讓我一起淺析Nginx 架構
1.Nginx 基礎架構
nginx 啟動后以 daemon 形式在后臺運行,后臺進程包含一個 master 進程和多個 worker 進程。如下圖所示:
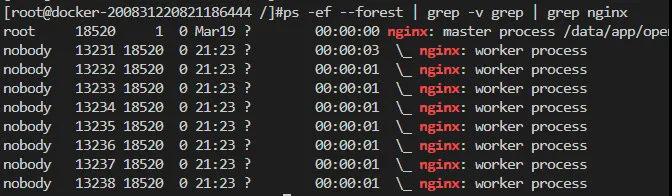
master與worker
nginx 是由一個 master 管理進程,多個 worker 進程處理工作的多進程模型。基礎架構設計,如下圖所示:
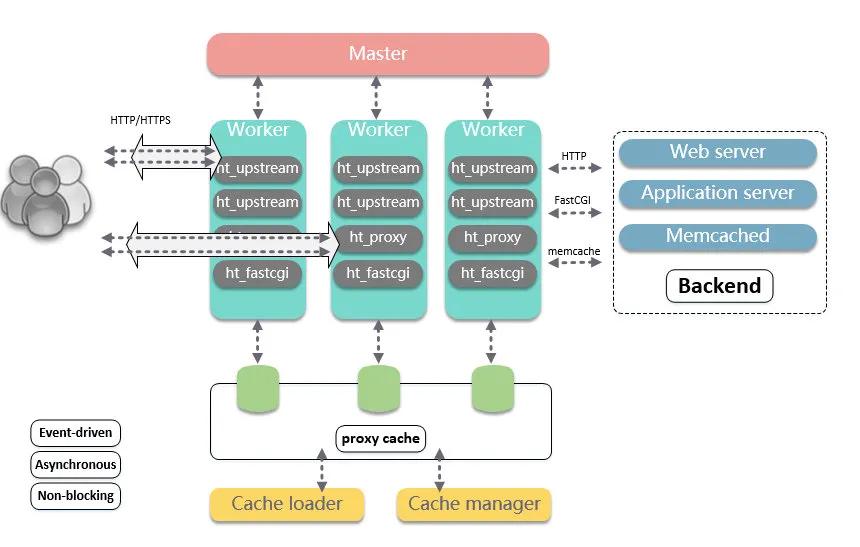
基礎架構設計
master 負責管理 worker 進程,worker 進程負責處理網絡事件。整個框架被設計為一種依賴事件驅動、異步、非阻塞的模式。
如此設計的優點:
- 1.可以充分利用多核機器,增強并發處理能力。
- 2.多 worker 間可以實現負載均衡。
- 3.Master 監控并統一管理 worker 行為。在 worker 異常后,可以主動拉起 worker 進程,從而提升了系統的可靠性。并且由 Master 進程控制服務運行中的程序升級、配置項修改等操作,從而增強了整體的動態可擴展與熱更的能力。
2.Master 進程
2.1 核心邏輯
master 進程的主邏輯在ngx_master_process_cycle,核心關注源碼:
- ngx_master_process_cycle(ngx_cycle_t *cycle)
- {
- ...
- ngx_start_worker_processes(cycle, ccf->worker_processes,
- NGX_PROCESS_RESPAWN);
- ...
- for ( ;; ) {
- if (delay) {...}
- ngx_log_debug0(NGX_LOG_DEBUG_EVENT, cycle->log, 0, "sigsuspend");
- sigsuspend(&set);
- ngx_time_update();
- ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,
- "wake up, sigio %i", sigio);
- if (ngx_reap) {
- ngx_reap = 0;
- ngx_log_debug0(NGX_LOG_DEBUG_EVENT, cycle->log, 0, "reap children");
- live = ngx_reap_children(cycle);
- }
- if (!live && (ngx_terminate || ngx_quit)) {...}
- if (ngx_terminate) {...}
- if (ngx_quit) {...}
- if (ngx_reconfigure) {...}
- if (ngx_restart) {...}
- if (ngx_reopen) {...}
- if (ngx_change_binary) {...}
- if (ngx_noaccept) {
- ngx_noaccept = 0;
- ngx_noaccepting = 1;
- ngx_signal_worker_processes(cycle,
- ngx_signal_value(NGX_SHUTDOWN_SIGNAL));
- }
- }
- }
由上述代碼,可以理解,master 進程主要用來管理 worker 進程,具體包括如下 4 個主要功能:
1.接受來自外界的信號。其中 master 循環中的各項標志位就對應著各種信號,如:ngx_quit代表QUIT信號,表示優雅的關閉整個服務。
2.向各個 worker 進程發送信。比如ngx_noaccept代表WINCH信號,表示所有子進程不再接受處理新的連接,由 master 向所有的子進程發送 QUIT 信號量。
3.監控 worker 進程的運行狀態。比如ngx_reap代表CHILD信號,表示有子進程意外結束,這時需要監控所有子進程的運行狀態,主要由ngx_reap_children完成。
4.當 woker 進程退出后(異常情況下),會自動重新啟動新的 woker 進程。主要也是在ngx_reap_children
2.2 熱更
2.2.1 熱重載-配置熱更
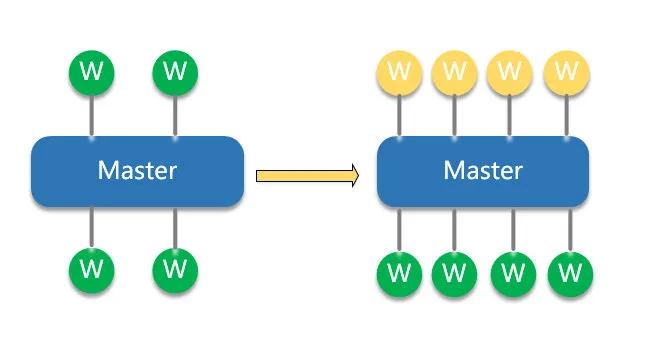
熱重載
nginx 熱更配置時,可以保持運行中平滑更新配置,具體流程如下:
- 1.更新 nginx.conf 配置文件,向 master 發送 SIGHUP 信號或執行 nginx -s reload
- 2.master 進程使用新配置,啟動新的 worker 進程
- 3.使用舊配置的 worker 進程,不再接受新的連接請求,并在完成已存在的連接后退出
2.2.2 熱升級-程序熱更
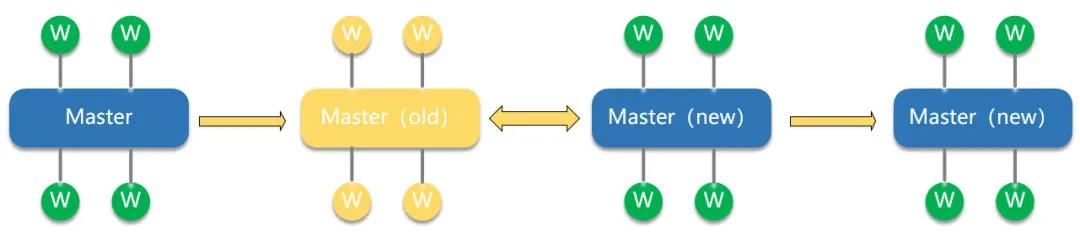
熱升級
nginx 熱升級過程如下:
1.將舊 Nginx 文件換成新 Nginx 文件(注意備份)
2.向 master 進程發送 USR2 信號(平滑升級到新版本的 Nginx 程序)
3.master 進程修改 pid 文件號,加后綴.oldbin
4.master 進程用新 Nginx 文件啟動新 master 進程,此時新老 master/worker 同時存在。
5.向老 master 發送 WINCH 信號,關閉舊 worker 進程,觀察新 worker 進程工作情況。若升級成功,則向老 master 進程發送 QUIT 信號,關閉老 master 進程;若升級失敗,則需要回滾,向老 master 發送 HUP 信號(重讀配置文件),向新 master 發送 QUIT 信號,關閉新 master 及 worker。
3.Worker 進程
3.1 核心邏輯
worker 進程的主邏輯在ngx_worker_process_cycle,核心關注源碼:
- ngx_worker_process_cycle(ngx_cycle_t *cycle, void *data)
- {
- ngx_int_t worker = (intptr_t) data;
- ngx_process = NGX_PROCESS_WORKER;
- ngx_worker = worker;
- ngx_worker_process_init(cycle, worker);
- ngx_setproctitle("worker process");
- for ( ;; ) {
- if (ngx_exiting) {...}
- ngx_log_debug0(NGX_LOG_DEBUG_EVENT, cycle->log, 0, "worker cycle");
- ngx_process_events_and_timers(cycle);
- if (ngx_terminate) {...}
- if (ngx_quit) {...}
- if (ngx_reopen) {...}
- }
- }
由上述代碼,可以理解,worker 進程主要在處理網絡事件,通過ngx_process_events_and_timers方法實現,其中事件主要包括:網絡事件、定時器事件。
3.2 事件驅動-epoll
worker 進程在處理網絡事件時,依靠 epoll 模型,來管理并發連接,實現了事件驅動、異步、非阻塞等特性。如下圖所示:
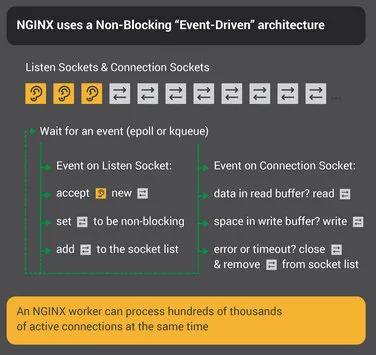
infographic-Inside-NGINX_nonblocking
通常海量并發連接過程中,每一時刻(相對較短的一段時間),往往只需要處理一小部分有事件的連接即活躍連接。基于以上現象,epoll 通過將連接管理與活躍連接管理進行分離,實現了高效、穩定的網絡 IO 處理能力。
網絡模型對比
其中,epoll 利用紅黑樹高效的增刪查效率來管理連接,利用一個雙向鏈表來維護活躍連接。
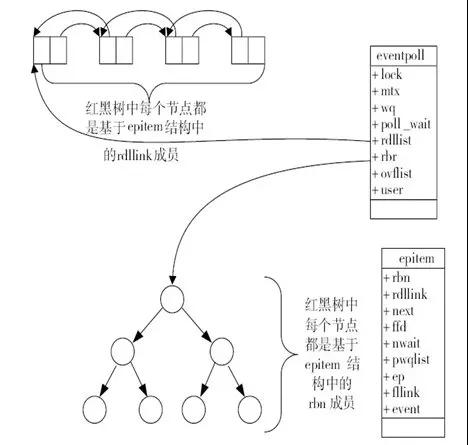
epoll數據結構
3.3 驚群
由于 worker 都是由 master 進程 fork 產生,所以 worker 都會監聽相同端口。這樣多個子進程在 accept 建立連接時會發生爭搶,帶來著名的“驚群”問題。worker 核心處理邏輯ngx_process_events_and_timers核心代碼如下:
- void ngx_process_events_and_timers(ngx_cycle_t *cycle){
- //這里面會對監聽socket處理
- ...
- if (ngx_accept_disabled > 0) {
- ngx_accept_disabled--;
- } else {
- //獲得鎖則加入wait集合,
- if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
- return;
- }
- ...
- //設置網絡讀寫事件延遲處理標志,即在釋放鎖后處理
- if (ngx_accept_mutex_held) {
- flags |= NGX_POST_EVENTS;
- }
- }
- ...
- //這里面epollwait等待網絡事件
- //網絡連接事件,放入ngx_posted_accept_events隊列
- //網絡讀寫事件,放入ngx_posted_events隊列
- (void) ngx_process_events(cycle, timer, flags);
- ...
- //先處理網絡連接事件,只有獲取到鎖,這里才會有連接事件
- ngx_event_process_posted(cycle, &ngx_posted_accept_events);
- //釋放鎖,讓其他進程也能夠拿到
- if (ngx_accept_mutex_held) {
- ngx_shmtx_unlock(&ngx_accept_mutex);
- }
- //處理網絡讀寫事件
- ngx_event_process_posted(cycle, &ngx_posted_events);
- }
由上述代碼可知,Nginx 解決驚群的方法:
1.將連接事件與讀寫事件進行分離。連接事件存放為ngx_posted_accept_events,讀寫事件存放為ngx_posted_events。
2.設置ngx_accept_mutex鎖,只有獲得鎖的進程,才可以處理連接事件。
3.4 負載均衡
worker 間的負載關鍵在于各自接入了多少連接,其中接入連接搶鎖的前置條件是ngx_accept_disabled > 0,所以ngx_accept_disabled就是負載均衡機制實現的關鍵閾值。
- ngx_int_t ngx_accept_disabled;
- ngx_accept_disabled = ngx_cycle->connection_n / 8 - ngx_cycle->free_connection_n;
因此,在 nginx 啟動時,ngx_accept_disabled的值就是一個負數,其值為連接總數的 7/8。當該進程的連接數達到總連接數的 7/8 時,該進程就不會再處理新的連接了,同時每次調用'ngx_process_events_and_timers'時,將ngx_accept_disabled減 1,直到其值低于閾值時,才試圖重新處理新的連接。因此,nginx 各 worker 子進程間的負載均衡僅在某個 worker 進程處理的連接數達到它最大處理總數的 7/8 時才會觸發,其負載均衡并不是在任意條件都滿足。如下圖所示:
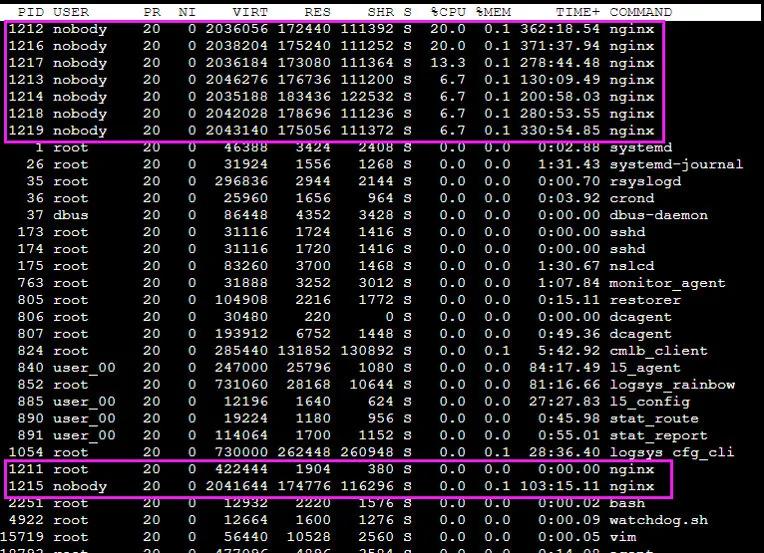
實際工作情況
其中'pid'為 1211 的進程為 master 進程,其余為 worker 進程
4.思考
4.1 為什么不采用多線程模型管理連接?
1.無狀態服務,無需共享進程內存
2.采用獨立的進程,可以讓互相之間不會影響。一個進程異常崩潰,其他進程的服務不會中斷,提升了架構的可靠性。
3.進程之間不共享資源,不需要加鎖,所以省掉了鎖帶來的開銷。
4.2 為什么不采用多線程處理邏輯業務?
1.進程數已經等于核心數,再新建線程處理任務,只會搶占現有進程,增加切換代價。
2.作為接入層,基本上都是數據轉發業務,網絡 IO 任務的等待耗時部分,已經被處理為非阻塞/全異步/事件驅動模式,在沒有更多 CPU 的情況下,再利用多線程處理,意義不大。并且如果進程中有阻塞的處理邏輯,應該由各個業務進行解決,比如 openResty 中利用了 Lua 協程,對阻塞業務進行了優化。