95%PyTorch庫都會中招的bug!特斯拉AI總監都沒能幸免
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
到底是怎樣的一個bug,能讓95%的Pytorch庫中招,就連特斯拉AI總監深受困擾?
還別說,這個bug雖小,但有夠“狡猾”的。
這就是最近Reddit上熱議的一個話題,是一位網友在使用再平常不過的Pytorch+Numpy組合時發現。
最主要的是,在代碼能夠跑通的情況下,它甚至還會影響模型的準確率!

除此之外,網友熱議的另外一個點,竟然是:
而是它到底算不算一個bug?
這究竟是怎么一回事?
事情的起因是一位網友發現,在PyTorch中用NumPy來生成隨機數時,受到數據預處理的限制,會多進程并行加載數據,但最后每個進程返回的隨機數卻是相同的。
他還舉出例子證實了自己的說法。
如下是一個示例數據集,它會返回三個元素的隨機向量。這里采用的批量大小分別為2,工作進程為4個。

然后神奇的事情發生了:每個進程返回的隨機數都是一樣的。

這個結果會著實讓人有點一頭霧水,就好像數學應用題求小明走一段路程需要花費多少時間,而你卻算出來了負數。
發現了問題后,這位網友還在GitHub上下載了超過10萬個PyTorch庫,用同樣的方法產生隨機數。
結果更加令人震驚:居然有超過95%的庫都受到這個問題的困擾!
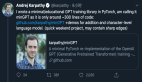
這其中不乏PyTorch的官方教程和OpenAI的代碼,連特斯拉AI總監Karpathy也承認自己“被坑過”!
但有一說一,這個bug想要解決也不難:只需要在每個epoch都重新設置seed,或者用python內置的隨機數生成器就可以避免這個問題。
到底是不是bug?
如果這個問題已經可以解決,為什么還會引起如此大的討論呢?
因為網友們的重點已經上升到了“哲學”層面:
這到底是不是一個bug?
在Reddit上有人認為:這不是一個bug。
雖然這個問題非常常見,但它并不算是一個bug,而是一個在調試時不可以忽略的點。

就是這個觀點,激起了千層浪花,許多人都認為他忽略了問題的關鍵所在。
這不是產生偽隨機數的問題,也不是numpy的問題,問題的核心是在于PyTorch中的DataLoader的實現

對于包含隨機轉換的數據加載pipeline,這意味著每個worker都將選擇“相同”的轉換。
而現在NN中的許多數據加載pipeline,都使用某種類型的隨機轉換來進行數據增強,所以不重新初始化可能是一個預設。
另一位網友也表示這個bug其實是在預設程序下運行才出現的,應該向更多用戶指出來。
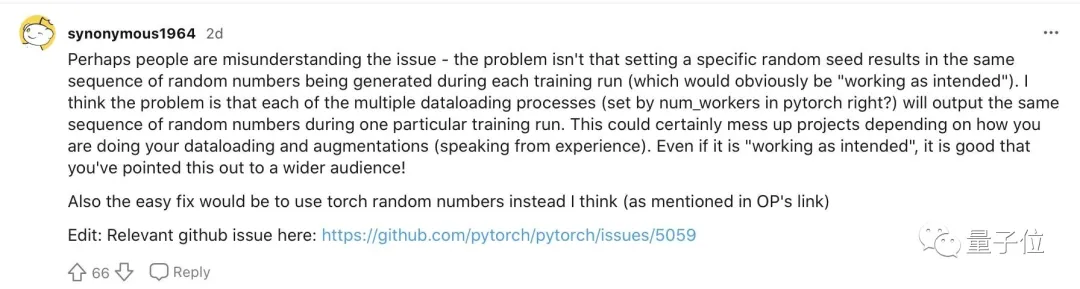
并且95%以上的Pytorch庫受此困擾,也絕不是危言聳聽。
有人就分享出了自己此前的慘痛經歷:
我認識到這一點是之前跑了許多進程來創建數據集時,然而發現其中一半的數據是重復的,之后花了很長的時間才發現哪里出了問題。

也有用戶補充說,如果 95% 以上的用戶使用時出現錯誤,那么代碼就是錯的。

順便一提,這提供了Karpathy定律的另一個例子:即使你搞砸了一些非常基本代碼,“neural nets want to work”。
你有踩過PyTorch的坑嗎?
如上的bug并不是偶然,隨著用PyTorch的人越來越多,被發現的bug也就越來越多,某乎上還有PyTorch的坑之總結,被瀏覽量高達49w。

其中從向量、函數到model.train(),無論是真bug還是自己出了bug,大家的血淚史還真的是各有千秋。
所以,關于PyTorch你可以分享的經驗血淚史嗎?