













面試官:談談大數據采集和常見問題
大家好,我是一哥,今天給大家講解一下大數據面試中對于數據采集部分的一些問題。
01什么是數據采集
數據采集是大數據的基石,不論是現在的互聯網公司,物聯網公司或者傳統的IT公司,每個業務流程環節都會產生大量的數據,同時用戶操作的日志也會產生大量的數據,為了將這些結構化和非結構化的數據進行采集,我們必須要有一套完整的數據采集方案流程,為后續的數據分析應用提供數據基礎。
根據不同業務場景,對于數據采集的時效性要求也是不一樣的,一般分為離線數據采集和實時數據采集。

02離線數據采集
離線數據采集主要包括從數據庫中采集,如MySQL、Oracle、MongoDB等;從離線文件采集,如外部系統數據。每天凌晨會抽取前一天的數據(T+1),對于維度數據一般采用每次全量采集,對于業務數據,為了提高采集效率,同時也為了保住業務數據庫的穩定性,采用每天增量采集,然后將T+1的數據合并成新的全量數據。
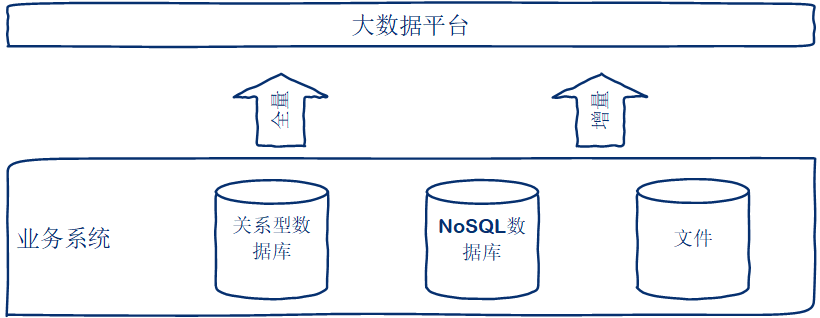
對于關系型數據庫,如MySQL,一般是有主從數據庫的,為了保住穩定和不影響主庫的查詢性能,我們一般抽取從庫數據。對于文件數據抽取前需要先檢測文件是否存在,源系統提供文件的時候需要提供對應的校驗文件,校驗文件里一般包含文件的記錄數、字段格式等信息。采集到文件后需要對文件進行校驗,文件完整的情況下才能繼續后續數據處理程序。

03實時數據采集
實時數據采集主要是一些頁面日志的采集,也就是我們常說的用戶行為分析數據。日志采集一般有以下幾個步驟:數據埋點,數據上報,數據存儲。
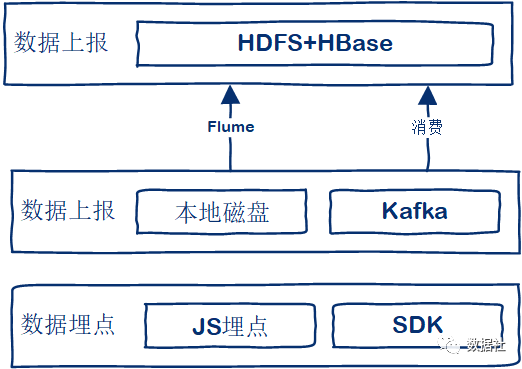
- 數據埋點:網站上線后一般會植入一段JS腳本,用戶訪問頁面時,JS會收集當前頁面的一些信息,用戶問的上下文信息以及當前訪問的頁面業務相關數據。
- 數據上報:JS執行完畢后,會將所有收集到的信息拼裝到一個請求內,通過日志請求將數據發送到日志服務器,存儲為JSON文件;一般情況下,在 JS 執行完成后就會立即向日志服務器發送消息隊列中。
- 數據存儲:存儲在磁盤上的文件會部署數據采集組件比如Flume,將采集到的日志數據發送到HDFS進行存儲或者轉存到HBase進行存儲。消息隊列的數據則可以直接消費落地到HDFS或者HBase進行存儲。

04數據采集的問題
是不是所有的日志數據都實時采集?
用戶的每個操作都會產生一個操作日志,但并不是每生成一條日志就實時上報至服務器,而是在產生日志后,先暫存在客戶端本地,再結合著相應的上報控制策略進行數據上報。其中上報策略主要指根據日志的業務特性,數據的時效性,用戶的網絡特性等等信息設定不同的上報策略,有些日志會因為其數據時效性的要求進行實時數據上報,而有些日志則會在用戶啟動應用,或者間隔一段時間后將日志上報上來。
總是找不到想要的埋點數據?
在實際業務數據采集中會發現每個模塊的業務數據格式都是不一樣的。因此就需要設計一種日志數據采集標準,可以針對特定的業務場景,制定通用的數據采集標識,研發人員在進行頁面埋點時,依據標準的數據采集標識規則進行埋點,從而收集業務的詳細信息。這個標準需要產品經理、前端開發人員、數據開發人員、數據分析人員、數據運營人員等多方達成一致,確保后面產品展現、埋點開發、模型開發、數據分析和運營能夠正常開發、解析、統計分析數據。
如何對多個業務生成唯一標識?
在數據埋點中如何唯一確定用戶的身份一件很重要的工作,因為如果做不到用戶的唯一標識,那么后續很多數據模型是無法構建的。所以在設計埋點標準時,一般會包含用的設備ID和用戶ID,關于設備ID安卓和IOS的方法也不一樣,大家可以搜索相關資料(https://zhuanlan.zhihu.com/p/152051748);用戶ID,也就是我們常說的注冊賬號。
05數據采集用到的大數據技術
在數據采集中用到了哪些大數據技術呢?可以看到數據采集組件,消息中間件,數據存儲組件等,后續我們來一一講解每個技術。
本文轉載自微信公眾號「數據社」,可以通過以下二維碼關注。轉載本文請聯系數據社公眾號。


























