













聊聊Hive數據類型和簡單使用
作者:小sen
可以將本地文件導入到HIve中,我們先把文件上傳到HDFS,然后使用HDFS將數據導入到Hive中。

Hive使用的語句是Hql,和sql百分之九十都是相近的,因此,只要對SQL比較熟悉的,Hql基本不用怎么學。
基本數據類型
「基本數據類型」
- tinyint/smallint/int/bigint: 整數類型
- float/double: 浮點數類型
- boolean:布爾類型
- string:字符串類型
「復雜數據類型」
- Array:數組類型,由一系列相同數據類型的元素組成
- Map:集合類型,包含key->value鍵值對,可以通過key來訪問元素
- Struct:結構類型,可以包含不同數據類型的元。這些元素可以通過"點語法"的方式來得到所需要的元素
「時間類型」
- Date:從Hive0.12.0開始支持
- Timestamp:從Hive0.8.0開始支持
常用DDL操作
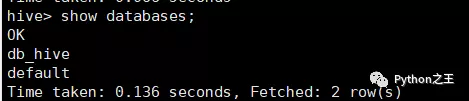
查看數據列表
- show databases;
使用數據庫
- USE database_name;
新建數據庫
語法:
- CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name --DATABASE|SCHEMA 是等價的
- [COMMENT database_comment] --數據庫注釋
- [LOCATION hdfs_path] --存儲在 HDFS 上的位置
- [WITH DBPROPERTIES (property_name=property_value, ...)]; --指定額外屬性
示例:
- CREATE DATABASE IF NOT EXISTS hive_test
- COMMENT 'hive database for test'
- WITH DBPROPERTIES ('create'='heibaiying');
創建一個數據庫,數據庫在HDFS 上的默認存儲路徑是/user/hive/warehouse/\*.db。
創建一個數據庫,可以指定數據庫在 HDFS 上存放的位置
- hive > CREATE DATABASE hive_test location '/db_hive.db';
查看數據庫信息
語法:
- DESC DATABASE [EXTENDED] db_name; --EXTENDED 表示是否顯示額外屬性
示例:
- DESC DATABASE EXTENDED hive_test;
刪除數據庫
語法:
- DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
默認行為是 RESTRICT,如果數據庫中存在表則刪除失敗。要想刪除庫及其中的表,可以使用 CASCADE 級聯刪除。
示例:
- DROP DATABASE IF EXISTS hive_test CASCADE;
案例實操
本地文件導入Hive
- [hadoop@node02 ~]$ vim student.txt
- student.id student.name
- 1 Runsen
- 2 Zhangsan
- 3 Lisi
- hive> CREATE DATABASE db_hive;
- hive> use db_hive;
- hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
- hive> load data local inpath 'student.txt' into table student;
- hive> select * from student;
- OK
- student.id student.name
- 1 Runsen
- 2 Zhangsan
- 3 Lisi
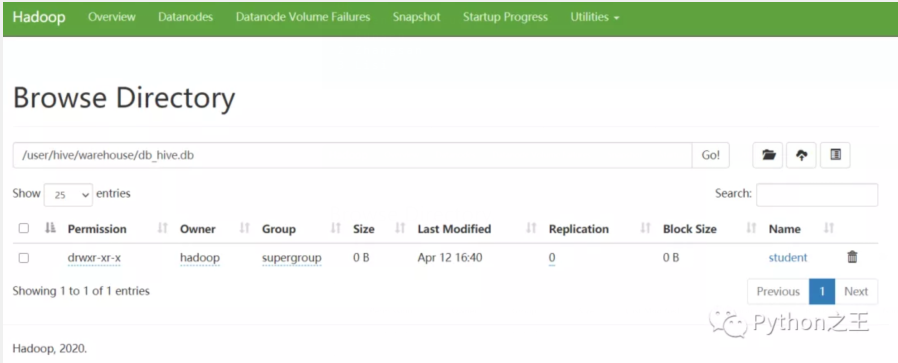
除了可以將本地文件導入到HIve中,我們先把文件上傳到HDFS,然后使用HDFS將數據導入到Hive中。
責任編輯:姜華
來源:
Python之王


















