













讓我們一起學(xué)習(xí)管道模式,你會(huì)了嗎?
本文轉(zhuǎn)載自微信公眾號(hào)「JavaKeeper」,作者海星。轉(zhuǎn)載本文請(qǐng)聯(lián)系JavaKeeper公眾號(hào)。
管道模式,不屬于23種設(shè)計(jì)模式之一(是責(zé)任鏈模式的一種變體),但是在我們實(shí)際業(yè)務(wù)架構(gòu)中還是有很多場(chǎng)景適用的,主要用于將復(fù)雜的進(jìn)程分解成多個(gè)獨(dú)立的子任務(wù),像流水線一樣去執(zhí)行,了解一下唄
一、開場(chǎng)
假設(shè)我們有這樣的一個(gè)需求,讀取文件內(nèi)容,并過濾包含 “hello” 的字符串,然后將其反轉(zhuǎn)

Linux 一行搞定
- cat hello.txt | grep "hello" | rev
用世界上最好語(yǔ)言 Java 實(shí)現(xiàn)也很簡(jiǎn)單
- File file = new File("/Users/starfish/Documents/hello.txt");
- String content = FileUtils.readFileToString(file,"UTF-8");
- List<String> helloStr = Stream.of(content).filter(s -> s.contains("hello")).collect(Collectors.toList());
- System.out.println(new StringBuilder(String.join("",helloStr)).reverse().toString());
再假設(shè)我們上邊的場(chǎng)景是在一個(gè)大型系統(tǒng)中,有這樣的數(shù)據(jù)流需要多次進(jìn)行復(fù)雜的邏輯處理,還是簡(jiǎn)單粗暴的把一系列流程像上邊那樣放在一個(gè)大組件中嗎?
這樣的設(shè)計(jì)完全違背了單一職責(zé)原則,我們?cè)谠龈模蛘邷p少一些處理邏輯的時(shí)候,就必須對(duì)整個(gè)組件進(jìn)行改動(dòng)。可擴(kuò)展性和可重用性幾乎沒有~~
那有沒有一種模式可以將整個(gè)處理流程進(jìn)行詳細(xì)劃分,劃分出的每個(gè)小模塊互相獨(dú)立且各自負(fù)責(zé)一小段邏輯處理,這些小模塊可以按順序連起來(lái),前一模塊的輸出作為后一模塊的輸入,最后一個(gè)模塊的輸出為最終的處理結(jié)果呢?
如此一來(lái)修改邏輯時(shí)只針對(duì)某個(gè)模塊修改,添加或減少處理邏輯也可細(xì)化到某個(gè)模塊顆粒度,并且每個(gè)模塊可重復(fù)利用,可重用性大大增強(qiáng)。
恩,這就是我們要說(shuō)的管道模式

二、定義
管道模式(Pipeline Pattern) 是責(zé)任鏈模式(Chain of Responsibility Pattern)的常用變體之一。
顧名思義,管道模式就像一條管道把多個(gè)對(duì)象連接起來(lái),整體看起來(lái)就像若干個(gè)閥門嵌套在管道中,而處理邏輯就放在閥門上,需要處理的對(duì)象進(jìn)入管道后,分別經(jīng)過各個(gè)閥門,每個(gè)閥門都會(huì)對(duì)進(jìn)入的對(duì)象進(jìn)行一些邏輯處理,經(jīng)過一層層的處理后從管道尾出來(lái),此時(shí)的對(duì)象就是已完成處理的目標(biāo)對(duì)象。
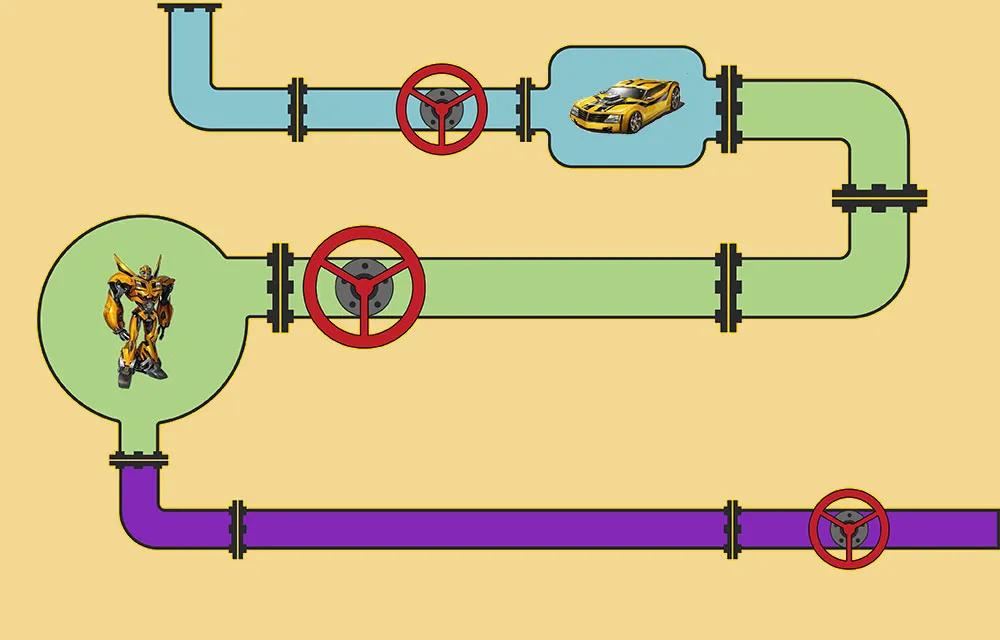
管道模式用于將復(fù)雜的進(jìn)程分解成多個(gè)獨(dú)立的子任務(wù)。每個(gè)獨(dú)立的任務(wù)都是可復(fù)用的,因此這些任務(wù)可以被組合成復(fù)雜的進(jìn)程。
PS:純的責(zé)任鏈模式在鏈上只會(huì)有一個(gè)處理器用于處理數(shù)據(jù),而管道模式上多個(gè)處理器都會(huì)處理數(shù)據(jù)。
三、角色
管道模式:對(duì)于管道模式來(lái)說(shuō),有 3 個(gè)對(duì)象:
- 閥門:處理數(shù)據(jù)的節(jié)點(diǎn),或者叫過濾器、階段
- 管道:組織各個(gè)閥門
- 客戶端:構(gòu)造管道,并調(diào)用
四、實(shí)例
程序員還是看代碼消化才快些,我們用管道模式實(shí)現(xiàn)下文章開頭的小需求
1、處理器(管道的各個(gè)階段)
- public interface Handler<I,O> {
- O process(I input);
- }
2、定義具體的處理器(閥門)
- public class FileProcessHandler implements Handler<File,String>{
- @Override
- public String process(File file) {
- System.out.println("===文件處理===");
- try{
- return FileUtils.readFileToString(file,"UTF-8");
- }catch (IOException e){
- e.printStackTrace();
- }
- return null;
- }
- }
- public class CharacterFilterHandler implements Handler<String, String> {
- @Override
- public String process(String input) {
- System.out.println("===字符過濾===");
- List<String> hello = Stream.of(input).filter(s -> s.contains("hello")).collect(Collectors.toList());
- return String.join("",hello);
- }
- }
- public class CharacterReverseHandler implements Handler<String,String>{
- @Override
- public String process(String input) {
- System.out.println("===反轉(zhuǎn)字符串===");
- return new StringBuilder(input).reverse().toString();
- }
- }
3、管道
- public class Pipeline<I,O> {
- private final Handler<I,O> currentHandler;
- Pipeline(Handler<I, O> currentHandler) {
- this.currentHandler = currentHandler;
- }
- <K> Pipeline<I, K> addHandler(Handler<O, K> newHandler) {
- return new Pipeline<>(input -> newHandler.process(currentHandler.process(input)));
- }
- O execute(I input) {
- return currentHandler.process(input);
- }
- }
4、 客戶端使用
- import lombok.val;
- public class ClientTest {
- public static void main(String[] args) {
- File file = new File("/Users/apple/Documents/hello.txt");
- val filters = new Pipeline<>(new FileProcessHandler())
- .addHandler(new CharacterFilterHandler())
- .addHandler(new CharacterReverseHandler());
- System.out.println(filters.execute(file));
- }
- }
5、結(jié)果
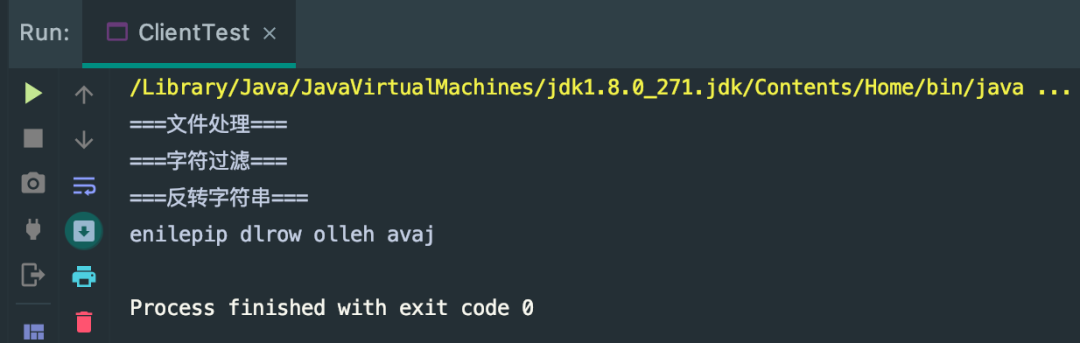
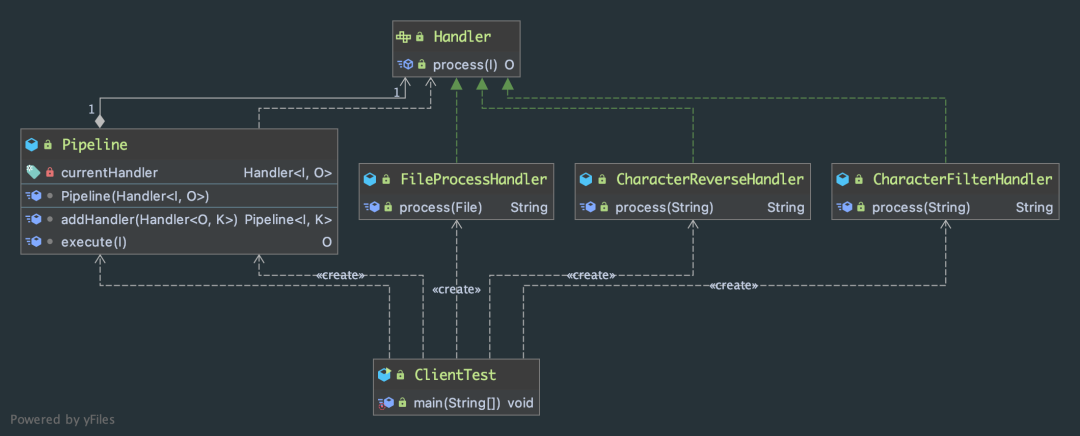
UML 類圖
產(chǎn)品他么的又來(lái)了,這次是刪除 hello.txt 中的 world 字符
三下五除二,精通 shell 編程的我搞定了
- cat hello.txt |grep hello |rev | tr -d 'world'
Java 怎么搞,你應(yīng)該很清晰了吧
五、優(yōu)缺點(diǎn)
Pipeline 模式的核心思想是將一個(gè)任務(wù)處理分解為若干個(gè)處理階段(Stage),其中每個(gè)處理階段的輸出作為下一個(gè)處理階段的輸入,并且各個(gè)處理階段都有相應(yīng)的工作者線程去執(zhí)行相應(yīng)的計(jì)算。因此,處理一批任務(wù)時(shí),各個(gè)任務(wù)的各個(gè)處理階段是并行(Parallel)的。通過并行計(jì)算,Pipeline 模式使應(yīng)用程序能夠充分利用多核 CPU 資源,提高其計(jì)算效率。 ——《Java 多線程編程實(shí)戰(zhàn)指南》
優(yōu)點(diǎn)
- 將復(fù)雜的處理流程分解成獨(dú)立的子任務(wù),解耦上下游處理邏輯,也方便您對(duì)每個(gè)子任務(wù)的測(cè)試
- 被分解的子任務(wù)還可以被不同的處理進(jìn)程復(fù)用
- 在復(fù)雜進(jìn)程中添加、移除和替換子任務(wù)非常輕松,對(duì)已存在的進(jìn)程沒有任何影響,這就加大了該模式的擴(kuò)展性和靈活性
- 對(duì)于每個(gè)處理單元又可以打補(bǔ)丁,做監(jiān)聽。(這就是切面編程了)
模式需要注意的東西
- Pipeline的深度:Pipeline 中 Pipe 的個(gè)數(shù)被稱作 Pipeline 的深度。所以我們?cè)谟?Pipeline 的深度與 JVM 宿主機(jī)的 CPU 個(gè)數(shù)間的關(guān)系。如果 Pipeline 實(shí)例所處的任務(wù)多屬于 CPU 密集型,那么深度最好不超過 Ncpu。如果 Pipeline 所處理的任務(wù)多屬于 I/O 密集型,那么 Pipeline 的深度最好不要超過 2*Ncpu。
- 基于線程池的 Pipe:如果 Pipe 實(shí)例使用線程池,由于有多個(gè) Pipe 實(shí)例,更容易出現(xiàn)線程死鎖的問題,需要仔細(xì)考慮。
- 錯(cuò)誤處理:Pipe 實(shí)例對(duì)其任務(wù)進(jìn)行過程中跑出的異常可能需要相應(yīng) Pipe 實(shí)例之外進(jìn)行處理。
- 此時(shí),處理方法通常有兩種:一是各個(gè) Pipe 實(shí)例捕獲到異常后調(diào)用 PipeContext 實(shí)例的 handleError 進(jìn)行錯(cuò)誤處理。另一個(gè)是創(chuàng)建一個(gè)專門負(fù)責(zé)錯(cuò)我處理的 Pipe 實(shí)例,其他 Pipe 實(shí)例捕獲異常后提交相關(guān)數(shù)據(jù)給該 Pipe 實(shí)例處理。
- 可配置的 Pipeline:Pipeline 模式可以用代碼的方式將若干個(gè) Pipe 實(shí)例添加,也可以用配置文件的方式實(shí)現(xiàn)動(dòng)態(tài)方式添加 Pipe。
六、Java Function
如果,你的管道邏輯真的很簡(jiǎn)單,也直接用 Java8 提供的 Function 就,具體實(shí)現(xiàn)如下這樣
- File file = new File("/Users/apple/Documents/hello.txt");
- Function<File,String> readFile = input -> {
- System.out.println("===文件處理===");
- try{
- return FileUtils.readFileToString(input,"UTF-8");
- }catch (IOException e){
- e.printStackTrace();
- }
- return null;
- };
- Function<String, String> filterCharacter = input -> {
- System.out.println("===字符過濾===");
- List<String> hello = Stream.of(input).filter(s -> s.contains("hello")).collect(Collectors.toList());
- return String.join("",hello);
- };
- Function<String, String> reverseCharacter = input -> {
- System.out.println("===反轉(zhuǎn)字符串===");
- return new StringBuilder(input).reverse().toString();
- };
- final Function<File,String> pipe = readFile
- .andThen(filterCharacter)
- .andThen(reverseCharacter);
- System.out.println(pipe.apply(file));
最后
但是,并不是一碰到這種類似流式處理的任務(wù)就需要用管道,Pipeline 模式中各個(gè)處理階段所用的工作者線程或者線程池,表示各個(gè)階段的輸入/輸出對(duì)象的創(chuàng)建和一定(進(jìn)出隊(duì)列)都有其自身的時(shí)間和空間開銷,所以使用 Pipeline 模式的時(shí)候需要考慮它所付出的代價(jià)。建議處理規(guī)模較大的任務(wù),否則可能得不償失。
參考
https://java-design-patterns.com/patterns/pipeline/
https://developer.aliyun.com/article/778865
https://yasinshaw.com/articles/108
《Java多線程編程實(shí)戰(zhàn)指南(設(shè)計(jì)模式篇)》






















