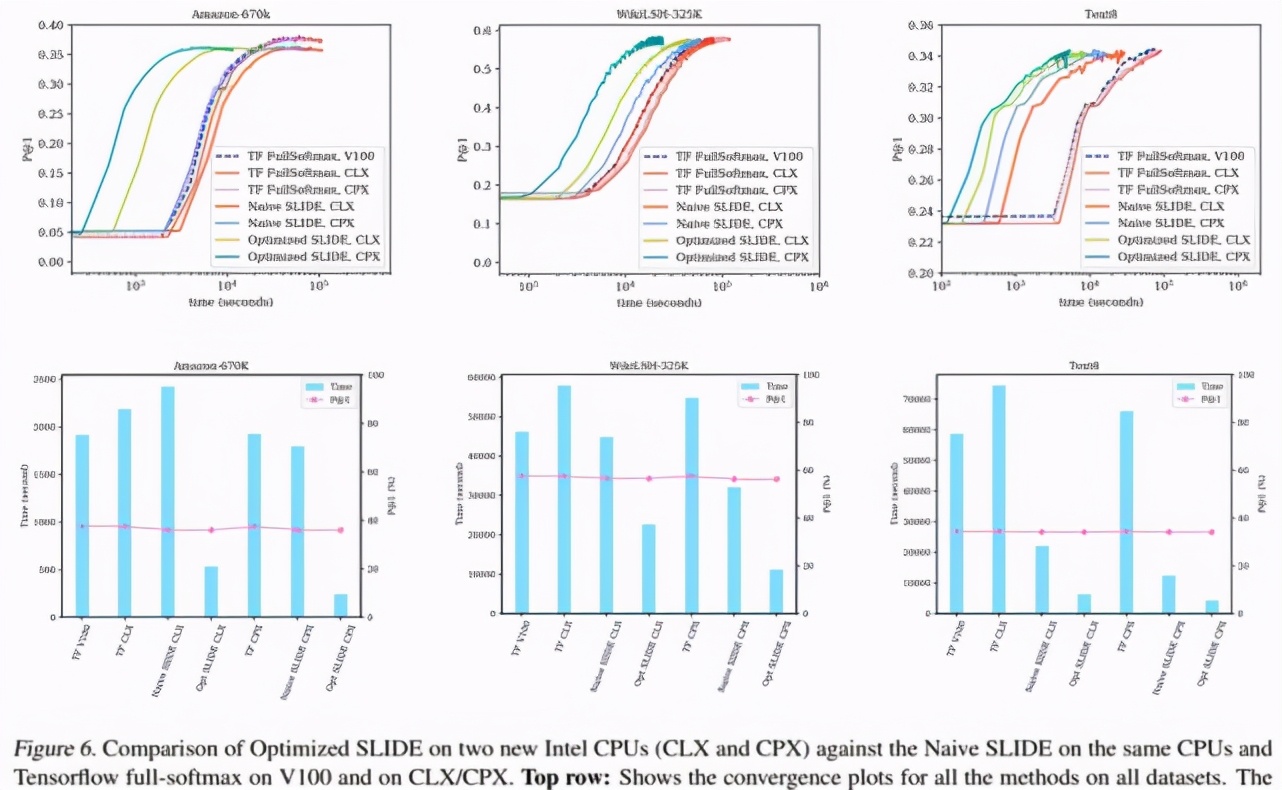
下圖 6 第一行代表所有數(shù)據(jù)集的時間收斂圖,結(jié)果顯示了該研究提出的優(yōu)化 SLIDE 在 CPX 和 CLX(深綠色和淺綠色)上訓(xùn)練時間優(yōu)于其他基準(zhǔn) 。圖 6 的底部行顯示了所有數(shù)據(jù)集的柱狀圖。
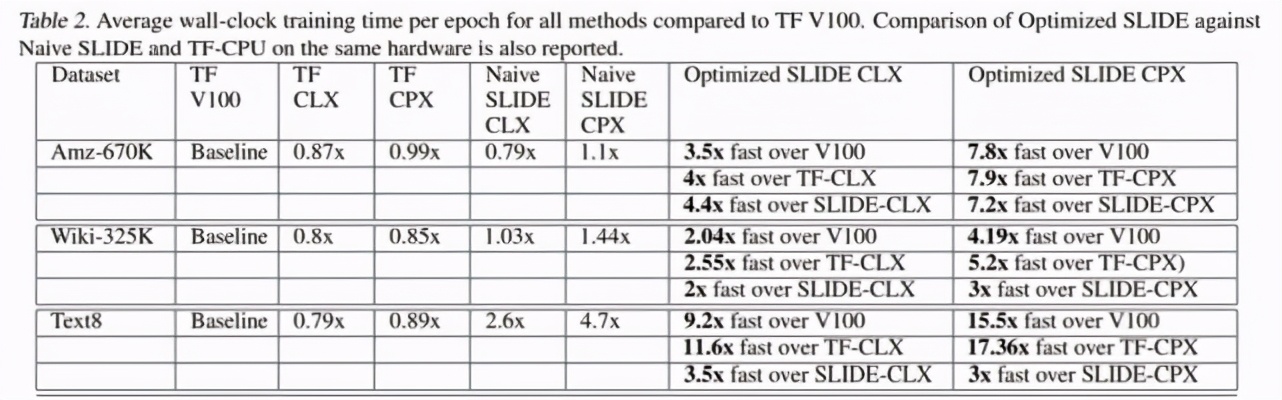
下表 2 給出了三個數(shù)據(jù)集上的詳細數(shù)值結(jié)果:
下表 3 中,研究者展示了 BF16 指令對每個 epoch 平均訓(xùn)練時間的影響。結(jié)果表明,在 Amazon-670K 和 WikiLSH325K 上,激活和權(quán)重中使用 BF16 指令分別將性能提升了 1.28 倍和 1.39 倍。但是,在 Text8 上使用 BF16 沒有產(chǎn)生影響。

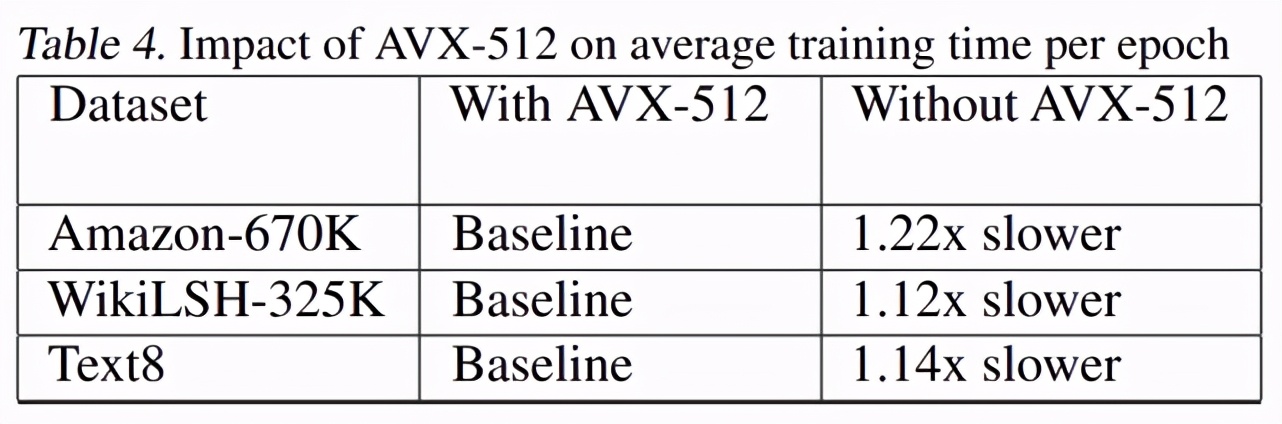
下表 4 展示了有無 AVX-512 時,優(yōu)化 SLIDE 在三個數(shù)據(jù)集上的每個 epoch 平均訓(xùn)練時間對比。結(jié)果表明,AVX-512 的矢量化將平均訓(xùn)練時間減少了 1.2 倍。