













AI智能語音識別算法 上篇
一、聲源定位
1、電掃陣列
當(dāng)系統(tǒng)掃描到輸出信號功率最大時所對應(yīng)的波束方向就是認(rèn)為是聲源的DOA方向,從而可以聲源定位。電掃陣列的方式存在一定的局限,僅僅適用于單一聲源。若多聲源在陣列方向圖的同一主波束內(nèi),則無法區(qū)分
2、超分辨譜估計
如MUSIC,ESPRIT算法等,對其協(xié)方差矩陣(相關(guān)矩陣)進行特征分解,構(gòu)造空間譜,關(guān)于方向的頻譜,譜峰對應(yīng)的方向即為聲源方向。適合多個聲源的情況,且聲源的分辨率與陣列尺寸無關(guān),突破了物理限制,因此成為超分辨譜方案。
3、TDOA
TDOA是先后估計聲源到達不同麥克風(fēng)的時延差,通過時延來計算距離差,再利用距離差和麥克風(fēng)陣列的空間幾何位置來確定聲源的位置。分為TDOA估計和TDOA定位兩步。
二、波束成形
1、CBF-傳統(tǒng)的波束形成
CBF是最簡單的非自適應(yīng)波束形成,對各個麥克風(fēng)的輸出進行加權(quán)求和得到波束,在CBF中,各個通道的權(quán)值是固定的,作用是抑制陣列方向圖的旁瓣電平,以濾除旁瓣區(qū)域的干擾和噪聲。
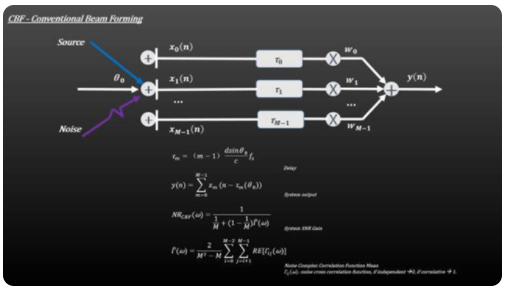
2、CBF + Adaptive Filter 增強型波束形成
CBF+Adaptive Filter結(jié)合Weiner濾波來改善語音增強的效果,帶噪語音經(jīng)過Weiner濾波得到基于LMS準(zhǔn)則的純凈語音信號。而濾波器系數(shù)可以不斷更新迭代,與傳統(tǒng)的CBF相比,可以更有效的去除非穩(wěn)態(tài)噪聲。
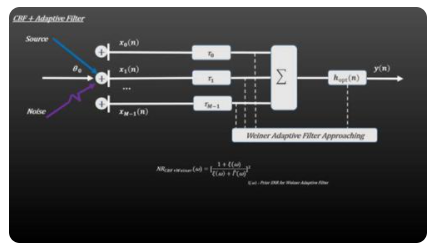
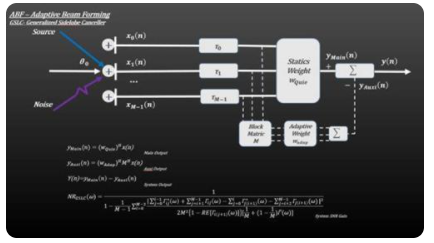
3、ABF-自適應(yīng)波束形成
ABF在CBF的基礎(chǔ)之上,對干擾和噪聲進行空域自適應(yīng)濾波。ABF中,采用不同的濾波器得到不同的算法,即不同通道的幅度加權(quán)值是根據(jù)某種最優(yōu)準(zhǔn)則進行調(diào)整和優(yōu)化。
三、語音增強
語音增強是指當(dāng)語音信號被各種各樣的噪聲(包括語音)干擾甚至淹沒后,從含噪聲的語音信號中提取出純凈語音的過程。
四、混響抑制
利用麥克風(fēng)陣列去混響的主要方法有以下幾種:
(1)基于盲語音增強的方法(Blind signal enhancement approach),即將混響信號作為普通的加性噪聲信號,在這個上面應(yīng)用語音增強算法。
(2)基于波束形成的方法(Beamforming based approach),通過將多麥克風(fēng)對收集的信號進行加權(quán)相加,在目標(biāo)信號的方向形成一個拾音波束,同時衰減來自其他方向的反射聲。
(3)基于逆濾波的方法(An inverse filtering approach),通過麥克風(fēng)陣列估計房間的房間沖擊響應(yīng)(Room Impulse Response, RIR),設(shè)計重構(gòu)濾波器來補償來消除混響。
五、噪聲抑制
語音識別不需要完全去除噪聲,相對來說通話系統(tǒng)中則必須完全去除噪聲。這里說的噪聲一般指環(huán)境噪聲,比如空調(diào)噪聲,這類噪聲通常不具有空間指向性,能量也不是特別大,不會掩蓋正常的語音,只是影響了語音的清晰度和可懂度。這種方法不適合強噪聲環(huán)境下的處理,但是足以應(yīng)付日常場景的語音交互。
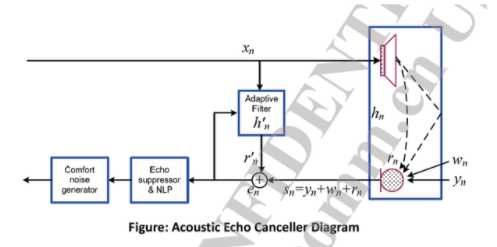
六、回聲消除
回聲消除就是在Mic采集到聲音之后,將本地音箱播放出來的聲音從Mic采集的聲音數(shù)據(jù)中消除掉,使得Mic錄制的聲音只有本地用戶說話的聲音。


















