企業(yè)微信萬(wàn)億級(jí)日志檢索系統(tǒng)
作者:datonli,騰訊 WXG 后臺(tái)開(kāi)發(fā)工程師
背景
開(kāi)發(fā)在定位問(wèn)題時(shí)需要查找日志,但企業(yè)微信業(yè)務(wù)模塊日志存儲(chǔ)在本機(jī)磁盤(pán),這會(huì)造成以下問(wèn)題:
- 日志查找效率低下:一次用戶(hù)請(qǐng)求涉及近十個(gè)模塊,幾十臺(tái)機(jī)器,查找日志需要登錄機(jī)器 grep 日志文件。這一過(guò)程通常需要耗費(fèi) 10 分鐘以上,非常低效;
- 日志保存時(shí)間短:?jiǎn)螜C(jī)磁盤(pán)存儲(chǔ)容量有限,為保存最新日志,清理腳本周期清理舊日志文件騰出磁盤(pán)空間,比如:現(xiàn)網(wǎng)一核心存儲(chǔ) 7 天日志占用了 90%的磁盤(pán)空間,7 天前日志都會(huì)被清理,用戶(hù)投訴因日志被清理而得不到解決;
- 日志缺失:雖然現(xiàn)網(wǎng)保留 7 天最新日志,但是由于某些模塊請(qǐng)求量大或日志打印不合理,我們也會(huì)限制一個(gè)小時(shí)日志打印量,超過(guò)閾值后不再保存,比如:現(xiàn)網(wǎng)一核心存儲(chǔ)前 10 分鐘打了 10G 日志達(dá)到閾值,后 50 分鐘日志不再保存了,用戶(hù)投訴因日志缺失無(wú)法得到解決。
我們希望有這樣一個(gè)日志系統(tǒng):
- 存儲(chǔ)全量日志:由于 To B 業(yè)務(wù)的特殊性,至少需要保存 30 天的全量日志(數(shù) PB 日志量,日志達(dá)數(shù)萬(wàn)億條),方便回查日志定位問(wèn)題;
- 日志快速定位:根據(jù)模塊+時(shí)間段+關(guān)鍵字或用戶(hù)請(qǐng)求信息快速定位日志;
- 實(shí)時(shí)性:日志峰值達(dá)數(shù)億條每秒,需要做到秒級(jí)入庫(kù)、秒級(jí)可查;
- 支持日志模糊匹配和統(tǒng)計(jì):?jiǎn)螜C(jī)日志查詢(xún)常用到模糊匹配以及 awk/uniq/sort 等復(fù)雜統(tǒng)計(jì),在新日志系統(tǒng)同樣希望能夠支持;
- 支持模塊級(jí)全量日志查詢(xún):日常運(yùn)營(yíng)中有些用戶(hù)投訴的問(wèn)題并不確定具體發(fā)生時(shí)間,需要對(duì)模塊進(jìn)行全量日志(日志量達(dá) TB 級(jí)別)查詢(xún)。
業(yè)界方案對(duì)比
公司內(nèi)外有很多日志系統(tǒng)方案,根據(jù)是否對(duì)日志做全文檢索可以分為兩類(lèi):
- 全文檢索的日志系統(tǒng):對(duì)日志內(nèi)容切分詞和建倒排,通過(guò)查詢(xún)關(guān)鍵詞的倒排取交集支持模糊匹配,這類(lèi)系統(tǒng)一般入庫(kù)資源消耗較多,也不支持日志統(tǒng)計(jì),典型實(shí)現(xiàn)有:ELK、Hermes 以及騰訊云日志服務(wù)(Cloud Log Service, CLS)等系統(tǒng);
- 部分字段檢索的日志系統(tǒng):只對(duì)部分字段建索引,支持特定字段的快速檢索,入庫(kù)資源消耗較低,但是這類(lèi)系統(tǒng)對(duì)模糊匹配未能很好支持,也不支持日志統(tǒng)計(jì),不支持模塊級(jí)全量日志查詢(xún),如 wxlog、LogTrace 等系統(tǒng)。
我們新設(shè)計(jì)的檢索系統(tǒng)在資源消耗較小的前提下,很好滿足背景所提的所有檢索需求。
方案設(shè)計(jì)的考慮
保存時(shí)間短和日志缺失的問(wèn)題
單機(jī)存儲(chǔ)空間的限制導(dǎo)致日志丟失,日志也沒(méi)法長(zhǎng)時(shí)間保存,如何突破單機(jī)存儲(chǔ)空間限制呢?
嗯,是的,使用分布式文件系統(tǒng)替換單機(jī)文件系統(tǒng)就可以了!在可水平擴(kuò)展的分布式文件系統(tǒng)支撐下,存儲(chǔ)空間無(wú)限大,日志不再因存儲(chǔ)空間而丟失了。
日志查找效率低下問(wèn)題
日志查找效率低下,其根源是日志散落到多臺(tái)機(jī)器,需要登錄到機(jī)器做日志 grep。引入了分布式文件系統(tǒng)存儲(chǔ)全網(wǎng)日志后,我們看到的仍然是一個(gè)一個(gè)不相關(guān)的日志文件,快速定位日志仍然困難。如何提高日志定位的效率呢?
索引!就像是利用索引提升數(shù)據(jù)庫(kù)表查詢(xún)效率一樣,我們對(duì)日志數(shù)據(jù)建立索引,快速定位到所需日志。那么,需要構(gòu)建怎樣的索引呢?先看看面臨的兩種問(wèn)題定位場(chǎng)景:
- 開(kāi)發(fā)收到模塊告警,通過(guò)告警信息結(jié)合代碼找到關(guān)鍵字,使用關(guān)鍵字查找模塊告警時(shí)間段內(nèi)的日志;
- 根據(jù)用戶(hù)投訴找到用戶(hù)請(qǐng)求信息,使用用戶(hù)請(qǐng)求信息查找所有關(guān)聯(lián)模塊的日志。從以上場(chǎng)景看出,我們通常根據(jù)模塊+時(shí)間段+關(guān)鍵字或者用戶(hù)請(qǐng)求信息查找日志。所以,對(duì)模塊、時(shí)間、用戶(hù)請(qǐng)求信息建索引提升日志查找效率。
入庫(kù)資源消耗問(wèn)題
為了支持模糊查詢(xún),業(yè)界方案一般都會(huì)對(duì)日志內(nèi)容分詞建索引,這會(huì)消耗大量資源。日志查詢(xún)系統(tǒng)有兩個(gè)特點(diǎn):每天只有數(shù)百次查詢(xún)請(qǐng)求,日志存儲(chǔ)模塊(分布式文件系統(tǒng))IO 密集、CPU 利用率低。為了支持用戶(hù)模糊查詢(xún)請(qǐng)求,入庫(kù)時(shí)不對(duì)日志內(nèi)容分詞建索引。用戶(hù)查詢(xún)時(shí),日志存儲(chǔ)模塊使用關(guān)鍵字對(duì)日志內(nèi)容正則匹配過(guò)濾(利用本機(jī)空閑 CPU)。這樣既解決了入庫(kù)資源消耗高的問(wèn)題,又解決了存儲(chǔ)機(jī) CPU 低利用率的問(wèn)題。
面臨的挑戰(zhàn)
我們通過(guò)分布式文件系統(tǒng)和索引解決了目前的問(wèn)題,同時(shí)也帶來(lái)了新的挑戰(zhàn):
高性能:目前企業(yè)微信日志量月級(jí)數(shù) PB,日志數(shù)萬(wàn)億條,天級(jí)數(shù)百 TB,面對(duì)如此海量日志,如何做到入庫(kù)和查詢(xún)的高性能?
可靠性:引入了分布式文件系統(tǒng)以及索引帶來(lái)更大的復(fù)雜性,如何保證整個(gè)日志系統(tǒng)可靠性?
支持靈活多變的用戶(hù)查詢(xún)需求:通過(guò)調(diào)研發(fā)現(xiàn),用戶(hù)主要有以下 4 種日志查詢(xún)使用場(chǎng)景:a) 一次用戶(hù)請(qǐng)求關(guān)聯(lián)的所有模塊日志查詢(xún);b) 模塊一段時(shí)間內(nèi)日志模糊查詢(xún);c) 模塊全量日志模糊查詢(xún);d) 查詢(xún)?nèi)罩窘y(tǒng)計(jì)(如:awk/uniq/sort 指令等)。如何支持如此靈活多變的用戶(hù)查詢(xún)需求?
名詞解釋
在介紹系統(tǒng)前,先對(duì)使用的名詞進(jìn)行解釋?zhuān)?/p>
callid:唯一標(biāo)識(shí)一次用戶(hù)請(qǐng)求,每條日志中都會(huì)攜帶 callid 信息;
模糊查詢(xún):根據(jù)用戶(hù)輸入模塊、時(shí)間段和關(guān)鍵字查詢(xún)?nèi)罩?
全鏈路查詢(xún):根據(jù) callid 查詢(xún)一次用戶(hù)請(qǐng)求所有關(guān)聯(lián)的模塊日志。
系統(tǒng)架構(gòu)
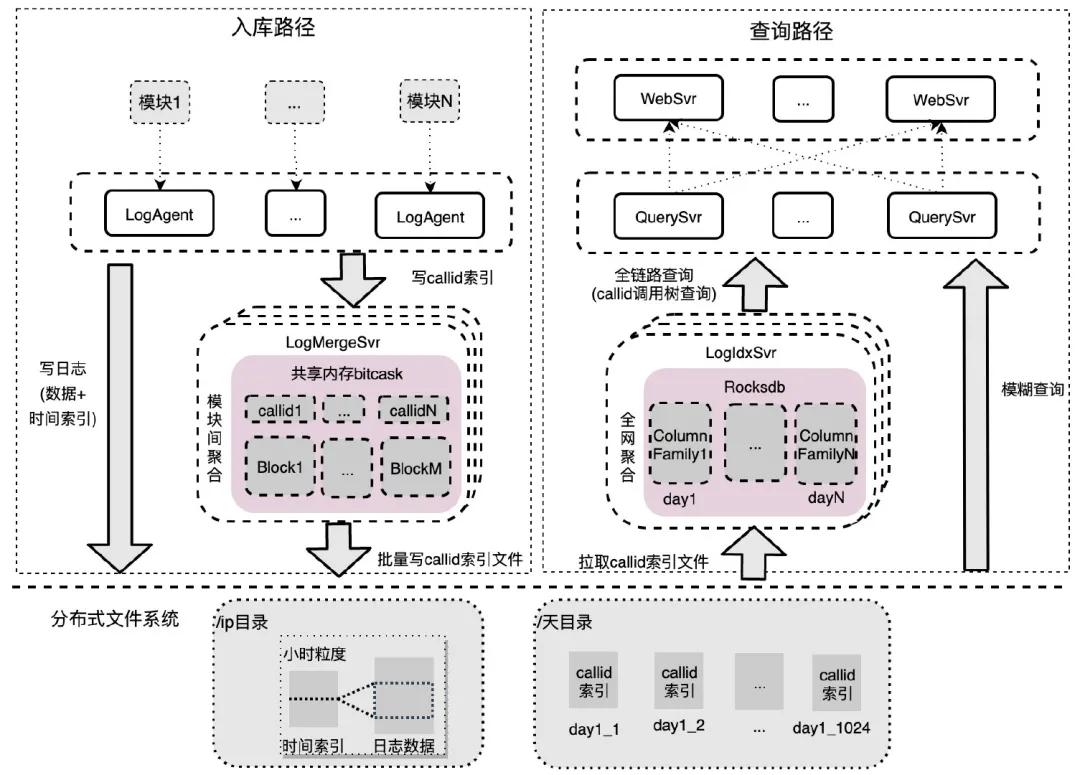
企業(yè)微信日志檢索系統(tǒng)主要分為 6 個(gè)模塊:
- LogAgent:和業(yè)務(wù)模塊同機(jī)部署,對(duì)模塊內(nèi)日志進(jìn)行聚集,數(shù)據(jù)批量寫(xiě)分布式文件系統(tǒng),callid 索引批量發(fā)送到 LogMergeSvr 聚集;
- LogMergeSvr:對(duì)一段時(shí)間內(nèi)的 callid 索引進(jìn)行模塊間聚集,批量寫(xiě)分布式文件系統(tǒng);
- 存儲(chǔ)模塊(分布式文件系統(tǒng)):存儲(chǔ)原始日志數(shù)據(jù)、時(shí)間索引和 callid 索引數(shù)據(jù);
- LogIdxSvr:對(duì) callid 索引進(jìn)行全網(wǎng)聚合,底層存儲(chǔ)用的是 Rocksdb;
- WebSvr:接收用戶(hù)網(wǎng)頁(yè)請(qǐng)求,并發(fā)查詢(xún) QuerySvr。
- QuerySvr:查詢(xún)執(zhí)行模塊,支持全鏈路查詢(xún)、模糊查詢(xún)、awk 統(tǒng)計(jì)等。
接下來(lái)分別闡述系統(tǒng)設(shè)計(jì)和實(shí)現(xiàn)中面臨的挑戰(zhàn)點(diǎn)以及解決辦法。
如何實(shí)現(xiàn)系統(tǒng)高性能
日志入庫(kù)高性能
目前,企業(yè)微信全網(wǎng)日志入庫(kù)峰值 qps 數(shù)億條每秒,而分布式文件系統(tǒng)數(shù)據(jù)節(jié)點(diǎn)僅僅 20 臺(tái)(單臺(tái) 12 塊 SATA 盤(pán),單盤(pán) IOPS 約 100 左右),我們?nèi)绾问褂蒙倭繑?shù)據(jù)節(jié)點(diǎn)支撐如此高峰值的日志秒級(jí)入庫(kù)呢?
數(shù)據(jù)入庫(kù)高性能
在模糊查詢(xún)場(chǎng)景下,用戶(hù)使用模塊/機(jī)器+時(shí)間段+關(guān)鍵字進(jìn)行查詢(xún)。為提升數(shù)據(jù)入庫(kù)性能,我們以每臺(tái)機(jī)器的 IP 作為分布式文件系統(tǒng)的目錄,機(jī)器上模塊打印的日志寫(xiě)入小時(shí)粒度的日志文件,這樣不同機(jī)器寫(xiě)入自己獨(dú)占的日志數(shù)據(jù)文件,相互間數(shù)據(jù)寫(xiě)入無(wú)競(jìng)爭(zhēng),入庫(kù)性能最佳。與此同時(shí),目錄結(jié)構(gòu)就相當(dāng)于一個(gè)快速區(qū)分不同模塊/機(jī)器的索引,這也能提升日志查詢(xún)效率。
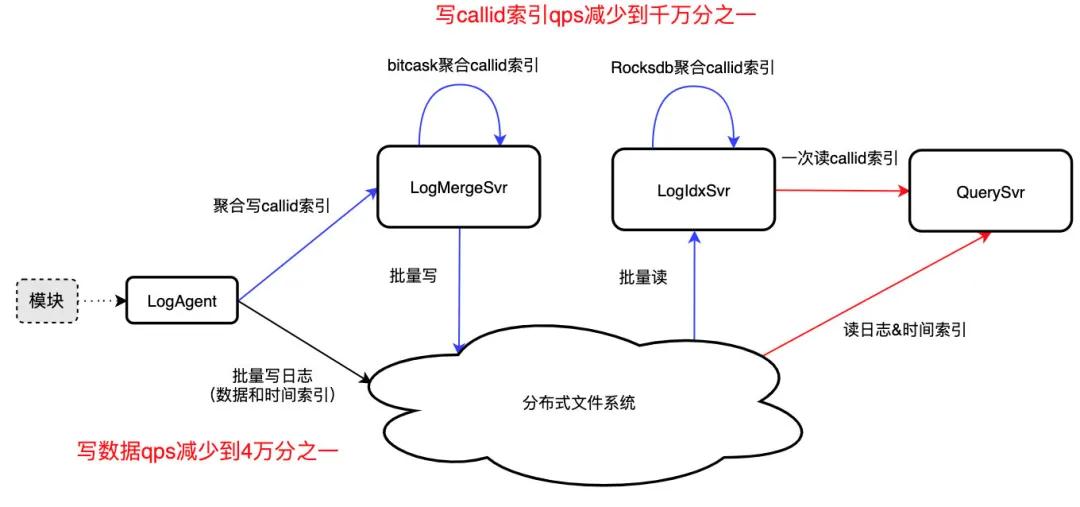
為了進(jìn)一步提升數(shù)據(jù)入庫(kù)性能,LogAgent 使用緩沖隊(duì)列緩存日志數(shù)據(jù),累積 8MB 數(shù)據(jù)后批量順序?qū)懭肴罩疚募校瑢?xiě) qps 降低為原本的 4 萬(wàn)分之一。同時(shí)為了快速查找日志數(shù)據(jù),對(duì) 8MB 日志數(shù)據(jù)的時(shí)間戳采樣,批量寫(xiě)入同目錄下的時(shí)間索引文件中。
callid 索引入庫(kù)高性能
同一 callid 索引散落在不同模塊不同機(jī)器,為了全鏈路查詢(xún),需要對(duì)數(shù)億條/秒的 callid 索引做秒級(jí)聚合,以支持秒級(jí)入庫(kù)、秒級(jí)可查,這無(wú)疑是一個(gè)技術(shù)難題。
為了解決這一難題,我們通過(guò)三重聚合減少 callid 索引寫(xiě)入壓力,最終達(dá)到 qps 減少到千萬(wàn)分之一、一次 IO 讀取 callid 所有日志位置的效果:
- 模塊內(nèi)聚合:LogAgent 聚合模塊內(nèi) callid 索引,批量寫(xiě)入 LogMergeSvr,qps 約減少到萬(wàn)分之一;
- 模塊間聚合:LogMergeSvr 聚合模塊間一段時(shí)間內(nèi)的 callid 索引,批量寫(xiě)分布式文件系統(tǒng),qps 約減少到千分之一;
- 全網(wǎng)聚合:callid 索引文件不利于高效讀取,LogIdxSvr 利用 Rocksdb 的 Merge 聚合全網(wǎng)的 callid 索引,一次 IO 可讀取 callid 所有日志位置。
日志查詢(xún)高性能
增加索引提升查詢(xún)性能
開(kāi)發(fā)通常依據(jù)模塊、時(shí)間段、callid 這 3 個(gè)維度查詢(xún)?nèi)罩荆瑸榱思涌觳樵?xún)性能也對(duì)這 3 個(gè)維度分別增加索引:
- 模塊:一個(gè)模塊包含若干機(jī)器,每臺(tái)機(jī)器在分布式文件系統(tǒng)中擁有獨(dú)占的日志目錄(用 IP 區(qū)分),用于保存機(jī)器小時(shí)粒度日志文件。通過(guò)模塊找到所有機(jī)器 IP 后,可快速找到該模塊的日志在分布式文件系統(tǒng)中的日志目錄。
- 時(shí)間段:日志數(shù)據(jù)保存在機(jī)器目錄的小時(shí)粒度文件中,通過(guò)對(duì)日志時(shí)間采樣保存為相應(yīng)時(shí)間索引文件。當(dāng)按照時(shí)間段查找日志時(shí),可根據(jù)時(shí)間索引文件快速找到該時(shí)間段的日志位置范圍。
- callid:解析日志建立 callid 到日志位置的索引,散落在多個(gè)模塊的 callid 索引通過(guò) LogAgent、LogMergeSvr 以及 LogIdxSvr 三重聚合后,最終存儲(chǔ)在 LogIdxSvr 的 Rocksdb 中。全鏈路日志查詢(xún)可通過(guò)讀取一次 Rocksdb 獲取所有相關(guān)日志位置,快速讀取到所需日志。
模糊查詢(xún)高性能
原始版本:并發(fā)檢索 WebSvr 接收用戶(hù)模糊查詢(xún)請(qǐng)求(模塊+時(shí)間段+關(guān)鍵字),依據(jù)模塊獲取機(jī)器列表后,按機(jī)器列表并發(fā)請(qǐng)求到多臺(tái) QuerySvr 執(zhí)行機(jī)器粒度日志查詢(xún):通過(guò)機(jī)器 IP 找到機(jī)器日志目錄,根據(jù)時(shí)間段拉取時(shí)間索引文件,確定日志數(shù)據(jù)范圍,并發(fā)拉取日志到本機(jī)用關(guān)鍵字做模糊匹配。最終將匹配后的日志返回給 WebSvr 聚合展示給用戶(hù)。
通過(guò)并發(fā)檢索的優(yōu)化手段,模糊查詢(xún)一個(gè)模塊一小時(shí)日志(12 臺(tái)機(jī)器,7.95GB 日志量)耗時(shí)從 1 分鐘降到 5.6 秒。
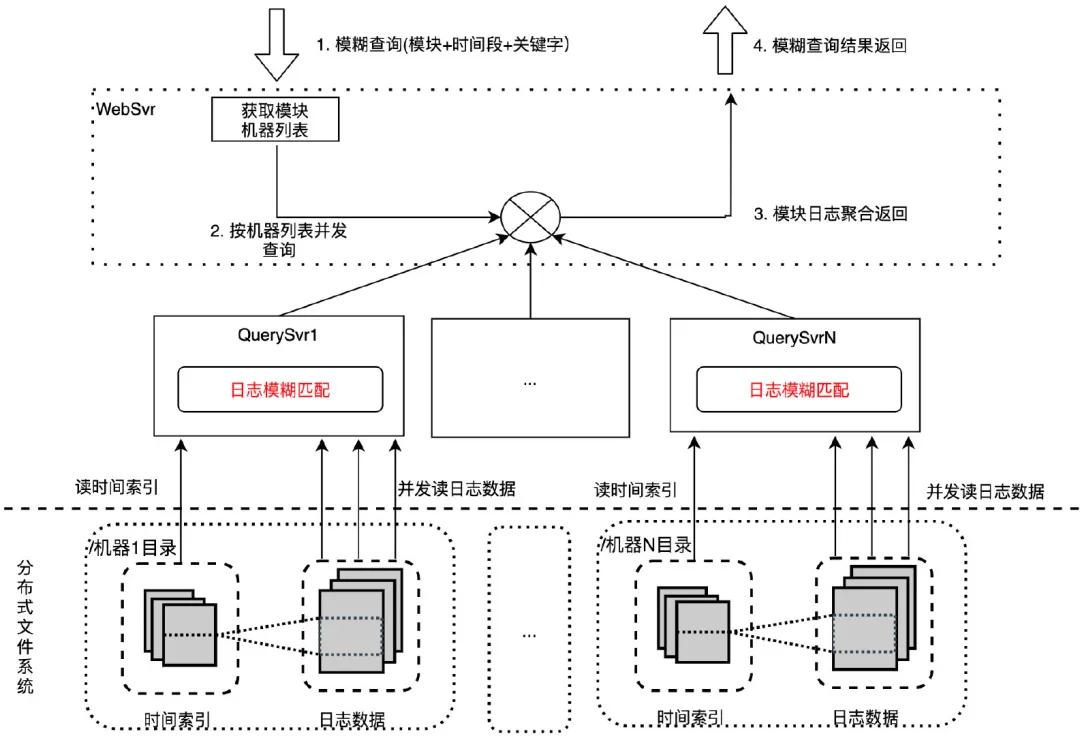
優(yōu)化版本:模糊匹配下沉分布式文件系統(tǒng) 在系統(tǒng)壓測(cè)時(shí)我們發(fā)現(xiàn) QuerySvr 帶寬和 cpu 存在性能瓶頸,原因是 QuerySvr 讀取大量未模糊匹配的日志數(shù)據(jù),打滿了網(wǎng)絡(luò)帶寬,并且在 QuerySvr 做模糊匹配也會(huì)消耗大量 cpu 資源。我們需要進(jìn)行性能優(yōu)化。考慮到分布式文件系統(tǒng)是重 IO 操作,cpu 利用率很低,將模糊匹配邏輯下沉到分布式文件系統(tǒng),這樣既解決了 QuerySvr 帶寬和 cpu 性能瓶頸問(wèn)題,又充分利用了文件系統(tǒng)的 cpu,避免資源浪費(fèi)。通過(guò)模糊匹配下沉的優(yōu)化手段,模糊查詢(xún)一個(gè)模塊一小時(shí)日志(12 臺(tái)機(jī)器,7.95GB 日志量)耗時(shí)從 5.6 秒降到 2.5 秒。
全鏈路查詢(xún)高性能
全鏈路查詢(xún)和模糊查詢(xún)類(lèi)似,同樣利用了并發(fā)提升查詢(xún)性能,稍有不同的是全鏈路查詢(xún)根據(jù) callid 讀取 LogIdxSvr 確定日志位置列表,按照位置列表并發(fā)讀取日志數(shù)據(jù),聚合后將日志返回給用戶(hù)。
如何保證系統(tǒng)可靠性
我們通過(guò)引入了分布式文件系統(tǒng)和索引服務(wù)解決了日志丟失、保存時(shí)間短和快速定位問(wèn)題,但系統(tǒng)復(fù)雜性導(dǎo)致的可靠性問(wèn)題,是我們面臨的第二大挑戰(zhàn)。
數(shù)據(jù)可靠性保證
日志數(shù)據(jù)緩沖隊(duì)列(共享內(nèi)存+本機(jī)磁盤(pán)文件)
LogAgent 負(fù)責(zé)將日志數(shù)據(jù)和時(shí)間索引寫(xiě)入分布式文件系統(tǒng),當(dāng)分布式文件系統(tǒng)抖動(dòng)時(shí),為了不丟棄待寫(xiě)日志數(shù)據(jù),LogAgent 使用緩沖隊(duì)列(共享內(nèi)存+本機(jī)磁盤(pán)文件)緩存日志數(shù)據(jù),待抖動(dòng)恢復(fù)后讀出緩存數(shù)據(jù)寫(xiě)入文件系統(tǒng)。
索引可靠性保證
服務(wù)抖動(dòng) LogIdxSvr 使用 Rocksdb 作為底層存儲(chǔ)聚合全網(wǎng) callid 索引,但是 Rocksdb 在高并發(fā)寫(xiě)入時(shí)容易出現(xiàn)寫(xiě)入抖動(dòng)進(jìn)而導(dǎo)致索引丟失,為了保證 callid 索引可靠性,LogMergeSvr 先將 callid 索引寫(xiě)入分布式文件系統(tǒng)保存,LogIdxSvr 從分布式文件系統(tǒng)拉,分布式文件系統(tǒng)當(dāng)做 queue 使用起到削峰填谷作用,保證 callid 索引可靠性。
機(jī)器壞盤(pán) LogIdxSvr 出現(xiàn)壞盤(pán)會(huì)導(dǎo)致已聚合到本機(jī)的 callid 索引數(shù)據(jù)丟失,新起的 LogIdxSvr 重新拉取分布式文件系統(tǒng)的 callid 索引文件,可以重建 Rocksdb 的 callid 索引,保證系統(tǒng)可靠性。
如何支持靈活多變的用戶(hù)查詢(xún)請(qǐng)求
通過(guò)前面的設(shè)計(jì),目前可以根據(jù)模塊+時(shí)間段+關(guān)鍵字或者 callid 查找到日志了,但是還不夠,用戶(hù)往往還需要對(duì)日志做任意維度模糊匹配、日志統(tǒng)計(jì)(如:uniq/sort/awk 等)以及模塊級(jí)全量日志查詢(xún)。
支持任意維度模糊匹配
如前所述,通過(guò)在分布式文件系統(tǒng)實(shí)現(xiàn)模糊匹配邏輯,系統(tǒng)支持對(duì)日志做任意維度模糊匹配的需求。通過(guò)對(duì)比,選擇性能最優(yōu)的 RE2 正則匹配庫(kù)實(shí)現(xiàn)模糊匹配邏輯。
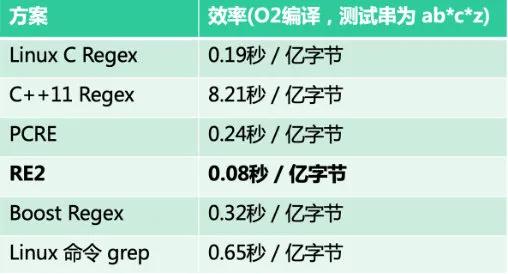
支持 awk/uniq/sort 等統(tǒng)計(jì)指令
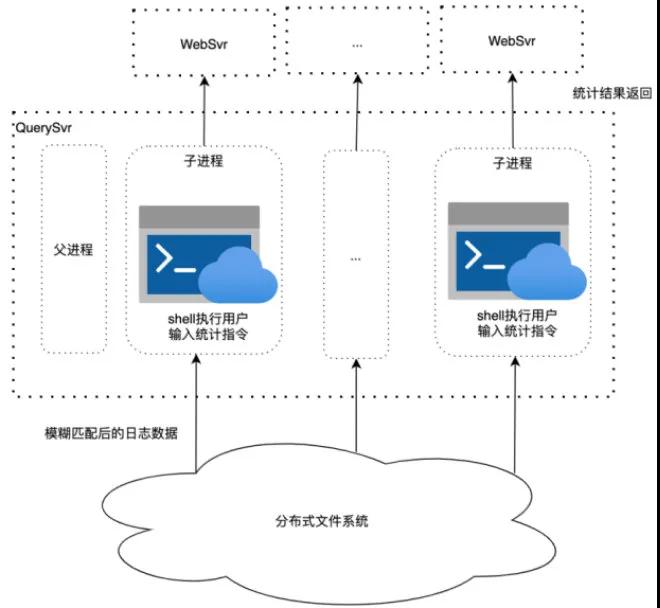
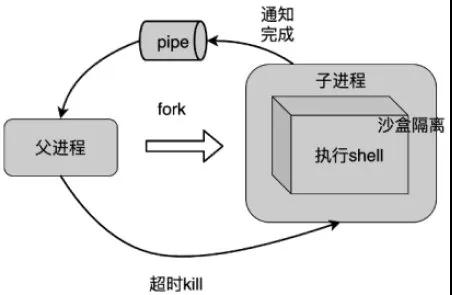
支持統(tǒng)計(jì)指令 用戶(hù)不僅需要對(duì)日志做模糊匹配,還需要對(duì)匹配后的日志執(zhí)行 awk/uniq/sort 等統(tǒng)計(jì)指令,其中涉及到指令相互嵌套執(zhí)行,非常復(fù)雜,難以調(diào)用相關(guān)庫(kù)實(shí)現(xiàn)。我們通過(guò)子進(jìn)程調(diào)用系統(tǒng) shell 支持這一需求。QuerySvr 從分布式文件系統(tǒng)拉取日志數(shù)據(jù)到本機(jī)后,子進(jìn)程 shell 調(diào)用用戶(hù)傳入統(tǒng)計(jì)指令處理日志數(shù)據(jù),最終結(jié)果返回給 WebSvr。子進(jìn)程處理超時(shí)父進(jìn)程將 kill 掉子進(jìn)程,防止用戶(hù)統(tǒng)計(jì)任務(wù)耗光 QuerySvr 資源。
安全考慮 由于用戶(hù)指令可由用戶(hù)自定義輸入,指令執(zhí)行的安全問(wèn)題需要重點(diǎn)考慮。通過(guò)兩個(gè)方法確保執(zhí)行指令的安全:
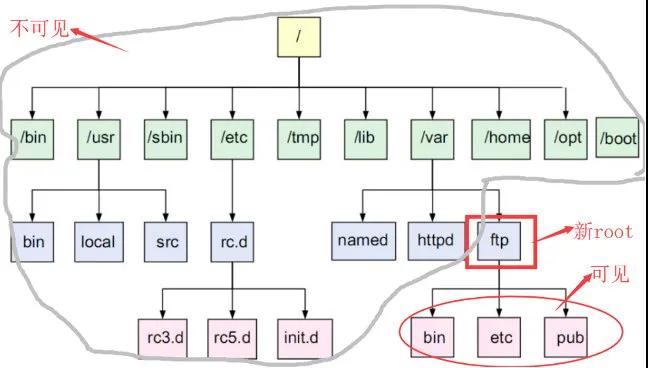
changeroot:使用 Linux 的 changeroot 避免用戶(hù)指令操作系統(tǒng)重要目錄;
沙盒限制:使用 Linux 支持的沙盒隔離技術(shù),只允許執(zhí)行特定指令。
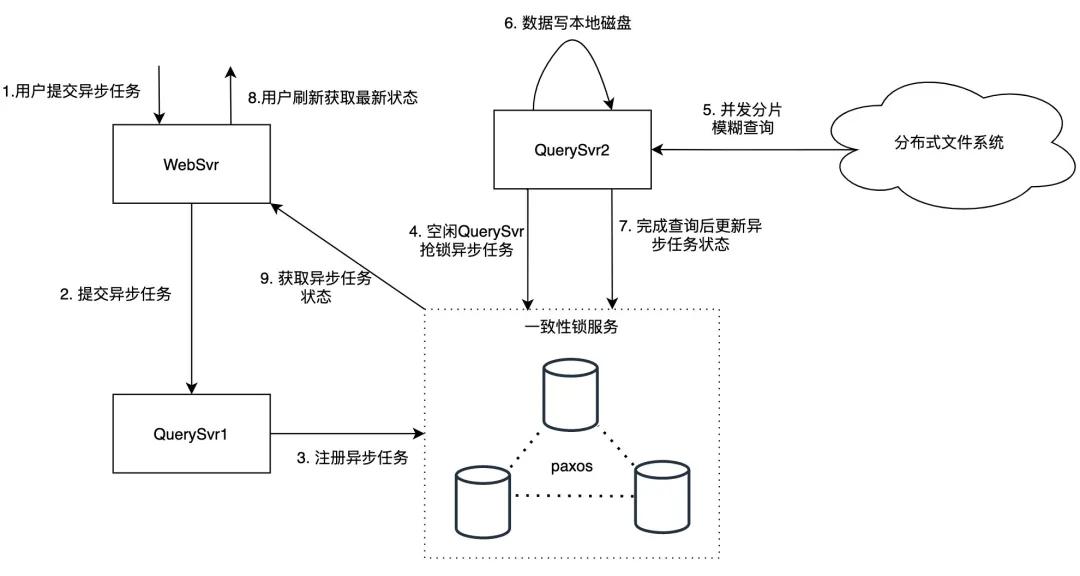
支持模塊級(jí)全量日志查詢(xún)——異步任務(wù)
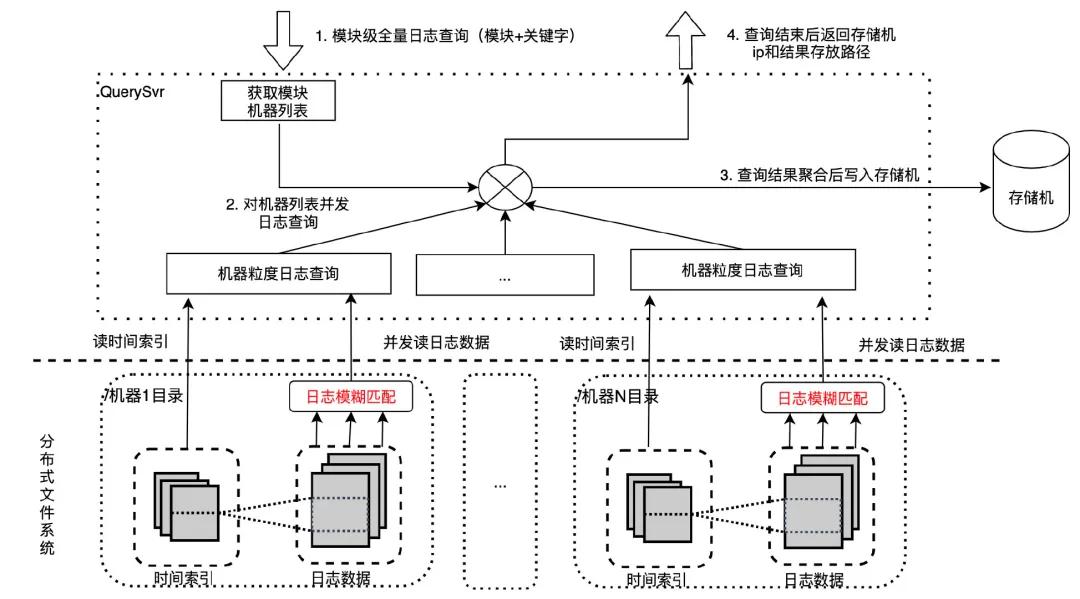
模塊級(jí)全量日志查詢(xún)通常涉及 TB 級(jí)別日志量,因?yàn)樯婕暗臄?shù)據(jù)量過(guò)大,查詢(xún)耗時(shí)一般較長(zhǎng),無(wú)法給用戶(hù)提供實(shí)時(shí)返回,我們通過(guò)提供異步任務(wù)功能支持這一需求。
用戶(hù)異步任務(wù)請(qǐng)求通過(guò) WebSvr 轉(zhuǎn)發(fā)到 QuerySvr,為避免 QuerySvr 宕機(jī)導(dǎo)致異步任務(wù)丟失,QuerySvr 會(huì)將異步任務(wù)寫(xiě)入一致性鎖服務(wù)中存儲(chǔ),空閑的 QuerySvr 會(huì)從一致性鎖服務(wù)搶鎖,搶鎖成功后執(zhí)行該異步任務(wù)。
QuerySvr 根據(jù)異步任務(wù)的模塊信息讀取機(jī)器列表,按照機(jī)器列表并發(fā)讀取匹配的日志數(shù)據(jù),按順序?qū)懭氡緳C(jī)磁盤(pán)中,在查詢(xún)結(jié)束后更新一致性鎖服務(wù)狀態(tài)(存儲(chǔ)機(jī) ip 和路徑),用戶(hù)頁(yè)面刷新會(huì)拉取到異步任務(wù)最新?tīng)顟B(tài)。