一款優(yōu)秀數(shù)據(jù)庫(kù)中間件的不完全解析
本文內(nèi)容概述
數(shù)據(jù)庫(kù)中間件有啥用
架構(gòu)剖析之高屋建瓴
2.1. 整體概述
2.2. 組件圖看架構(gòu)
細(xì)節(jié)剖析之一葉知秋
3.1. 配置加載和bean初始化
3.2. 細(xì)說(shuō)讀寫(xiě)分離
總結(jié)
Part1數(shù)據(jù)庫(kù)中間件有啥用
有一天,你去三亞玩耍,就想玩?zhèn)€沖浪,即時(shí)你不差錢(qián),難道還要自己采買(mǎi)快艇、滑板等等裝備來(lái)滿足這為數(shù)不多的心血來(lái)潮么。租一個(gè)就行了嘛。這其實(shí)就是連接池的作用。
數(shù)據(jù)庫(kù)中間件可以理解為是一種具有連接池功能,但比連接池更高級(jí)的、帶很多附加功能的輔助組件,不僅可以租沖浪板,還可以提供地點(diǎn)推薦、上保險(xiǎn)等等各類服務(wù)。
從網(wǎng)上的資料看,zdal應(yīng)該算是半開(kāi)源的,好像是之前開(kāi)源過(guò),但后續(xù)沒(méi)有準(zhǔn)備維護(hù),然后就刪除了,不過(guò)github被fork下來(lái)好多,隨便一搜就是一片,當(dāng)前,只是老的版本。目前螞蟻內(nèi)部的zdal好像已經(jīng)更新到zdal5了吧,那咱可就看不到了。
越復(fù)雜的系統(tǒng),數(shù)據(jù)庫(kù)中間件的作用越大。就拿zdal來(lái)說(shuō),它提供分庫(kù)分表,結(jié)果集合并,sql解析,數(shù)據(jù)庫(kù)failover動(dòng)態(tài)切換等數(shù)據(jù)訪問(wèn)層統(tǒng)一解決方案。下面就一起來(lái)看下,其內(nèi)部實(shí)現(xiàn)是怎么樣的。
Part2架構(gòu)剖析之高屋建瓴
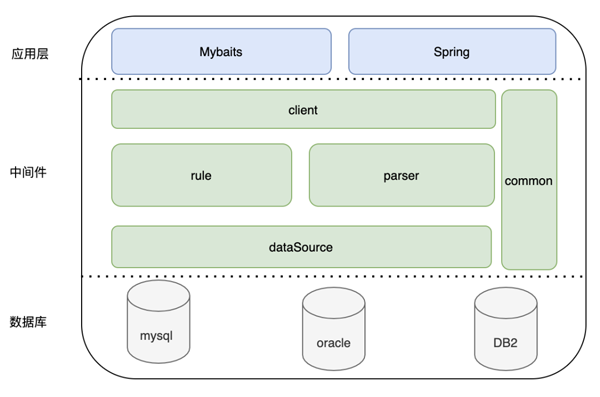
2.1整體概述
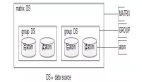
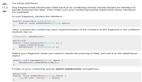
如上圖所示,zdal有四個(gè)重要的組成部分:
價(jià)值體現(xiàn)--客戶端Client包。對(duì)外暴露基本操作接口,用于業(yè)務(wù)層簡(jiǎn)單黑盒的操作數(shù)據(jù)源;業(yè)務(wù)只和client交互,動(dòng)態(tài)切換/路由等邏輯只需要進(jìn)行規(guī)則配置,相關(guān)邏輯由zdal實(shí)現(xiàn)。
核心功能--連接管理datasource包。最核心的能力,提供多種類型數(shù)據(jù)庫(kù)的連接管理;不管功能多花哨,最終目的還是為了解決數(shù)據(jù)庫(kù)連接的問(wèn)題。
關(guān)鍵能力--SQL解析parser包。基礎(chǔ)SQL解析能力;解析sql類型、字段名稱、數(shù)據(jù)庫(kù)等等,配合規(guī)則進(jìn)行路由
擴(kuò)展能力--庫(kù)表路由rule包。根據(jù)parser解析出的字段確定邏輯庫(kù)表和物理庫(kù)表。
2.2組件圖看架構(gòu)
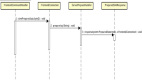
組件圖對(duì)整體架構(gòu)和各組件及相互聯(lián)系的理解可以起到很好的幫助。一個(gè)簡(jiǎn)版的組件圖畫(huà)了好久,還有不少錯(cuò),不過(guò)大概是這么個(gè)意思,哎,基本功要丟~
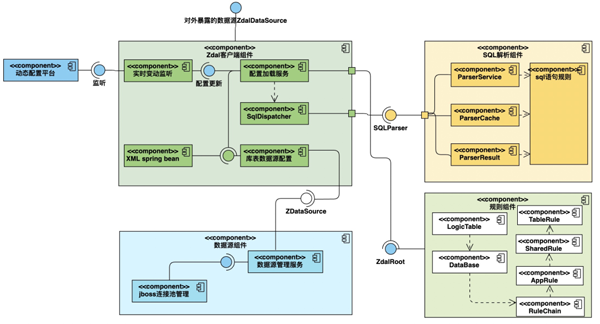
對(duì)照上圖可以比較清晰的看到:
Client包對(duì)應(yīng)用層暴露的數(shù)據(jù)源、負(fù)責(zé)監(jiān)聽(tīng)配置動(dòng)態(tài)變更的監(jiān)聽(tīng)組件、負(fù)責(zé)加載組織各部分的配置組件、負(fù)責(zé)加載spring bean 和庫(kù)表規(guī)則的配置組件;
Client中加載了規(guī)則組件,實(shí)現(xiàn)邏輯表和數(shù)據(jù)庫(kù)的路由規(guī)則。
Client中的庫(kù)表配置調(diào)用datasource中的數(shù)據(jù)源管理服務(wù)并構(gòu)建連接池的連接池;
Client中的SqlDispatcher服務(wù)調(diào)用SQL解析組件實(shí)現(xiàn)SQL解析。
Part3細(xì)節(jié)剖析之一葉知秋
3.1配置加載和bean初始化
大部分情況下,我們使用如mybatis這樣的ORM框架來(lái)進(jìn)行數(shù)據(jù)庫(kù)操作,其實(shí)不管是ORM還是其他方式,應(yīng)用層都需要對(duì)數(shù)據(jù)源進(jìn)行配置。
所以,client對(duì)外暴露了一個(gè)符合JDBC標(biāo)準(zhǔn)的datasource數(shù)據(jù)源,用來(lái)滿足應(yīng)用層ORM等框架配置數(shù)據(jù)源的要求--ZdalDataSource
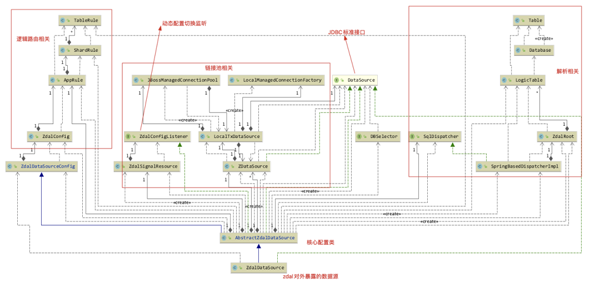
如圖片被壓縮看不清,后臺(tái)回復(fù)<zdal類圖>獲取
- //只提供了一個(gè)init方法,這也是spring啟動(dòng)時(shí)時(shí),必須要調(diào)用的初始化方法,所有功能,都從這里開(kāi)始
- public class ZdalDataSource extends AbstractZdalDataSource implements DataSource{
- public void init() {
- try {
- super.initZdalDataSource();
- } catch (Exception e) {
- CONFIG_LOGGER.error("...");
- throw new ZdalClientException(e);
- }
- }
ZdalDataSource#init() 方法即為配置加載的核心入口,init中負(fù)責(zé)加載spring配置,根據(jù)配置初始化數(shù)據(jù)源,并創(chuàng)建連接池,同時(shí),將邏輯表和物理庫(kù)的對(duì)應(yīng)關(guān)系都維護(hù)起來(lái)供后續(xù)路由調(diào)用。
- /*父類的init方法*/
- protected void initZdalDataSource() {
- /*用FileSystemXmlApplicationContext方式加載配置文件中的數(shù)據(jù)源和規(guī)則,轉(zhuǎn)化成zdalConfig對(duì)象*/
- this.zdalConfig = ZdalConfigurationLoader.getInstance().getZdalConfiguration(appName,dbmode, appDsName, configPath);
- this.dbConfigType = zdalConfig.getDataSourceConfigType();
- this.dbType = zdalConfig.getDbType();
- //初始化數(shù)據(jù)源
- this.initDataSources(zdalConfig);
- this.inited.set(true);
- }
- }
從上面的類圖和這里的兩個(gè)入口方法大概了解到zdal配置加載的啟動(dòng)流程。下面我們就來(lái)詳細(xì)看一下,讀寫(xiě)分離和分庫(kù)分表的規(guī)則是怎么被加載,怎么起作用的。
3.2細(xì)說(shuō)讀寫(xiě)分離
讀寫(xiě)分離配置的加載
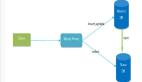
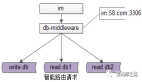
首先,我們需要有數(shù)據(jù)源的相關(guān)配置,如下圖:

圖片此XML配置會(huì)在init方法被調(diào)用時(shí),被初始化,解析成ZdalConfig類的屬性,ZdalConfig類的主要成員見(jiàn)下面代碼:
- public class ZdalConfig {
- /** key=dsName;value=DataSourceParameter 所有物理數(shù)據(jù)源的配置項(xiàng),比如用戶名,密碼,庫(kù)名等 */
- private Map<String, DataSourceParameter> dataSourceParameters = new ConcurrentHashMap<String, DataSourceParameter>();
- /** 邏輯數(shù)據(jù)源和物理數(shù)據(jù)源的對(duì)應(yīng)關(guān)系:key=logicDsName,value=physicDsName */
- private Map<String, String> logicPhysicsDsNames = new ConcurrentHashMap<String, String>();
- /** 數(shù)據(jù)源的讀寫(xiě)規(guī)則,比如只讀,或讀寫(xiě)等配置*/
- private Map<String, String> groupRules = new ConcurrentHashMap<String, String>();
- /** 異常轉(zhuǎn)移的數(shù)據(jù)源規(guī)則*/
- private Map<String, String> failoverRules = new ConcurrentHashMap<String, String>();
- //一份完整的讀寫(xiě)分離和分庫(kù)分表規(guī)則配置
- private AppRule appRootRule;
可以看到,xml中的規(guī)則,被解析到xxxRules里。這里以groupRules為例,failover同理。
下一步則是通過(guò)解析得到的zdalConfig 來(lái)初始化數(shù)據(jù)源:
- protected final void initDataSources(ZdalConfig zdalConfig) {
- //DataSourceParameter中存的是數(shù)據(jù)源參數(shù),如用戶名密碼,最大最小連接數(shù)等
- for (Entry<String, DataSourceParameter> entry : zdalConfig.getDataSourceParameters().entrySet()) {
- try {
- //初始化連接池
- ZDataSource zDataSource = new ZDataSource(/*設(shè)置最大最小連接數(shù)*/createDataSourceDO(entry.getValue(),zdalConfig.getDbType(), appDsName + "." + entry.getKey()));
- this.dataSourcesMap.put(entry.getKey(), zDataSource);
- } catch (Exception e) {
- //...
- }
- }
- //其他分支略,只看最簡(jiǎn)單的分組模式
- if (dbConfigType.isGroup()) {
- //讀寫(xiě)配置賦值
- this.rwDataSourcePoolConfig = zdalConfig.getGroupRules();
- //初始化多份讀庫(kù)下的負(fù)載均衡
- this.initForLoadBalance(zdalConfig.getDbType());
- }
- //注冊(cè)監(jiān)聽(tīng):為了滿足動(dòng)態(tài)切換
- this.initConfigListener();
- }
initForLoadBalance的方法如下:
- private void initForLoadBalance(DBType dbType) {
- Map<String, DBSelector> dsSelectors = this.buildRwDbSelectors(this.rwDataSourcePoolConfig);
- this.runtimeConfigHolder.set(new ZdalRuntime(dsSelectors));
- this.setDbTypeForDBSelector(dbType);
- }
可以看到,首先構(gòu)建出了DB選擇器,然后賦值給了runtimeConfigHolder供運(yùn)行時(shí)獲取。而構(gòu)建DB選擇器的時(shí)候,其實(shí)是按讀寫(xiě)兩個(gè)維度,把所有數(shù)據(jù)源都構(gòu)建了一遍,即group_r和group_w下都包含5個(gè)數(shù)據(jù)源,只不過(guò)各自的權(quán)重不一樣:
- //比如按上面的配置寫(xiě)庫(kù)只有一個(gè),但是也會(huì)包含全數(shù)據(jù)源
- group_0_w_0 :< bean:read0DataSource , writeWeight:0>
- group_0_w_1 :< bean:writeDataSource , writeWeight:10>
- group_0_w_2 :< bean:read1DataSource , writeWeight:0>
- group_0_w_3 :< bean:read2DataSource , writeWeight:0>
- group_0_w_4 :< bean:read3DataSource , writeWeight:0>
- //上述就是寫(xiě)相關(guān)的DBSelecter的內(nèi)容。
讀寫(xiě)分離怎么起作用
以delete為例,更新刪除是要操作寫(xiě)庫(kù)的
- public void delete(ZdalDataSource dataSource) {
- String deleteSql = "delete from test";
- Connection conn = null;
- PreparedStatement pst = null;
- try {
- conn = dataSource.getConnection();
- pst = conn.prepareStatement(deleteSql);
- pst.execute();
- } catch (Exception e) {
- //...
- } finally {
- //資源關(guān)閉
- }
- }
getConnection會(huì)從上文中提到的runtimeConfigHolder中獲取DBSelecter,然后執(zhí)行execute方法
- public boolean execute() throws SQLException {
- SqlType sqlType = getSqlType(sql);
- // SELECT相關(guān)的就選擇group_r對(duì)應(yīng)的DBSelecter
- if (sqlType == SqlType.SELECT || sqlType == SqlType.SELECT_FOR_UPDATE|| sqlType == SqlType.SELECT_FROM_DUAL) {
- //略
- return true;
- //update/delete相關(guān)的就選擇group_w對(duì)應(yīng)的DBSelecter
- } else if (sqlType == SqlType.INSERT || sqlType == SqlType.UPDATE|| sqlType == SqlType.DELETE) {
- if (super.dbConfigType == DataSourceConfigType.GROUP) {
- executeUpdate0();
- } else {
- executeUpdate();
- }
- return false;
- }
如果是讀取相關(guān)的,那就選_r的DBSelecter,如果是寫(xiě)相關(guān)的,那就選_W的DBSelecter。那么executeUpdate0中是怎么執(zhí)行區(qū)分讀寫(xiě)數(shù)據(jù)源的呢,其實(shí)就是把這一組的數(shù)據(jù)源根據(jù)權(quán)重篩選一遍。
- // WeightRandom#select(int[], java.lang.String[])
- private String select(int[] areaEnds, String[] keys) {
- //這里的areaEnds數(shù)組,是一個(gè)累加范圍值數(shù)據(jù)
- //比如三個(gè)庫(kù)權(quán)重 10 9 8
- //那么areaEnds就是 10 19 27 是對(duì)每個(gè)權(quán)重的累加,最后一個(gè)值是總和
- int sum = areaEnds[areaEnds.length - 1];
- //這樣隨機(jī)出來(lái)的數(shù),是符合權(quán)重分布的
- int rand = random.nextInt(sum);
- for (int i = 0; i < areaEnds.length; i++) {
- if (rand < areaEnds[i]) {
- return keys[i];
- }
- return null;
- }
Part4總結(jié)
本篇文章,把阿里數(shù)據(jù)庫(kù)中間件相關(guān)的組件和加載流程進(jìn)行了總結(jié),就一個(gè)最基本的分組讀寫(xiě)分離的流程,對(duì)內(nèi)部實(shí)現(xiàn)進(jìn)行了闡述。說(shuō)是解析,其實(shí)是提供給大家一種閱讀的思路,畢竟篇幅有限,如果對(duì)中間件感興趣的同學(xué),可以fork下代碼,按上述邏輯自己閱讀下。
看源碼時(shí),比如dubbo這些中間件其實(shí)是比較容易入手的,因?yàn)樗麄兌家劳杏赟pring進(jìn)行JavaBean的裝載,所有,對(duì)Spring容器暴露的那些init、load方法,就是很好的切入點(diǎn)。個(gè)人思路,希望對(duì)大家有所幫助。