零基礎科普:4種簡單推薦算法背后的原理
本文轉載自微信公眾號「大數據DT」,作者李智慧。轉載本文請聯系大數據DT公眾號。
大數據平臺只是提供了數據獲取、存儲、計算、應用的技術方案,真正挖掘這些數據之間的關系讓數據發揮價值的是各種機器學習算法。在這些算法中,最常見的當屬智能推薦算法了。下面通過幾種簡單的推薦算法來了解一下推薦算法背后的原理。
我們在淘寶購物,在頭條閱讀新聞,在抖音刷短視頻,背后其實都有智能推薦算法。這些算法不斷分析、計算我們的購物偏好、瀏覽習慣,然后為我們推薦可能喜歡的商品、文章、視頻。這些產品的推薦算法如此智能、高效,以至于我們常常一打開淘寶就買個不停,一打開抖音就停不下來。
01 基于人口統計的推薦
基于人口統計的推薦是相對簡單的一種推薦算法,它會根據用戶的基本信息進行分類,然后將商品推薦給同類用戶,如圖1所示。
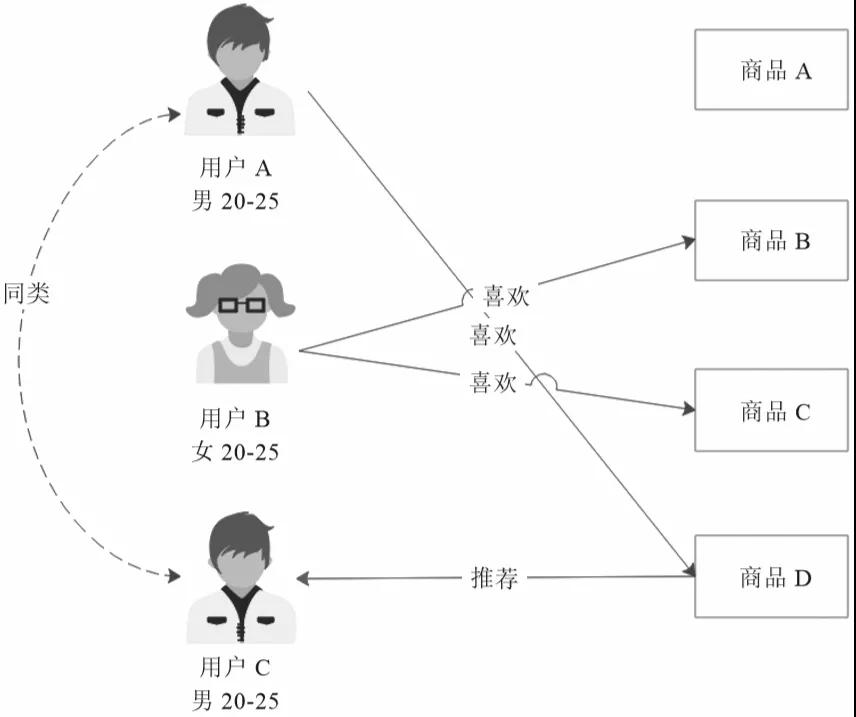
▲圖1 基于人口統計的推薦算法
用戶A和用戶C的年齡相近、性別相同,可以將他們劃分為同類。用戶A喜歡商品D,因此推測用戶C可能也喜歡這個商品,系統就可以將這個商品推薦給用戶C。
圖1中的示例比較簡單,在實踐中,還應該根據用戶收入、居住地區、學歷、職業等各種因素對用戶進行分類,以使推薦的商品更加準確。
02 基于商品屬性的推薦
基于商品屬性的推薦和基于人口統計的推薦相似,只是它是根據商品的屬性進行分類,然后根據商品分類進行推薦的,如圖2所示。
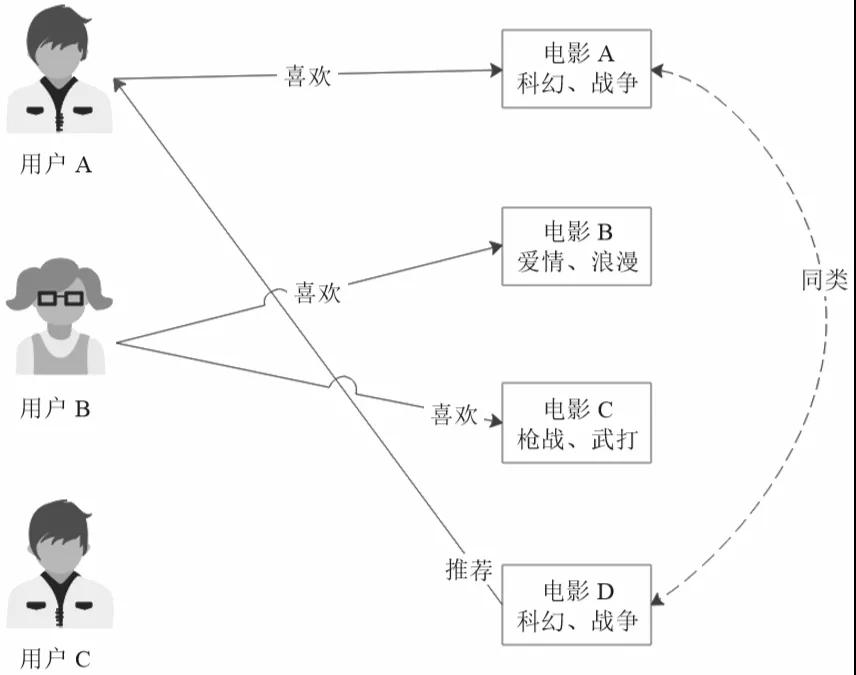
▲圖2 基于商品屬性的推薦
電影A和電影D都是科幻、戰爭類型的電影,如果用戶A喜歡電影A,很有可能他也會喜歡電影D,因此就可以給用戶A推薦電影D。
這和我們的生活常識也是相符合的。如果一個人連續看了幾篇關于籃球的新聞,那么再給他推薦一篇籃球的新聞,他很大可能會有興趣看。
03 基于用戶的協同過濾推薦
基于用戶的協同過濾推薦是根據用戶的喜好進行用戶分類,然后根據用戶分類進行推薦,如圖3所示。
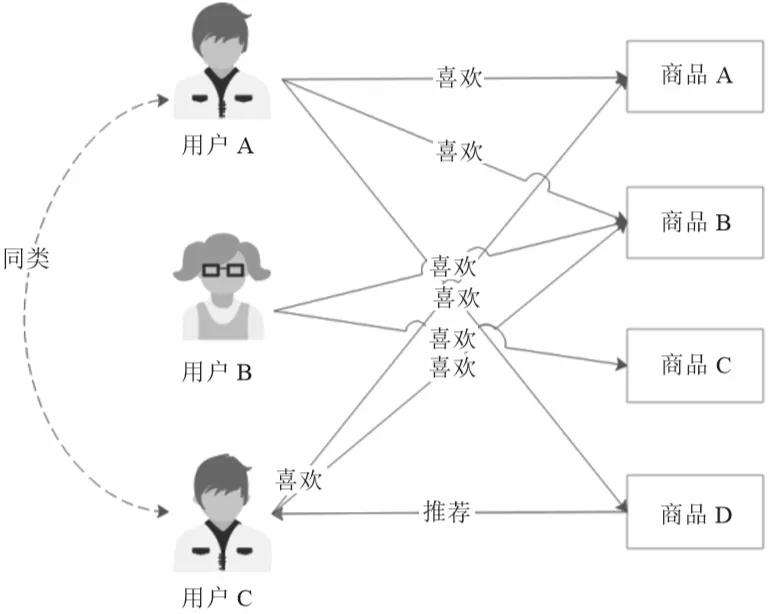
▲圖3 基于用戶的協同過濾推薦
這個示例中,用戶A和用戶C都喜歡商品A和商品B,根據他們的喜好可以分為同類。用戶A還喜歡商品D,那么將商品D推薦給用戶C,他可能也會喜歡。
現實中,跟我們有相似喜好、品味的人也常常被我們當作同類,我們也愿意去嘗試他們喜歡的其他東西。
04 基于商品的協同過濾推薦
基于商品的協同過濾推薦則是根據用戶的喜好對商品進行分類,然后根據商品分類進行推薦,如圖4所示。
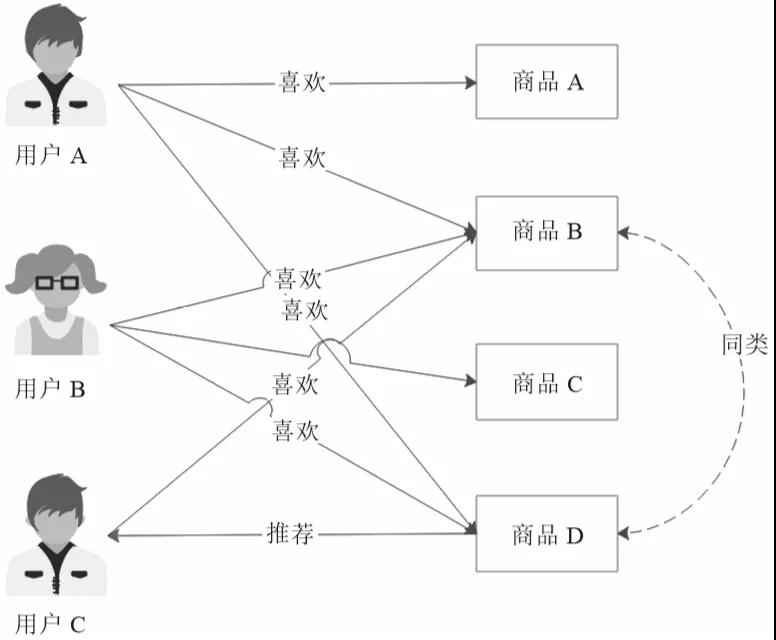
▲圖4 基于商品的協同過濾推薦
這個示例中,喜歡商品B的用戶A和用戶B都喜歡商品D,那么商品B和商品D就可以分為同類。對于同樣喜歡商品B的用戶C,很有可能也喜歡商品D,就可以將商品D推薦給用戶C。
這里描述的推薦算法比較簡單。事實上,要想做好推薦其實是非常難的,用戶不要你覺得他喜歡,而要自己覺得喜歡。現實中,有很多智能推薦的效果并不好,被用戶吐槽是“人工智障”。推薦算法的優化需要不斷地收集用戶的反饋,不斷地迭代算法和升級數據。
關于作者:李智慧,資深架構專家,同程旅行交通首席架構師,曾在NEC、阿里巴巴、Intel等知名企業擔任架構師,也曾在WiFi萬能鑰匙等企業擔任CTO。長期從事大數據、大型網站的架構和研發工作,領導設計過多個日活用戶在千萬級以上的互聯網系統架構,實戰經驗豐富。曾設計、開發過 Web 服務器防火墻、分布式NoSQL 系統、大數據倉庫引擎、反應式編程框架等各種類型的軟件系統。
本文摘編自《架構師的自我修煉:技術、架構和未來》,經出版方授權發布。