













谷歌第四代TPU性能實測來了!今年將向谷歌云用戶提供服務
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
一個TPU v4 pod就能達到1 exaflop級的算力,實現每秒10的18次方浮點運算。
缺席一年后的谷歌I/O大會,真的不負眾望。

除了讓谷歌AI掌門人Jeff Dean都直呼“魔鏡”的Starline的3D視頻通話技術,第四代TPU也是備受矚目。
谷歌介紹,TPU v4將主要以pod形式應用,一個pod由4096個TPU v4單芯片組成,可以達到1 exaflop級的算力,這相當于1000萬臺筆記本電腦之和。
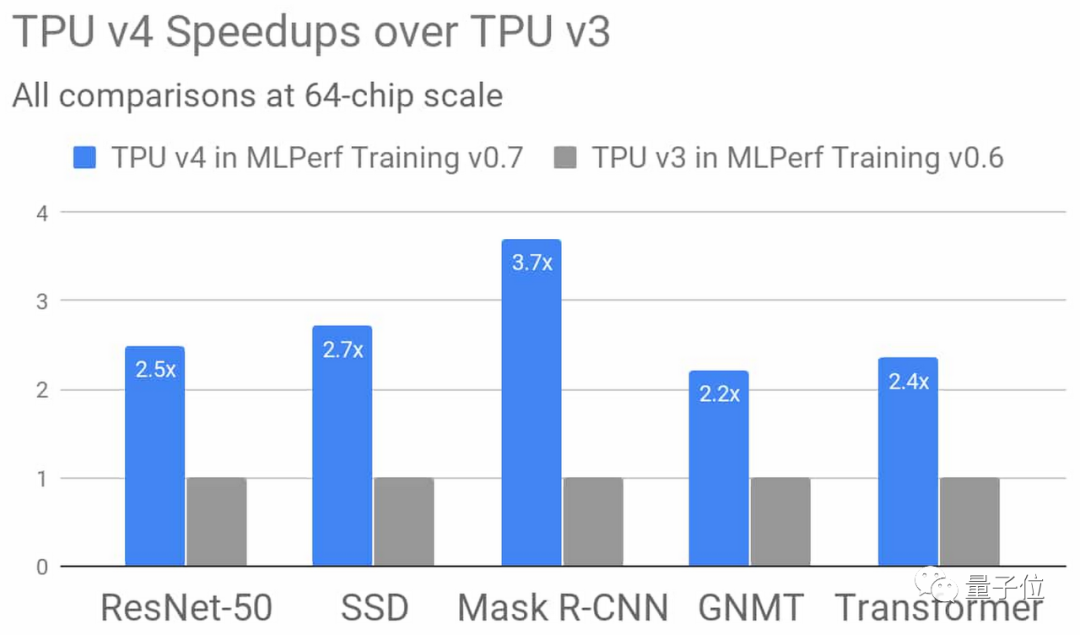
與上一代TPU v3相比,在64個芯片的規模下,TPU v4的性能平均提升了2.7倍。
除此之外,TPU v4 pod的性能較TPU v3 pod提升了10倍。將主要以無碳能源運行,不僅計算更快,而且更加節能。
谷歌CEO桑達爾·皮查伊(Sundar Pichai)透露,TPU v4 pod將會應用在谷歌的數據中心,并在今年內向谷歌云用戶提供服務。
兩分鐘跑完BERT訓練
雖然剛剛才正式發布,但早在一年前,谷歌就提前透露了TPU v4的性能。
在去年7月發布的人工智能權威“跑分”MLPerf訓練v0.7榜單中,我們可以看到TPU v4與各家芯片的性能對比。
在MLPerf訓練測試中,其基準包括圖像分類、翻譯、推薦系統和圍棋等8個機器學習任務中,最終結果是這8項任務的訓練時間,速度越快則性能越強。
具體的8項任務內容如下:
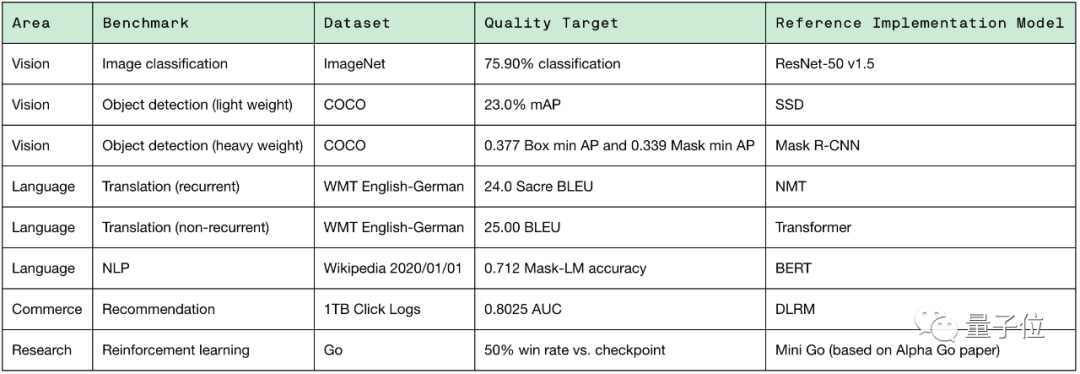
具體訓練模型為:ResNet-50、SSD、Mask R-CNN、BERT、NMT、Transformer、DLRM和Mini Go。
TPU v4的表現情況如下,每個系統都以TPU v4加速器的數量來區分,分別為8、64、256.
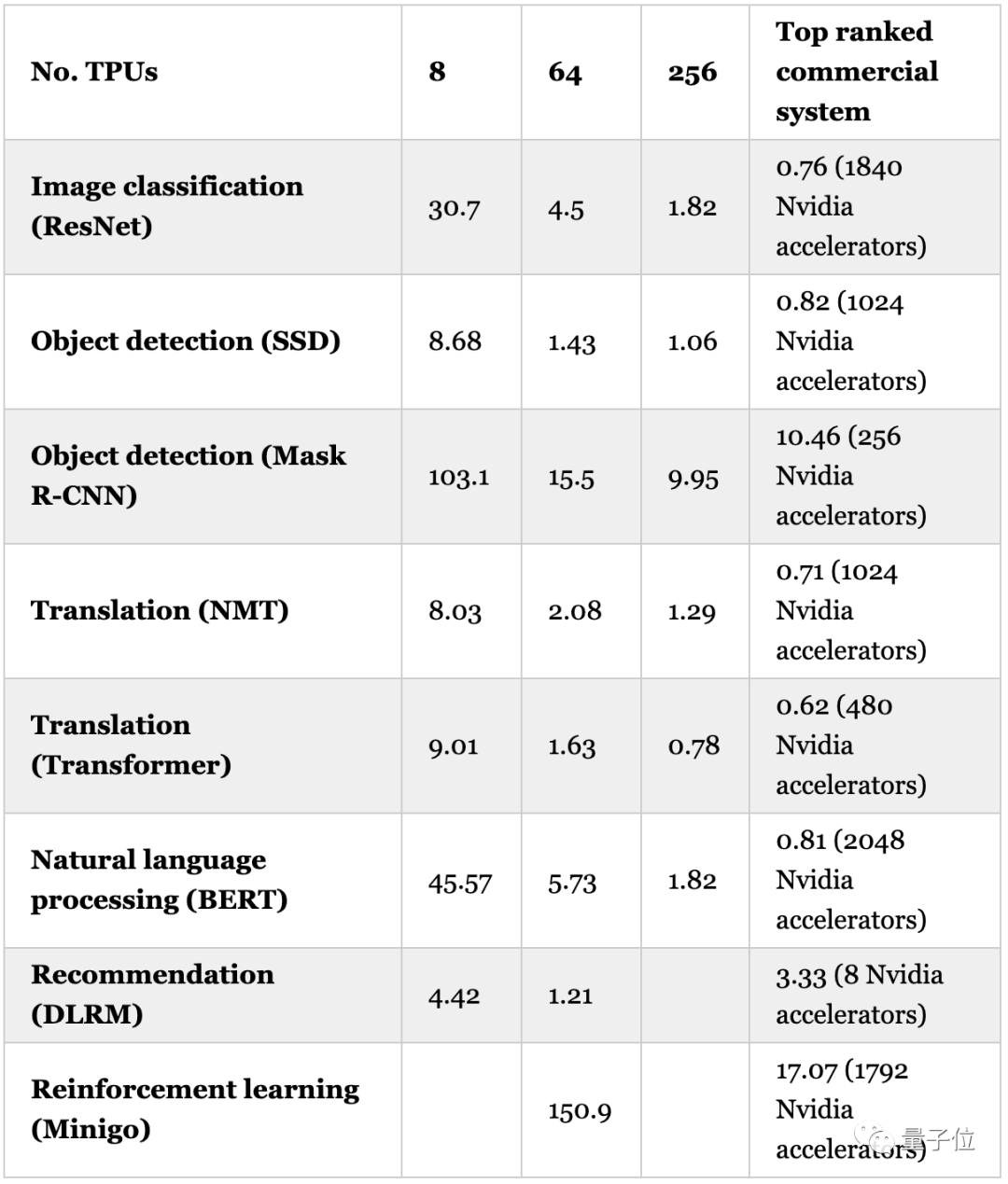
從對比中可以看到:
在ResNet訓練中,256塊TPU v4將時長縮短到1.82分鐘;
但是Nvidia A100A100-SXM4-40GB想要達到這一水平,至少需要768塊加速。
在BERT的訓練中,256塊TPU v4也將時長縮短到1.82分鐘;
同樣256塊Nvidia A100-SXM4-40GB,僅能把訓練時長縮短到3.36分鐘。
并且從公布的數據來看,4096塊第三代TPU組成的TPU v3 pod就可以將BERT訓練壓縮到只有23秒!
關于TPU
簡單來說,TPU就是谷歌開發的一種可以加速機器學習的芯片。
不同于GPU,TPU是一種ASIC芯片,即應用型專用集成電路(Application-Specific Integrated Circuit),是一種專為某種特定應用需求而定制的芯片。

為什么要研發TPU呢?
其實是因為谷歌自身的許多產品和服務,比如谷歌圖像搜索、谷歌翻譯,都需要運用深度學習神經網絡。
這就對算力有了更高的需求,一般的GPU、CPU很難維持。
所以,TPU應運而生。
第一代TPU被應用到了大名鼎鼎的AlphaGo上,在2015年和李世英對戰時,就是部署了48個TPU。
到了第二代TPU,它被引入了Google Cloud,應用在谷歌計算引擎(Google Compute Engine ,簡稱GCE)中,也稱為Cloud TPU。
配置了TPU v2的AlphaGo,僅用了4塊TPUv2,便擊敗當時的世界圍棋冠軍柯潔。
2018年,谷歌發布第三代TPU,性能提升到第二代的2倍。
每個Pod的性能提高了8倍,且每個pod最多可含1024個芯片。
而第四代TPU,直到2021年才正式和大家見面。

















