













SQL、Pandas和Spark:這個庫,實現了三大數據分析工具的大一統

01 pyspark簡介及環境搭建
pyspark是python中的一個第三方庫,相當于Apache Spark組件的python化版本(Spark當前支持Java Scala Python和R 4種編程語言接口),需要依賴py4j庫(即python for java的縮略詞),而恰恰是這個庫實現了將python和java的互聯,所以pyspark庫雖然體積很大,大約226M,但實際上絕大部分都是spark中的原生jar包,占據了217M,體積占比高達96%。
由于Spark是基于Scala語言實現的大數據組件,而Scala語言又是運行在JVM虛擬機上的,所以Spark自然依賴JDK,截止目前為止JDK8依然可用,而且幾乎是安裝各大數據組件時的首選。所以搭建pyspark環境首先需要安裝JDK8,而后這里介紹兩種方式搭建pyspark運行環境:
1)pip install pyspark+任意pythonIDE
pyspark作為python的一個第三方庫,自然可以通過pip包管理工具進行安裝,所以僅需執行如下命令即可完成自動安裝:
- pip install pyspark
為了保證更快的下載速度,可以更改pip源為國內鏡像,具體設置方式可參考歷史文章:是時候總結一波Python環境搭建問題了
2)Spark官網下載指定tar包解壓
與其他大數據組件不同,Spark實際上提供了windows系統下良好的兼容運行環境,而且方式也非常簡單。訪問spark官網,選擇目標版本(當前最新版本是spark3.1.1版本),點擊鏈接即可跳轉到下載頁面,不出意外的話會自動推薦國內鏡像下載地址,所以下載速度是很有保證的。
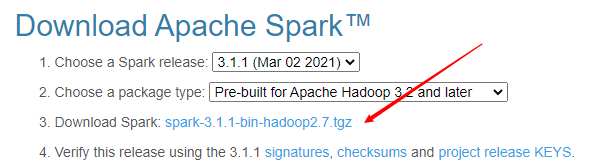
下載完畢后即得到了一個tgz格式的文件,移動至適當目錄直接解壓即可,而后進入bin目錄,選擇打開pyspark.cmd,即會自動創建一個pyspark的shell運行環境,整個過程非常簡單,無需任何設置。
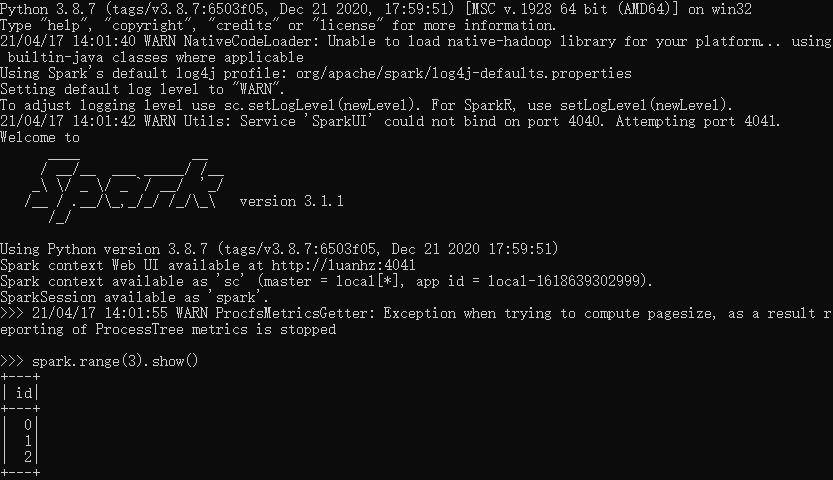
進入pyspark環境,已創建好sc和spark兩個入口變量
兩種pyspark環境搭建方式對比:
- 運行環境不同:pip源安裝相當于擴展了python運行庫,所以可在任何pythonIDE中引入和使用,更為靈活方便;而spark tar包解壓本質上相當于是安裝了一個windows系統下的軟件,只能通過執行該“軟件”的方式進入
- 提供功能不同:pip源安裝方式僅限于在python語言下使用,只要可以import pyspark即可;而spark tar包解壓,則不僅提供了pyspark入口,其實還提供了spark-shell(scala版本)sparkR等多種cmd執行環境;
- 使用方式不同:pip源安裝需要在使用時import相應包,并手動創建sc和spark入口變量;而spark tar包解壓進入shell時,會提供已創建好的sc和spark入口變量,更為方便。
總體來看,兩種方式各有利弊,如果是進行正式的開發和數據處理流程,個人傾向于選擇進入第一種pyspark環境;而對于簡單的功能測試,則會優先使用pyspark.cmd環境。
02 三大數據分析工具靈活切換
在日常工作中,我們常常會使用多種工具來實現不同的數據分析需求,比如個人用的最多的還是SQL、Pandas和Spark3大工具,無非就是喜歡SQL的語法簡潔易用、Pandas的API豐富多樣以及Spark的分布式大數據處理能力,但同時不幸的是這幾個工具也都有各自的弱點,比如SQL僅能用于處理一些簡單的需求,復雜的邏輯實現不太可能;Pandas只能單機運行、大數據處理乏力;Spark接口又相對比較有限,且有些算子寫法會比較復雜。
懶惰是人類進步的階梯,這個道理在數據處理工具的選擇上也有所體現。
希望能在多種工具間靈活切換、自由組合選用,自然是最樸(偷)素(懶)的想法,所幸pyspark剛好能夠滿足這一需求!以SQL中的數據表、pandas中的DataFrame和spark中的DataFrame三種數據結構為對象,依賴如下幾個接口可實現數據在3種工具間的任意切換:
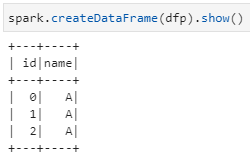
- spark.createDataFrame() # 實現從pd.DataFrame -> spark.DataFrame
- df.toPandas() # 實現從spark.DataFrame -> pd.DataFrame
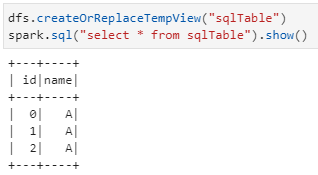
- df.createOrReplaceTempView() # 實現從spark.DataFrame注冊為一個臨時SQL表
- spark.sql() # 實現從注冊臨時表查詢得到spark.DataFrame
當然,pandas自然也可以通過pd.read_sql和df.to_sql實現pandas與數據庫表的序列化與反序列化,但這里主要是指在內存中的數據結構的任意切換。
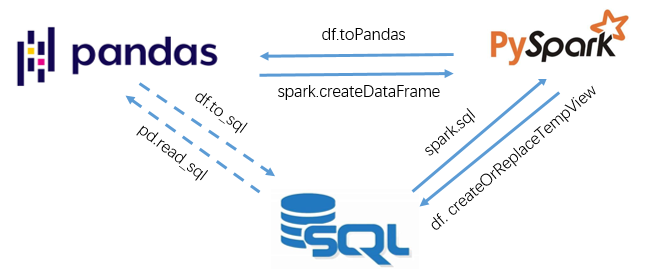
舉個小例子:
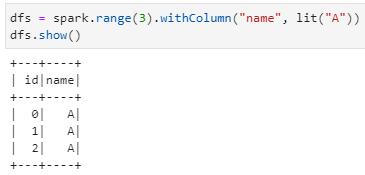
1)spark創建一個DataFrame
2)spark.DataFrame轉換為pd.DataFrame
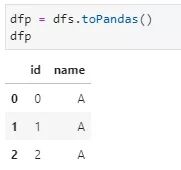
3)pd.DataFrame轉換為spark.DataFrame
4)spark.DataFrame注冊臨時數據表并執行SQL查詢語句
暢想一下,可以在三種數據分析工具間任意切換使用了,比如在大數據階段用Spark,在數據過濾后再用Pandas的豐富API,偶爾再來幾句SQL!然而,理想很豐滿現實則未然:期間踩坑之深之廣,冷暖自知啊……

























