使用uuid作為數據庫主鍵,被技術總監懟了一頓!
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲。轉載本文請聯系Java極客技術公眾號。
一、摘要
在日常開發中,數據庫中主鍵id的生成方案,主要有三種
數據庫自增ID
采用隨機數生成不重復的ID
采用jdk提供的uuid
對于這三種方案,我發現在數據量少的情況下,沒有特別的差異,但是當單表的數據量達到百萬級以上時候,他們的性能有著顯著的區別,光說理論不行,還得看實際程序測試,今天小編就帶著大家一探究竟!
二、程序實例
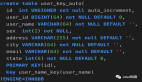
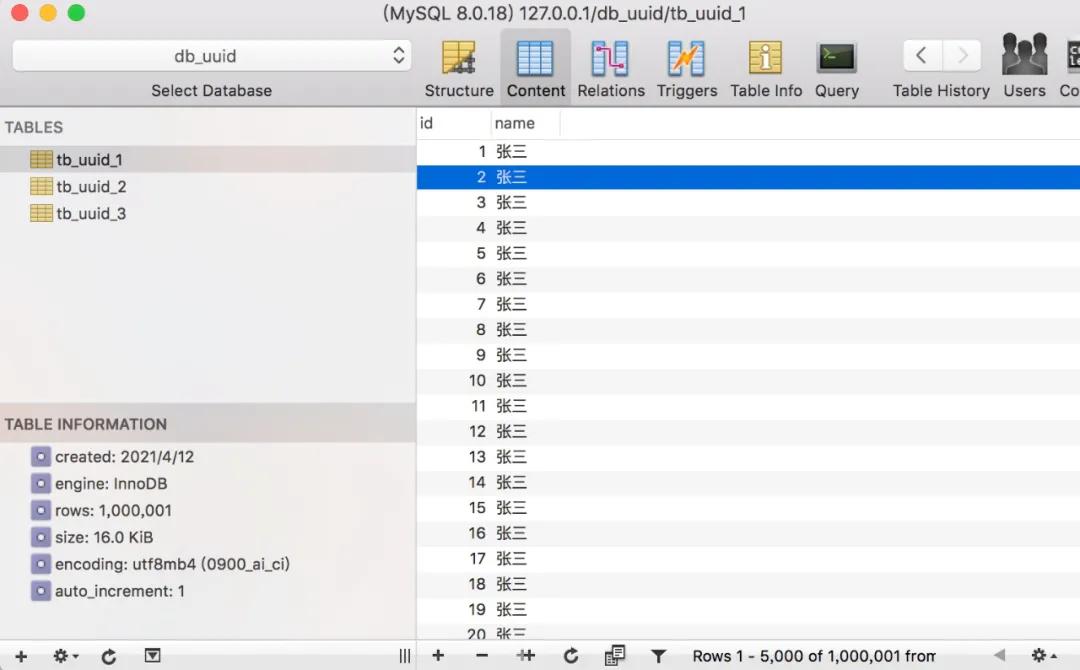
首先,我們在本地數據庫中創建三張單表tb_uuid_1、tb_uuid_2、tb_uuid_3,同時設置tb_uuid_1表的主鍵為自增長模式,腳本如下:
- CREATE TABLE `tb_uuid_1` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
- `name` varchar(20) DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='主鍵ID自增長';
- CREATE TABLE `tb_uuid_2` (
- `id` bigint(20) unsigned NOT NULL,
- `name` varchar(20) DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='主鍵ID隨機數生成';
- CREATE TABLE `tb_uuid_3` (
- `id` varchar(50) NOT NULL,
- `name` varchar(20) DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='主鍵采用uuid生成';
下面,我們采用Springboot + mybatis來實現插入測試。
2.1、數據庫自增
以數據庫自增為例,首先編寫好各種實體、數據持久層操作,方便后續進行測試
- /**
- * 表實體
- */
- public class UUID1 implements Serializable {
- private Long id;
- private String name;
- //省略set、get
- }
- /**
- * 數據持久層操作
- */
- public interface UUID1Mapper {
- /**
- * 自增長插入
- * @param uuid1
- */
- @Insert("INSERT INTO tb_uuid_1(name) VALUES(#{name})")
- void insert(UUID1 uuid1);
- }
- /**
- * 自增ID,單元測試
- */
- @Test
- public void testInsert1(){
- long start = System.currentTimeMillis();
- for (int i = 0; i < 1000000; i++) {
- uuid1Mapper.insert(new UUID1().setName("張三"));
- }
- long end = System.currentTimeMillis();
- System.out.println("花費時間:" + (end - start));
- }
2.2、采用隨機數生成ID
這里,我們采用twitter的雪花算法來實現隨機數ID的生成,工具類如下:
- public class SnowflakeIdWorker {
- private static SnowflakeIdWorker instance = new SnowflakeIdWorker(0,0);
- /**
- * 開始時間截 (2015-01-01)
- */
- private final long twepoch = 1420041600000L;
- /**
- * 機器id所占的位數
- */
- private final long workerIdBits = 5L;
- /**
- * 數據標識id所占的位數
- */
- private final long datacenterIdBits = 5L;
- /**
- * 支持的最大機器id,結果是31 (這個移位算法可以很快的計算出幾位二進制數所能表示的最大十進制數)
- */
- private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
- /**
- * 支持的最大數據標識id,結果是31
- */
- private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
- /**
- * 序列在id中占的位數
- */
- private final long sequenceBits = 12L;
- /**
- * 機器ID向左移12位
- */
- private final long workerIdShift = sequenceBits;
- /**
- * 數據標識id向左移17位(12+5)
- */
- private final long datacenterIdShift = sequenceBits + workerIdBits;
- /**
- * 時間截向左移22位(5+5+12)
- */
- private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
- /**
- * 生成序列的掩碼,這里為4095 (0b111111111111=0xfff=4095)
- */
- private final long sequenceMask = -1L ^ (-1L << sequenceBits);
- /**
- * 工作機器ID(0~31)
- */
- private long workerId;
- /**
- * 數據中心ID(0~31)
- */
- private long datacenterId;
- /**
- * 毫秒內序列(0~4095)
- */
- private long sequence = 0L;
- /**
- * 上次生成ID的時間截
- */
- private long lastTimestamp = -1L;
- /**
- * 構造函數
- * @param workerId 工作ID (0~31)
- * @param datacenterId 數據中心ID (0~31)
- */
- public SnowflakeIdWorker(long workerId, long datacenterId) {
- if (workerId > maxWorkerId || workerId < 0) {
- throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
- }
- if (datacenterId > maxDatacenterId || datacenterId < 0) {
- throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
- }
- this.workerId = workerId;
- this.datacenterId = datacenterId;
- }
- /**
- * 獲得下一個ID (該方法是線程安全的)
- * @return SnowflakeId
- */
- public synchronized long nextId() {
- long timestamp = timeGen();
- // 如果當前時間小于上一次ID生成的時間戳,說明系統時鐘回退過這個時候應當拋出異常
- if (timestamp < lastTimestamp) {
- throw new RuntimeException(
- String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
- }
- // 如果是同一時間生成的,則進行毫秒內序列
- if (lastTimestamp == timestamp) {
- sequence = (sequence + 1) & sequenceMask;
- // 毫秒內序列溢出
- if (sequence == 0) {
- //阻塞到下一個毫秒,獲得新的時間戳
- timestamp = tilNextMillis(lastTimestamp);
- }
- }
- // 時間戳改變,毫秒內序列重置
- else {
- sequence = 0L;
- }
- // 上次生成ID的時間截
- lastTimestamp = timestamp;
- // 移位并通過或運算拼到一起組成64位的ID
- return ((timestamp - twepoch) << timestampLeftShift) //
- | (datacenterId << datacenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence;
- }
- /**
- * 阻塞到下一個毫秒,直到獲得新的時間戳
- * @param lastTimestamp 上次生成ID的時間截
- * @return 當前時間戳
- */
- protected long tilNextMillis(long lastTimestamp) {
- long timestamp = timeGen();
- while (timestamp <= lastTimestamp) {
- timestamp = timeGen();
- }
- return timestamp;
- }
- /**
- * 返回以毫秒為單位的當前時間
- * @return 當前時間(毫秒)
- */
- protected long timeGen() {
- return System.currentTimeMillis();
- }
- public static SnowflakeIdWorker getInstance(){
- return instance;
- }
- public static void main(String[] args) throws InterruptedException {
- SnowflakeIdWorker idWorker = SnowflakeIdWorker.getInstance();
- for (int i = 0; i < 10; i++) {
- long id = idWorker.nextId();
- Thread.sleep(1);
- System.out.println(id);
- }
- }
- }
其他的操作,與上面類似。
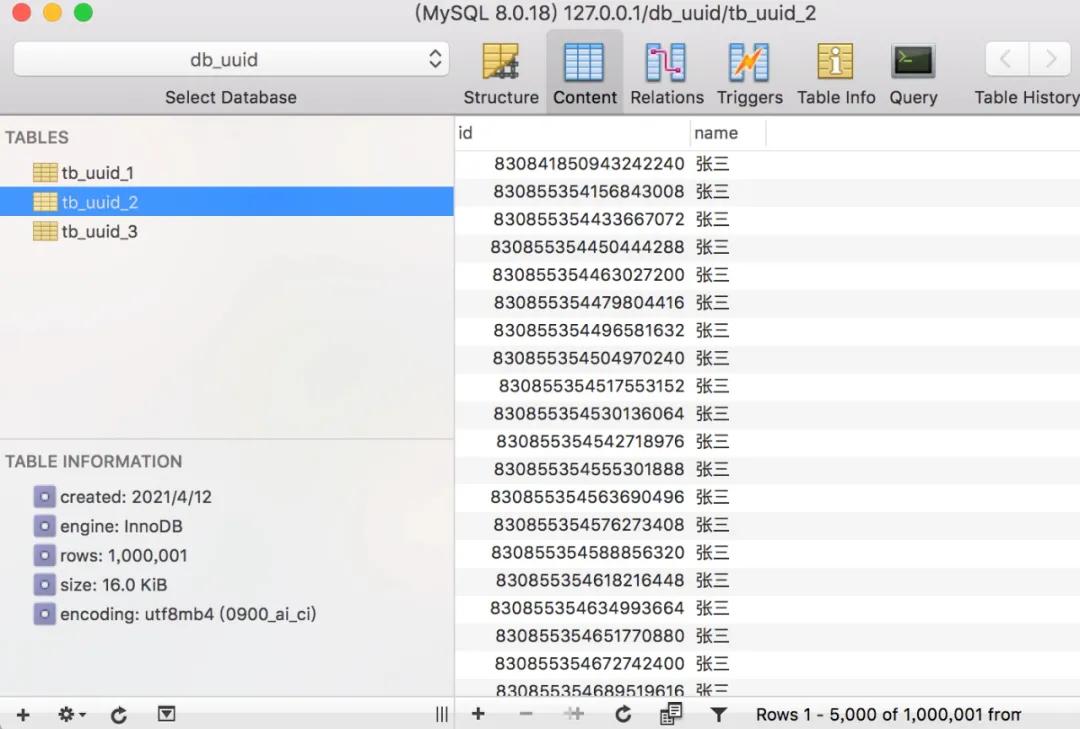
2.3、uuid
同樣的,uuid的生成,我們事先也可以將工具類編寫好:
- public class UUIDGenerator {
- /**
- * 獲取uuid
- * @return
- */
- public static String getUUID(){
- return UUID.randomUUID().toString();
- }
- }
最后的單元測試,代碼如下:
- @RunWith(SpringRunner.class)
- @SpringBootTest()
- public class UUID1Test {
- private static final Integer MAX_COUNT = 1000000;
- @Autowired
- private UUID1Mapper uuid1Mapper;
- @Autowired
- private UUID2Mapper uuid2Mapper;
- @Autowired
- private UUID3Mapper uuid3Mapper;
- /**
- * 測試自增ID耗時
- */
- @Test
- public void testInsert1(){
- long start = System.currentTimeMillis();
- for (int i = 0; i < MAX_COUNT; i++) {
- uuid1Mapper.insert(new UUID1().setName("張三"));
- }
- long end = System.currentTimeMillis();
- System.out.println("自增ID,花費時間:" + (end - start));
- }
- /**
- * 測試采用雪花算法生產的隨機數ID耗時
- */
- @Test
- public void testInsert2(){
- long start = System.currentTimeMillis();
- for (int i = 0; i < MAX_COUNT; i++) {
- long id = SnowflakeIdWorker.getInstance().nextId();
- uuid2Mapper.insert(new UUID2().setId(id).setName("張三"));
- }
- long end = System.currentTimeMillis();
- System.out.println("花費時間:" + (end - start));
- }
- /**
- * 測試采用UUID生成的ID耗時
- */
- @Test
- public void testInsert3(){
- long start = System.currentTimeMillis();
- for (int i = 0; i < MAX_COUNT; i++) {
- String id = UUIDGenerator.getUUID();
- uuid3Mapper.insert(new UUID3().setId(id).setName("張三"));
- }
- long end = System.currentTimeMillis();
- System.out.println("花費時間:" + (end - start));
- }
- }
三、性能測試
程序環境搭建完成之后,啥也不說了,直接擼起袖子,將單元測試跑起來!
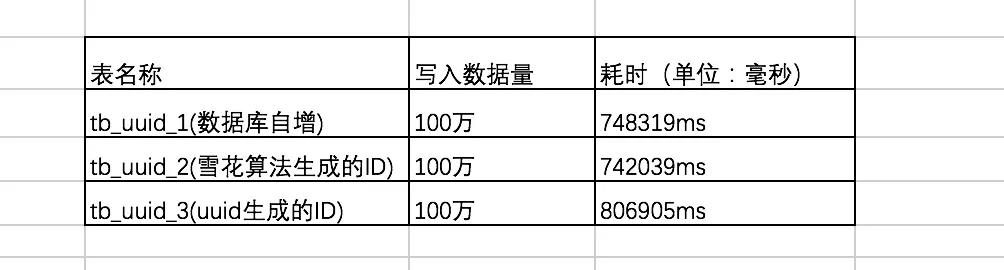
首先測試一下,插入100萬數據的情況下,三者直接的耗時結果如下:
在原有的數據量上,我們繼續插入30萬條數據,三者耗時結果如下:
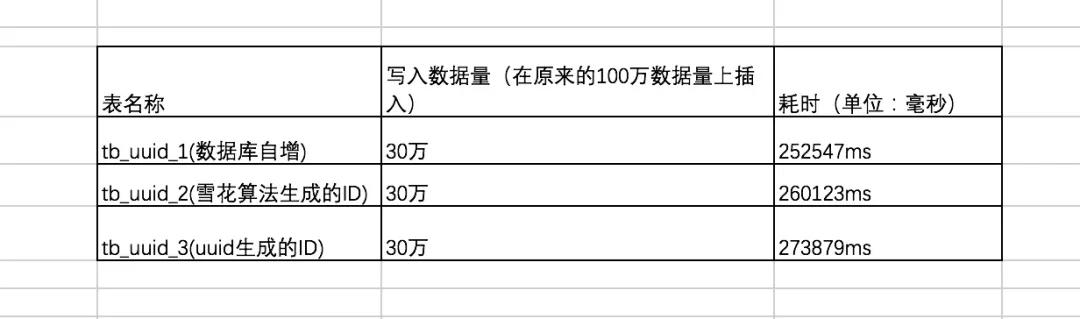
可以看出在數據量 100W 左右的時候,uuid的插入效率墊底,隨著插入的數據量增長,uuid 生成的ID插入呈直線下降!
時間占用量總體效率排名為:自增ID > 雪花算法生成的ID >> uuid生成的ID。
在數據量較大的情況下,為什么uuid生成的ID遠不如自增ID呢?
關于這點,我們可以從 mysql 主鍵存儲的內部結構來進行分析。
3.1、自增ID內部結構
自增的主鍵的值是順序的,所以 Innodb 把每一條記錄都存儲在一條記錄的后面。
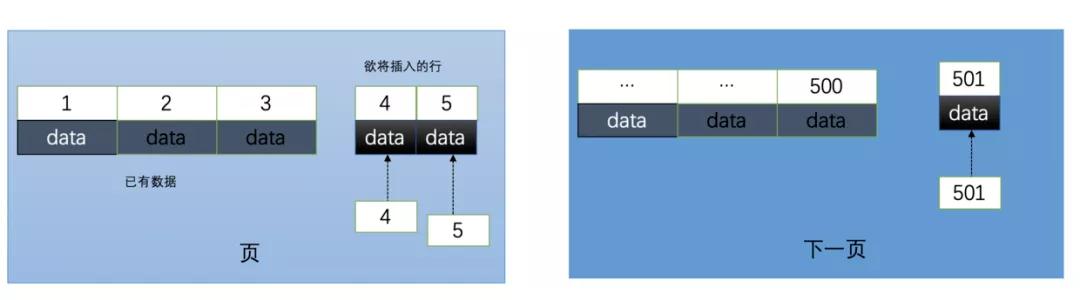
當達到頁面的最大填充因子時候(innodb默認的最大填充因子是頁大小的15/16,會留出1/16的空間留作以后的修改),會進行如下操作:
- 下一條記錄就會寫入新的頁中,一旦數據按照這種順序的方式加載,主鍵頁就會近乎于順序的記錄填滿,提升了頁面的最大填充率,不會有頁的浪費
- 新插入的行一定會在原有的最大數據行下一行,mysql定位和尋址很快,不會為計算新行的位置而做出額外的消耗
3.2、使用uuid的索引內部結構
uuid相對順序的自增id來說是毫無規律可言的,新行的值不一定要比之前的主鍵的值要大,所以innodb無法做到總是把新行插入到索引的最后,而是需要為新行尋找新的合適的位置從而來分配新的空間。
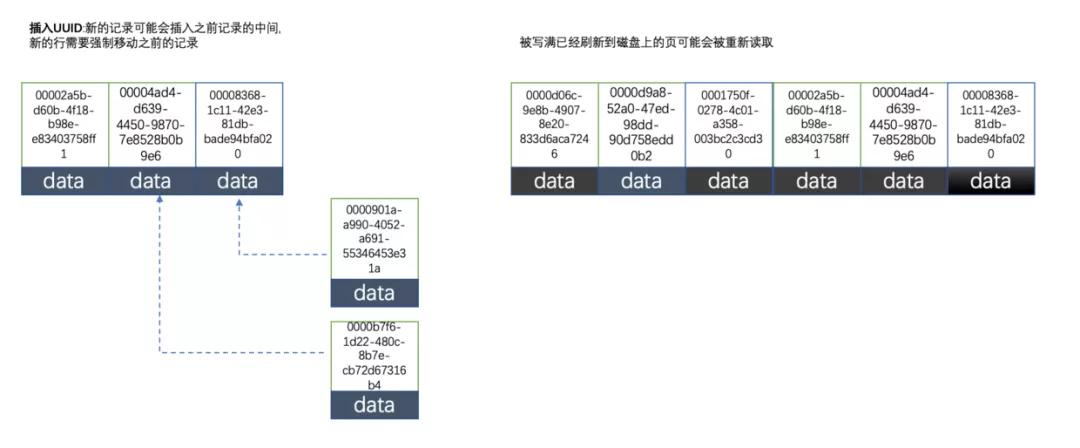
這個過程需要做很多額外的操作,數據的毫無順序會導致數據分布散亂,將會導致以下的問題:
- 寫入的目標頁很可能已經刷新到磁盤上并且從緩存上移除,或者還沒有被加載到緩存中,innodb在插入之前不得不先找到并從磁盤讀取目標頁到內存中,這將導致大量的隨機IO
- 因為寫入是亂序的,innodb不得不頻繁的做頁分裂操作,以便為新的行分配空間,頁分裂導致移動大量的數據,一次插入最少需要修改三個頁以上
- 由于頻繁的頁分裂,頁會變得稀疏并被不規則的填充,最終會導致數據會有碎片
在把值載入到聚簇索引(innodb默認的索引類型)以后,有時候會需要做一次OPTIMEIZE TABLE來重建表并優化頁的填充,這將又需要一定的時間消耗。
因此,在選擇主鍵ID生成方案的時候,盡可能別采用uuid的方式來生成主鍵ID,隨著數據量越大,插入性能會越低!
四、總結
在實際使用過程中,推薦使用主鍵自增ID和雪花算法生成的隨機ID。
但是使用自增ID也有缺點:
1、別人一旦爬取你的數據庫,就可以根據數據庫的自增id獲取到你的業務增長信息,很容易進行數據竊取。2、其次,對于高并發的負載,innodb在按主鍵進行插入的時候會造成明顯的鎖爭用,主鍵的上界會成為爭搶的熱點,因為所有的插入都發生在這里,并發插入會導致間隙鎖競爭。
總結起來,如果業務量小,推薦采用自增ID,如果業務量大,推薦采用雪花算法生成的隨機ID。
本篇文章主要從實際程序實例出發,討論了三種主鍵ID生成方案的性能差異, 鑒于筆者才疏學淺,可能也有理解不到位的地方,歡迎網友們批評指出!